이 가이드에서는 크롤러를 생성하여 S3 버킷에서 데이터를 가져오는 방법을 설명합니다.
S3 버킷에서 데이터를 가져오기 위해 크롤러를 생성하는 방법은 무엇입니까?
AWS에서 크롤러를 생성하려면 ' AWS 글루 ” Amazon 대시보드의 서비스:
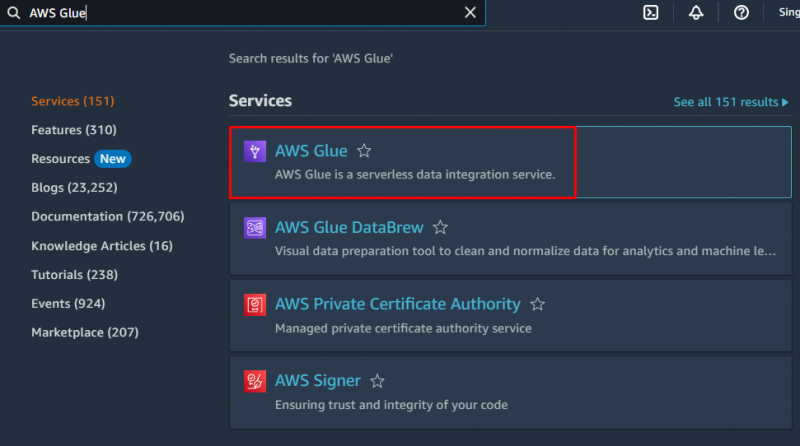
'를 클릭합니다. 데이터베이스 ” 버튼을 클릭하여 데이터베이스를 생성합니다.
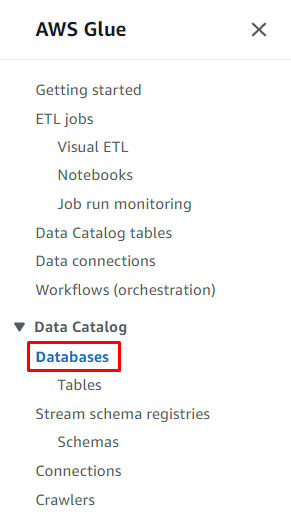
'를 클릭합니다. 데이터베이스 추가 ” 버튼을 눌러 구성을 시작합니다.
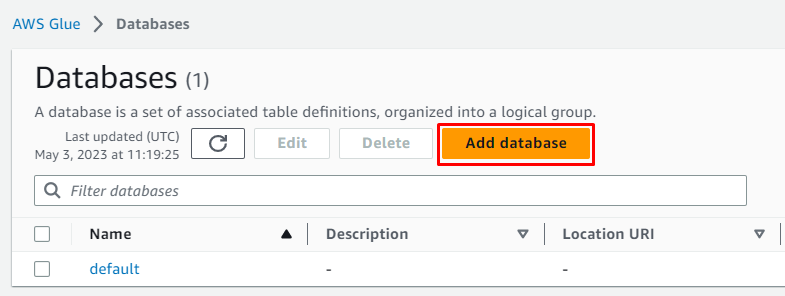
데이터베이스 이름을 입력하고 ' 데이터베이스 생성 ” 버튼:
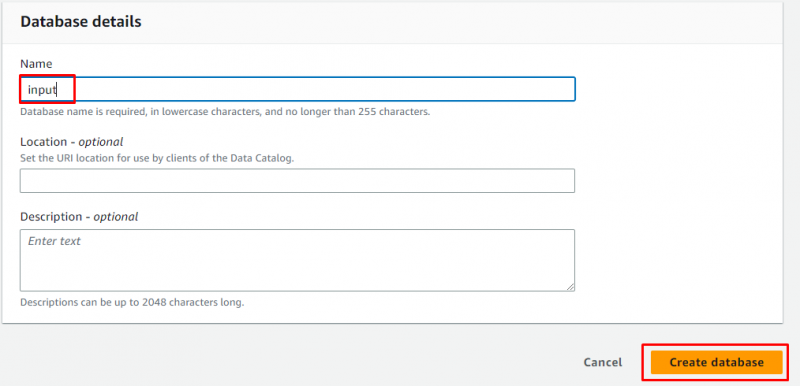
데이터베이스가 성공적으로 생성되었습니다:
그런 다음 ' 겉옷 ” 페이지 왼쪽 패널에서 클릭하여:
'를 클릭합니다. 크롤러 만들기 ” 버튼:

크롤러의 이름을 입력하고 ' 다음 ” 버튼:

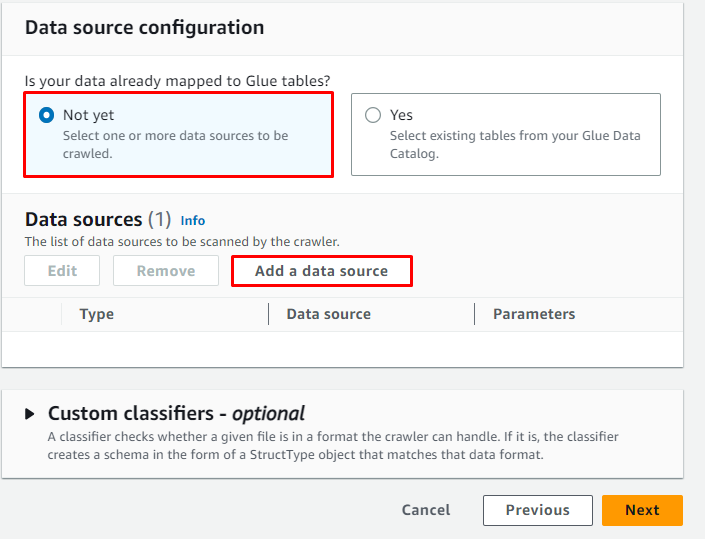
'를 클릭합니다. 데이터 소스 추가 ” 버튼을 클릭하여 데이터 소스를 선택합니다.
