'Pandas'는 파이썬 환경을 위한 고성능 도구입니다. 데이터 분석을 위한 '오픈' 소스 코드입니다. pandas 조인 및 pandas 병합 방법은 두 데이터 프레임을 단일 데이터 프레임으로 결합하는 데 사용됩니다. pandas의 두 방법 모두에서 차이점은 pandas 'join' 함수가 인덱스를 사용하여 데이터 프레임을 조인한다는 것입니다. pandas '병합' 기능은 인덱스와 원하는 열을 직접 선택할 수 있는 열 메서드를 사용하여 데이터 프레임을 조인합니다. pandas의 merge 방법은 pandas의 join 방법과 비교하여 주로 사용됩니다. 구현에 사용할 소프트웨어는 pandas join method() 및 pandas merge() 메서드 함수의 코드 구현에 대한 이점을 제공하는 Python 환경에 있는 'spyder' 소프트웨어입니다.
Pandas Join() 메서드의 구문
'df1. 가입하다 ( df2 ) '위 구문에서 'df'는 'dataframe'의 약어입니다. 메서드를 호출하기 위한 '도트 조인' 기능이 있는 구문에는 두 개의 데이터 프레임이 있습니다. 두 데이터 프레임을 결합하는 pandas 방법입니다. 인덱스를 사용하여 데이터 프레임을 하나의 데이터 프레임으로 결합하여 작동합니다.
Pandas Merge() 메서드의 구문
'df1. 병합 ( df2 , ~에 = 'column_name' ) 'pandas 병합 메서드 구문에는 'df1'과 'df2'라는 두 개의 데이터 프레임이 있습니다. '도트 병합' 기능은 열 모양이 반전된 두 데이터 프레임을 결합하는 방법을 호출합니다.
판다 병합 및 판다 결합 방법을 사용하기 위해 두 데이터 프레임을 결합하는 다음 방법을 다룰 것입니다.
- Pandas Join 메서드가 겹칩니다.
- Pandas는 인덱스 재설정을 사용하여 메서드에 조인합니다.
- Pandas 병합 방법(열 '왼쪽 및 오른쪽').
- 팬더 병합 방법이 명시적입니다.
Pandas Merge 및 Pandas Join 메서드 구현을 위한 데이터 프레임 만들기
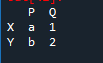
먼저 데이터 프레임을 만들어야 합니다. 이를 위해 '스파이더' 도구를 사용할 것입니다. 그것을 연 후 코드 작성을 시작하십시오. 팬더 라이브러리 협회를 위해 'pd'로 팬더를 가져옵니다. 데이터 프레임 변수는 'x', 'y', 'p' 및 'q'가 있고 값 '1'과 'b'가 있는 'a'는 값이 '2'로 할당되어 있습니다.

출력은 할당된 값으로 생성된 'df'입니다. 데이터만큼 크게 만들 수 있습니다.
다른 데이터 프레임 생성
pandas 결합 및 pandas 병합 방법을 명확하게 이해하려면 다른 데이터 프레임을 만들어야 합니다. 여기에서 우리는 위의 'df'와 동일하게 'df'를 생성했으며, 할당된 값만 다를 뿐입니다. 'h', 'j', 's' 및 'd'가 있는 반면 값 '8'로 값 'b'를 할당하고 값 '3'으로 'Y'를 할당합니다.

출력은 생성된 간단한 'df'를 보여줍니다.

