확장성
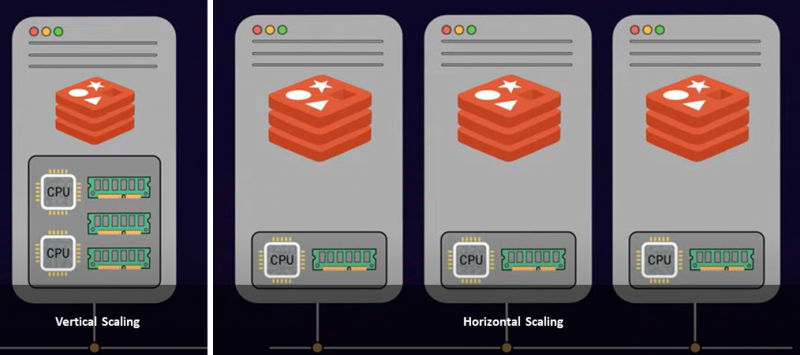
서버 확장에는 수직 확장과 수평 확장의 두 가지 일반적인 접근 방식이 있습니다. 수직 확장 또는 수직 확장은 더 많은 CPU, 메모리 및 스토리지와 같이 비용이 많이 드는 서버에 더 많은 전력과 리소스를 추가하는 것입니다. 반면에 수평 확장은 기존 리소스 풀에 여러 노드를 추가하는 것입니다. 이를 스케일 아웃이라고 합니다. 따라서 제한 사항과 요구 사항에 따라 더 큰 단일 서버 인스턴스를 보유하거나 여러 서버 노드를 배포하는 것은 사용자의 몫입니다.
100GB의 RAM이 있고 200GB의 데이터를 보관해야 한다고 가정합니다. 이 경우 두 가지 선택이 있습니다.
- 시스템에 더 많은 RAM을 추가하여 확장
- 100GB RAM이 있는 다른 서버 인스턴스를 추가하여 확장
인프라 내에서 최대 RAM 제한에 도달한 경우 확장이 이상적인 접근 방식입니다. 또한 확장하면 데이터베이스 처리량이 크게 증가합니다.
레디스 샤딩
Redis가 단일 스레드에서 작동한다는 것은 알려진 사실입니다. 따라서 Redis는 서버 CPU의 여러 코어를 활용하여 명령을 처리할 수 없습니다. 따라서 더 많은 CPU 코어를 추가해도 Redis에서 많은 처리량이나 성능을 제공하지 않습니다. 여러 서버 인스턴스 간에 데이터를 분할하는 경우에는 해당되지 않습니다. 여러 서버를 추가하고 그 사이에 데이터 세트를 분산하면 클라이언트 요청을 병렬로 처리할 수 있어 처리량이 증가합니다. 또한 전체 성능이 선형에 가깝게 증가할 수 있습니다.
확장을 염두에 두고 여러 서버 간에 데이터를 분할하거나 배포하는 이러한 접근 방식을 호출합니다. 샤딩 . 데이터의 일부를 저장하는 모든 서버를 호출합니다. 파편 .
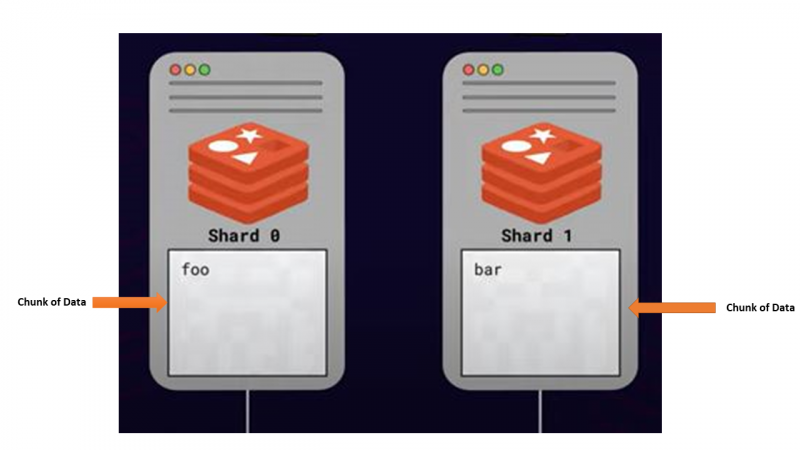
샤딩 수행 방법 — 알고리즘 샤딩
샤딩의 주요 관심사 중 하나는 여러 Redis 노드에서 주어진 키를 찾는 방법이었습니다. 지정된 키는 사용 가능한 모든 샤드에 저장될 수 있으므로 특정 키를 찾기 위해 모든 샤드를 쿼리하는 것은 최선의 선택이 아닙니다. 따라서 각 키를 특정 샤드에 매핑하는 방법이 있어야 하며 Redis는 알고리즘 샤딩 전략을 사용합니다.