데이터가 저장된 경로를 확인하려면 S3 서비스를 방문하십시오.
데이터가 업로드되는 S3 버킷으로 이동합니다. 사용자는 만들다 양동이와 업로드 AWS S3 대시보드의 데이터:

'를 클릭합니다. S3 찾아보기 ” 버튼을 클릭하여 데이터 경로를 선택합니다.
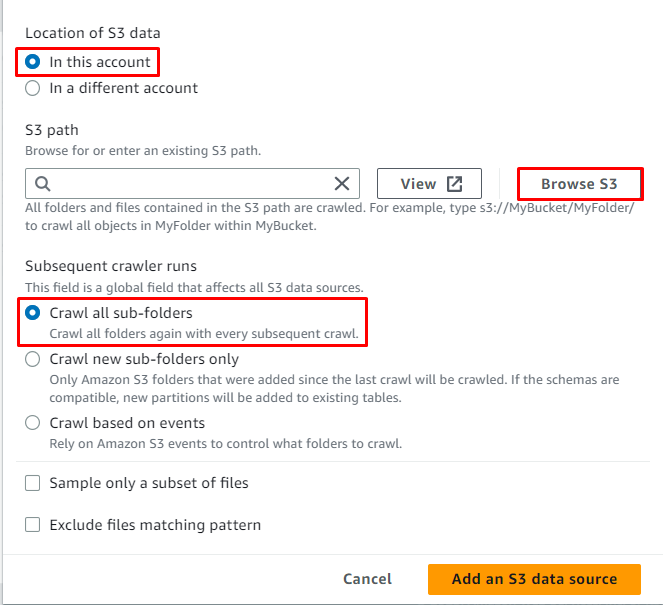
데이터가 포함된 폴더를 선택한 다음 ' 선택하다 ” 버튼:

S3 경로가 선택되었습니다. 이제 ' S3 데이터 소스 추가 ” 버튼:

데이터 소스가 추가되면 ' 다음 ” 버튼:
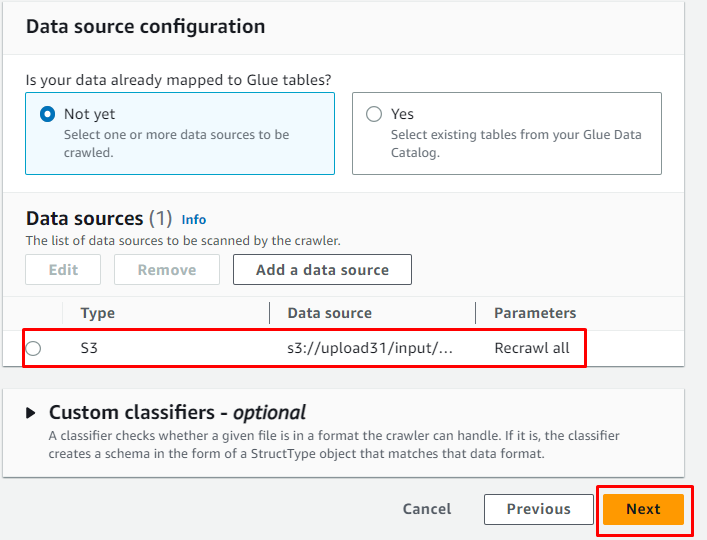
IAM 역할을 추가한 다음 ' 다음 ” 버튼:
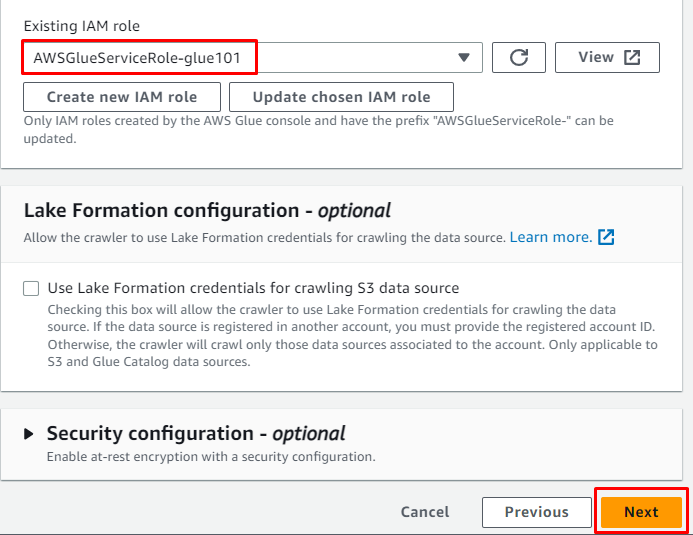
앞에서 만든 대상 데이터베이스를 입력한 다음 테이블 이름을 입력합니다.
