통사론
DF [ ( cond_1 ) & ( 조건_2 ) ]실시예 01
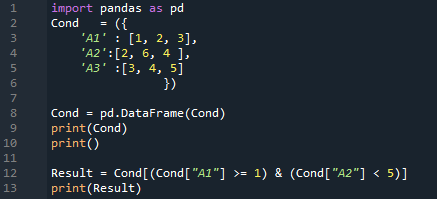
'Spyder' 앱에서 이 코드를 수행하고 여기 'pandas'의 조건에서 'AND' 연산자를 사용합니다. 우리는 pandas 코드를 수행하기 때문에 먼저 'pandas as pd'를 가져와야 하고 코드에 'pd'만 넣어 메서드를 얻을 것입니다. 그런 다음 이름이 'Cond'인 사전을 생성하고 여기에 삽입한 데이터는 'A1', 'A2' 및 'A3'이 열 이름이고 '1, 2, 3'을 ' A1', 'A2'에는 '2, 6, 4'가 있고 마지막 'A3'에는 '3, 4, 5'가 있습니다.
그런 다음 여기에서 'pd.DataFrame'을 활용하여 이 사전의 DataFrame을 만들기 위해 이동합니다. 이것은 위의 사전 데이터의 DataFrame을 반환합니다. 여기에 “print()”를 주어서 렌더링하기도 하고, 그 후 몇가지 조건을 적용하고 이 조건에서 “&” 연산자도 활용합니다. 여기서 첫 번째 조건은 'A1 >= 1'이고 '&' 연산자를 넣고 'A2 < 5'인 또 다른 조건을 배치합니다. 이것을 실행하면 'A1 >=1'이고 'A2 < 5'인 경우 결과를 반환합니다. 여기에서 두 조건이 모두 충족되면 결과를 표시하고, 여기에서 어느 하나라도 충족되지 않으면 데이터를 표시하지 않습니다.
DataFrame의 'A1' 열과 'A2' 열을 모두 확인한 다음 결과를 반환합니다. “print()” 구문을 사용하기 때문에 결과가 화면에 표시됩니다.
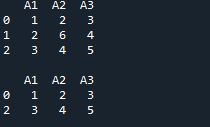
결과는 여기에 있습니다. DataFrame에 삽입한 모든 데이터를 표시한 다음 두 조건을 모두 확인합니다. 'A1 >=1' 및 'A2 < 5'인 행을 반환합니다. 두 개의 행에서 두 조건이 모두 충족되기 때문에 이 출력에서 두 개의 행을 얻습니다.
실시예 02
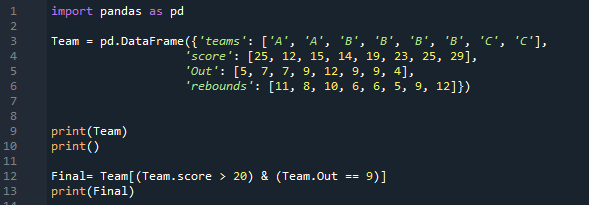
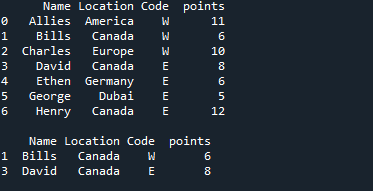
이 예제에서는 'pandas as pd'를 가져온 후 DataFrame을 직접 생성합니다. 4개의 열이 포함된 데이터와 함께 '팀' DataFrame이 여기에서 생성됩니다. 첫 번째 열은 'A, A, B, B, B, B, C, C'를 입력한 '팀' 열입니다. 그런 다음 '팀' 옆의 열은 '점수'이며 '25, 12, 15, 14, 19, 23, 25, 29'를 삽입합니다. 그 후, 우리가 가진 열은 'Out'이고 '5, 7, 7, 9, 12, 9, 9 및 4'로 데이터를 추가합니다. 여기서 마지막 열은 '11, 8, 10, 6, 6, 5, 9, 12'와 같은 일부 숫자 데이터도 포함하는 '리바운드' 열입니다.
여기에서 DataFrame이 완료되었으며 이제 이 DataFrame을 인쇄해야 하므로 여기에 'print()'를 배치합니다. 이 DataFrame에서 특정 데이터를 가져오기를 원하므로 여기에 몇 가지 조건을 설정합니다. 여기에 두 가지 조건이 있고 이 조건 사이에 'AND' 연산자를 추가하여 두 조건을 모두 충족하는 조건만 반환합니다. 여기에 추가한 첫 번째 조건은 '점수 > 20'이고 '&' 연산자와 'Out == 9'인 다른 조건을 배치합니다.
따라서 팀의 점수가 20 미만이고 아웃도 9인 데이터를 필터링합니다. 해당 데이터를 필터링하고 나머지 조건을 무시하므로 두 조건 또는 둘 중 하나를 충족하지 않습니다. 또한 두 조건을 모두 만족하는 데이터를 표시하므로 'print()' 방법을 사용했습니다.
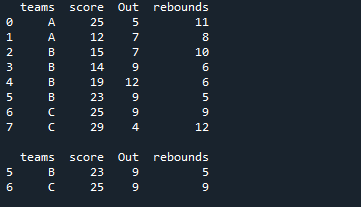
두 개의 행만 이 DataFrame에 적용한 두 조건을 모두 충족합니다. 점수가 20보다 크며 아웃이 9인 행만 필터링하여 여기에 표시합니다.