예제 # 01: Pandas Join 메서드(중첩)
이제 pandas 조인 방법으로 두 데이터 프레임을 조인하는 방법을 살펴보겠습니다. 이 방법의 경우 데이터 프레임에서 작업하려는 열을 선택할 수 있습니다. 'df'에서 겹치는 열 'left'가 있는 예를 가져왔으므로 '접미사'로 이를 수정하여 데이터 겹치는 것을 극복할 수 있습니다. 여기서 사용된 변수는 'x', 'z', 'v', 'd'입니다. 'p', 'o', 'l' 및 'y' 값이 '3', '6', '7' 및 '9'로 할당됩니다. '.join'은 오른쪽 'df' 접미사를 사용하여 왼쪽 조인으로 설정한 정렬을 사용하여 메서드를 호출합니다. '. 코드에 사용된 '접미사'는 데이터 프레임에 '키'라는 동일한 이름을 갖고 데이터와 겹치지 않는 두 개의 열이 있기 때문입니다.
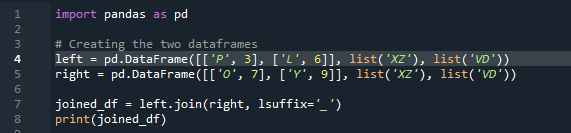
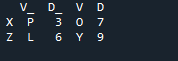
pandas 조인 방법을 사용하여 두 개의 'df'를 조인하는 방법으로 출력에 겹치는 데이터가 표시되지 않습니다.
예제 # 02: 인덱스 재설정을 사용하는 Pandas 조인 방법
이 예에서는 두 데이터 프레임을 조인하는 데 도움이 되는 조인 메서드에서 '키'로 사용할 'on' 매개변수가 있는 열을 별도로 지정합니다. 결합된 작업은 이 매개변수로 수행됩니다. 또한 두 'df' 중 하나의 인덱스는 조인하기 위해 유사해야 합니다. 유사한 종류의 데이터 또는 동일한 목적으로 사용되는 데이터를 함께 처리할 수 있습니다. 이것은 오른쪽에서 사용하여 인덱스를 계속 사용합니다. 변수는 's', 't', 'u', 'v', 'n', 'w', 'k' 및 'q'입니다. 할당된 값은 '3', '6', '7' 및 '9'입니다. 'reset dot index'는 pandas가 'df'의 인덱스를 재설정하는 방법입니다. 재설정 인덱스는 데이터 프레임 데이터가 길어질 때까지 데이터 프레임 목록의 모든 정수를 0에서 설정합니다.
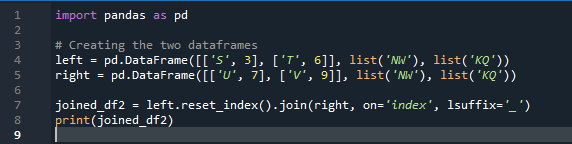
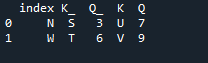
다음은 pandas의 인덱스 'key' 조인 방법으로 표시되는 출력입니다.
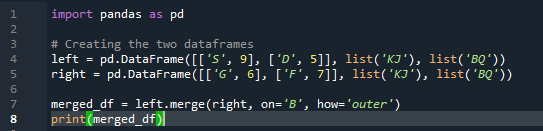
예제 # 03: Pandas 병합 방법(열 '왼쪽 및 오른쪽')
병합 방법은 팬더 조인 방법과 유사한 작업을 수행합니다. 두 방법 모두 유사한 데이터 프레임의 데이터를 결합하기 위한 것입니다. 병합 방법은 키를 지정해야 하는 다용도입니다. 데이터 프레임의 작업에 따라 왼쪽 및 오른쪽 열에 지정할 수도 있습니다. 코드의 변수는 's', 'd', 'g', 'f', 'k', 'j', 'b' 및 'q'입니다. 할당된 값은 '9', '5', '6' 및 '7'입니다. 외부 '조인' 구현은 pandas 병합 메서드 함수의 'how' 매개변수를 사용하여 두 'df'에서 모두 수행됩니다.
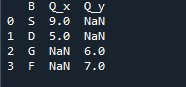
우리가 보는 출력은 두 데이터 프레임의 병합된 데이터를 보여줍니다. 'NaN'은 '숫자가 아님'을 나타내며 'NaN'이 표시하는 데이터에 할당된 숫자가 없음을 의미합니다.
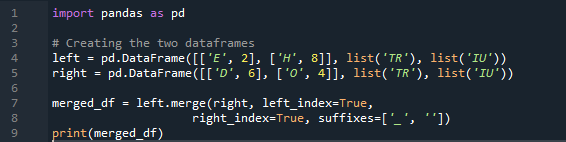
예제 # 04: 명시적으로 병합 방법
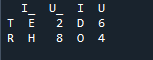
여기서, 이 예에서 병합 방법은 인덱스의 파괴이며 인덱스 값은 데이터 프레임에서 가정하지 않습니다. 명시적으로 지정하는 것이 후속 조치인 경우 수행해야 하는 작업에 따라 이 방법을 수행합니다. 왼쪽 인덱스 또는 오른쪽 인덱스를 기준으로 데이터를 매개변수와 병합합니다. 이 데이터 프레임의 변수는 't', 'r', 'I', 'u', 'h', 'o', 'e' 및 'e'입니다. 할당된 값은 '2', '4', '6' 및 '4'입니다. 위의 판다 병합 방법과 필요에 따른 열 선택의 예는 두 데이터 프레임을 결합하는 가장 현명하고 가치 있는 방법입니다. 데이터 세트에서 고유한 병합 키에 대해 코드 줄 끝에서 확인합니다.
아래 출력에서 인덱스가 없으면 인덱스가 표시되지 않지만 오른쪽 및 왼쪽 인덱스를 기준으로 기능이 수행됩니다.
결론
merge() 및 join() 메서드는 모두 매우 편리하고 효과적인 메서드입니다. 이 두 함수는 동일한 데이터 프레임에서 두 개의 개별 데이터 프레임을 결합하는 데 사용되지만 경우에 따라 용도가 다릅니다. 이 기사에서는 pandas 조인과 병합 방법의 주요 차이점을 배웠습니다. 예제를 수행하고 pandas 조인 방법을 이해한 후 더 유연하고 데이터베이스 스타일의 조인을 원할 경우 pandas 병합 방법을 사용하는 것이 바람직하다는 지식으로 결론을 맺습니다. 반면에 인덱스와 데이터 프레임을 광범위하게 결합하려는 경우 pandas join() 메서드 함수를 사용할 수 있습니다.