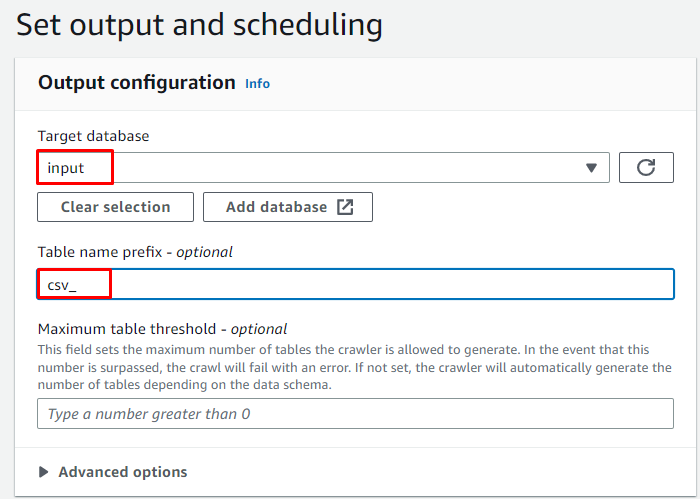
크롤러에 대한 주문형 일정을 선택하고 ' 다음 ” 버튼:
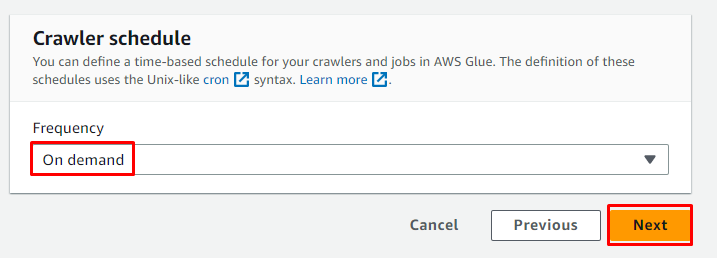
크롤러를 검토하고 ' 크롤러 만들기 ” 버튼:
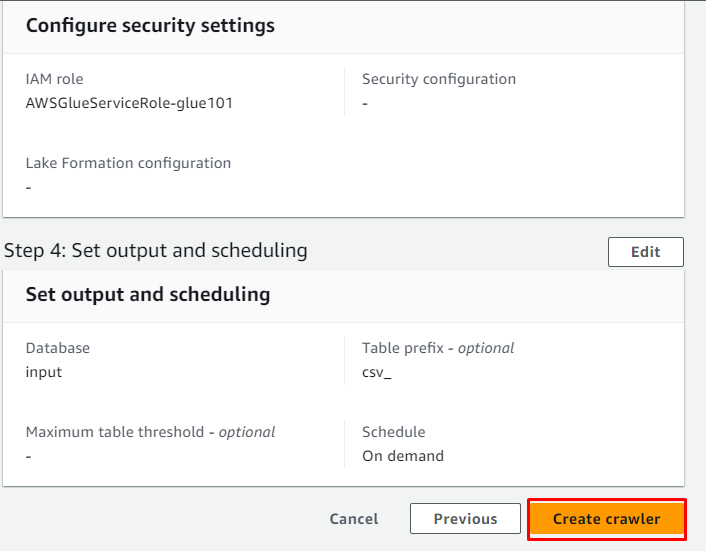
크롤러가 성공적으로 생성되었습니다. ' 달리다 ” 버튼을 선택한 후:

크롤러를 실행하는 데 몇 분이 걸리며 데이터를 가져오고 데이터를 저장할 테이블을 만듭니다.