실시예 03
위의 코드에서는 숫자 데이터를 DataFrame에 삽입하기만 하면 됩니다. 이제 이 코드에 일부 문자열 데이터를 넣습니다. 'pandas as pd'를 가져온 후 'Member' DataFrame을 빌드하기 위해 이동합니다. 여기에는 4개의 고유한 열이 있습니다. 여기서 첫 번째 열의 이름은 '이름'이고 'Allies, Bills, Charles, David, Ethen, George, Henry'인 멤버의 이름을 삽입합니다. 다음 열의 이름은 여기에서 'Location'이고 'America'가 있습니다. 캐나다, 유럽, 캐나다, 독일, 두바이, 캐나다'라고 명시되어 있습니다. '코드' 열에는 'W, W, W, E, E, E, E'가 포함됩니다. 여기에 멤버들의 '포인트'도 '11, 6, 10, 8, 6, 5, 12'로 추가합니다. 'print()' 메서드를 사용하여 'Member' DataFrame을 렌더링합니다. 이 DataFrame에 몇 가지 조건을 지정했습니다.
여기에는 두 개의 조건이 있으며 그 사이에 'AND' 연산자를 추가하면 두 조건을 모두 만족하는 조건만 반환됩니다. 여기에서 우리가 도입한 첫 번째 조건은 'Location == Canada'이고 그 뒤에 '&' 연산자가 따르고 두 번째 조건은 'points <= 9'입니다. 두 조건을 모두 만족하는 DataFrame에서 해당 데이터를 가져온 다음 두 조건이 모두 참인 데이터를 표시하는 'print()'를 배치했습니다.
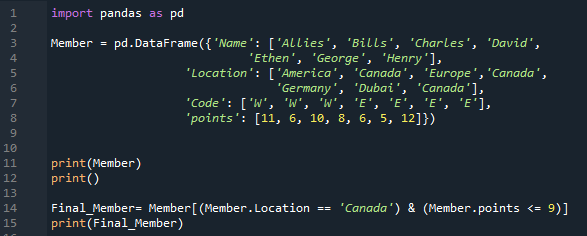
아래에서 DataFrame에서 두 개의 행이 추출되어 표시되는 것을 알 수 있습니다. 두 행 모두에서 위치는 '캐나다'이고 포인트는 9보다 작습니다.
실시예 04
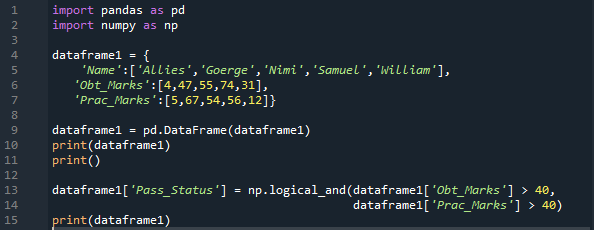
여기서 'pandas'와 'numpy'를 각각 'pd'와 'np'로 가져옵니다. 'pd'를 배치하여 'pandas' 메소드를 얻고 필요한 곳에 'np'를 배치하여 'numpy' 메소드를 얻습니다. 그런 다음 여기에서 만든 사전에는 세 개의 열이 있습니다. '이름' 열에 'Allies, George, Nimi, Samuel, and William'을 삽입합니다. 다음으로, 학생들의 획득 점수가 포함된 'Obt_Marks' 열이 있으며 해당 점수는 '4, 47, 55, 74 및 31'입니다.
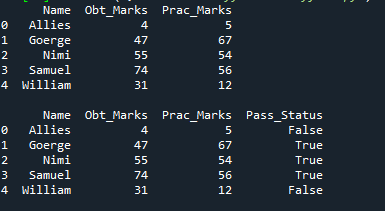
여기에 학생의 실제 점수가 있는 'Prac_Marks'에 대한 열도 만듭니다. 여기에 추가한 마크는 '5, 67, 54, 56, 12'입니다. 이 사전의 DataFrame을 만든 다음 인쇄합니다. 여기에 'np.Logical_and'를 적용하면 결과가 'True' 또는 'False' 형식으로 반환됩니다. 또한 여기에서 'Pass_Status'라는 이름으로 만든 새 열에 두 조건을 모두 확인한 후 결과를 저장합니다.
'Obt_Marks'가 '40'보다 크고 'Prac_Marks'가 '40'보다 큰지 확인합니다. 둘 다 true이면 새 열에서 true로 렌더링됩니다. 그렇지 않으면 false로 렌더링됩니다.
'Pass_Status'라는 이름으로 새 열이 추가되며 이 열은 'True'와 'False'로만 구성됩니다. 얻은 점수와 실제 점수가 40보다 크면 true를 렌더링하고 나머지 행은 false로 렌더링합니다.
결론
이 튜토리얼의 주요 목표는 'pandas'에서 'and condition'의 개념을 설명하는 것입니다. 우리는 두 조건이 모두 충족되는 행을 얻는 방법에 대해 이야기하거나 모든 조건이 만족되는 행에 대해 true를 얻고 나머지에 대해 false를 얻습니다. 여기에서 네 가지 예를 살펴보았습니다. 이 자습서에서 설정한 네 가지 예는 모두 이 프로세스를 거쳤습니다. 이 자습서의 예제는 모두 사용자의 이익을 위해 신중하게 제시되었습니다. 이 튜토리얼은 이 아이디어를 더 명확하게 이해하는 데 도움이 될 것입니다.