가장 일반적인 접근 방식은 Redis 키 이름과 모듈로를 사용하여 해시 값을 계산하는 것입니다. 그런 다음 시스템에서 사용 가능한 Redis 샤드로 나눕니다.
HASH_SLOT = CRC16(키) 모드 16384총 샤드 수가 일정하다면 상당히 좋은 솔루션입니다. 새로운 Reids 서버 인스턴스를 추가할 때마다 총 샤드 수가 증가했기 때문에 주어진 키에 대한 결과 값이 변경될 수 있습니다. 결국 잘못된 Redis 샤드를 쿼리하게 됩니다. 따라서 각 키에 대한 새 샤드를 계산하고 데이터를 올바른 서버로 전송하여 리샤딩 프로세스를 따라야 합니다. 이는 번거롭고 총 샤드 수가 수시로 증가하는 경우 사소한 작업이 아닙니다.
Redis는 해시 슬롯 이 문제를 방지하기 위해. 주어진 샤드에 대해 여러 해시 슬롯을 사용할 수 있으며 단일 해시 슬롯은 여러 Redis 키를 보유할 수 있습니다. Redis 데이터베이스 클러스터에는 변경되지 않은 16384개의 해시 슬롯이 있습니다. 모듈로 분할은 샤드 수가 아닌 해시 슬롯 수로 수행됩니다. 샤드 수가 증가한 경우에도 지정된 키에 대한 해시 슬롯의 올바른 위치를 제공합니다. 요구 사항에 따라 여러 Redis 인스턴스 간에 데이터를 분할하는 새 샤드로 해시 슬롯을 이동하여 리샤딩 프로세스를 간소화합니다.
Redis 샤딩의 이점
Redis 샤딩은 최소한의 변경으로 데이터베이스 시스템에 여러 가지 이점을 제공합니다.
높은 처리량
Redis는 단일 스레드이므로 여러 클라이언트 요청을 처리하는 것은 여러 CPU 코어를 사용하여 병렬로 처리할 수 없습니다. 따라서 새 샤드 또는 서버 인스턴스를 추가하면 Redis 작업을 병렬로 수행할 수 있습니다. Redis 데이터베이스에서 초당 작업을 증가시켜 궁극적으로 높은 처리량을 제공합니다.
고가용성
샤딩 접근 방식을 통해 Redis 클러스터는 고가용성과 내구성을 보장하는 마스터 복제 아키텍처를 설정할 수 있습니다.
복제본 읽기
샤딩을 사용하면 데이터의 정확한 복사본을 유지하고 별도의 Redis 인스턴스를 통해 읽기 작업을 제공하여 읽기 쿼리 실행 성능을 높일 수 있습니다.
이러한 이점 외에도 샤딩은 Redis 클러스터에 짝수의 샤드가 있는 경우 분할 브레인 상황을 유발할 수 있습니다. 따라서 Redis 클러스터에 홀수 개의 샤드를 유지하는 것이 좋습니다.
결론
요약하면 Redis 샤딩은 데이터를 여러 서버로 분할하여 데이터베이스의 확장성과 높은 처리량을 가능하게 합니다. 논의한 바와 같이 Redis는 알고리즘 샤딩 전략을 사용하여 클라이언트 요청을 올바른 샤드로 지정합니다. 총 샤드 수가 증가하면 몇 가지 단점이 있습니다. 따라서 총 샤드 수 대신 Redis는 해시 슬롯 수를 사용하여 적절한 샤드를 계산합니다. 샤딩이 도입되면서 Redis 데이터베이스는 고가용성, 높은 처리량 및 고성능을 제공합니다.