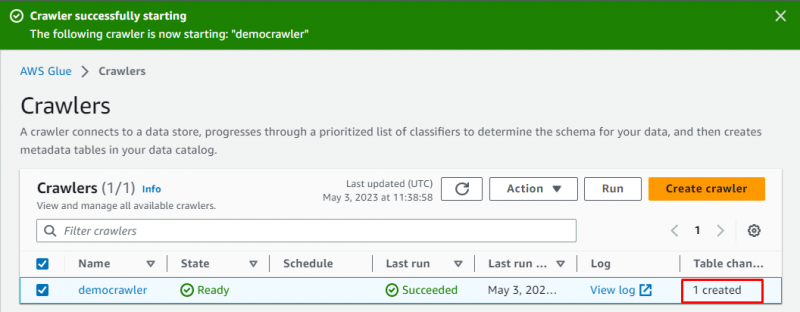
' 테이블 Glue 대시보드의 ” 페이지:
이름을 클릭하여 테이블을 선택합니다.
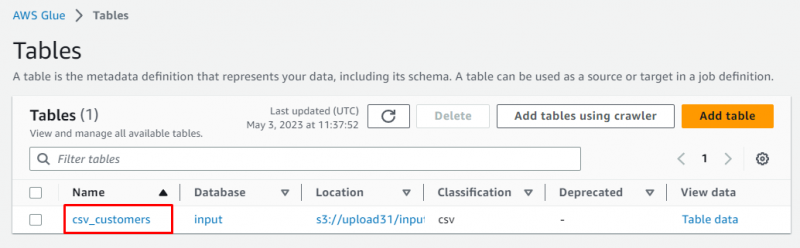
가져온 데이터의 메타데이터를 포함하는 이야기 세부 정보가 표시되었습니다.
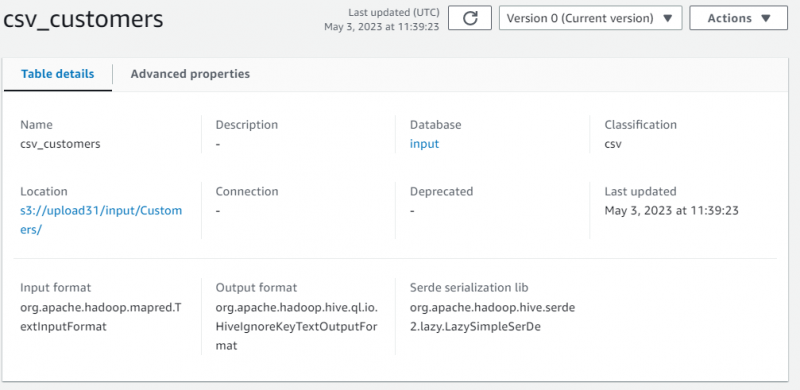
페이지를 아래로 스크롤하고 섹션을 선택하여 데이터가 포함된 테이블을 봅니다.
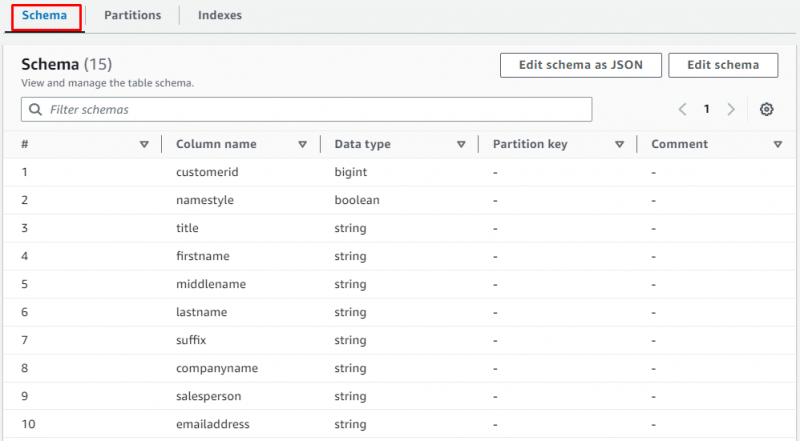
S3 버킷에서 데이터를 가져오는 크롤러를 생성하는 것이 전부입니다.
결론
S3 버킷에서 데이터를 가져오는 크롤러를 생성하려면 크롤링된 데이터가 저장될 AWS Glue에 데이터베이스를 생성합니다. 데이터 원본(S3 버킷) 및 대상 데이터베이스를 제공하여 Glue 대시보드에서 크롤러를 구성합니다. 크롤러를 실행하고 이 가이드에서 자세히 설명한 대로 S3 버킷에서 데이터베이스 테이블로 데이터를 가져옵니다.