예제 1: R에서 Order() 메서드를 사용하여 DataFrame 정렬
R의 order() 함수는 DataFrame을 하나 또는 여러 열로 정렬하는 데 사용됩니다. order 함수는 DataFrame의 행을 재정렬하기 위해 정렬된 행의 인덱스를 가져옵니다.
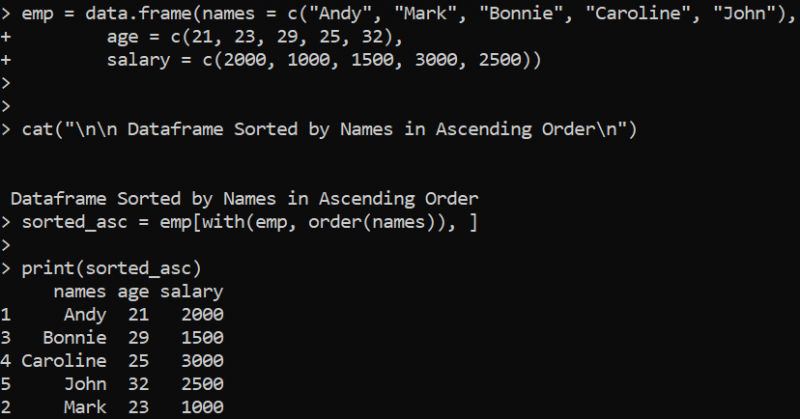
엠프 = 데이터. 액자 ( 이름 = 씨 ( '앤디' , '표시' , '보니' , '여자 이름' , '남자' ) ,나이 = 씨 ( 이십 일 , 23 , 29 , 25 , 32 ) ,
샐러리 = 씨 ( 2000년 , 1000 , 1500 , 3000 , 2500 ) )
고양이 ( ' \N \N 오름차순으로 이름별로 정렬된 데이터 프레임 \N ' )
sorted_asc = 엠프 [ ~와 함께 ( 엠프 , 주문하다 ( 이름 ) ) , ]
인쇄 ( sorted_asc )
여기에서 서로 다른 값을 포함하는 세 개의 열로 'emp' DataFrame을 정의합니다. cat() 함수는 'names' 열의 'emp' DataFrame을 오름차순으로 정렬할 것임을 나타내는 명령문을 인쇄하기 위해 배포됩니다. 이를 위해 오름차순으로 정렬된 벡터에서 값의 인덱스 위치를 반환하는 R의 order() 함수를 사용합니다. 이 경우 with() 함수는 'names' 열이 정렬되어야 함을 지정합니다. 정렬된 DataFrame은 정렬된 결과를 인쇄하기 위해 print() 함수에서 인수로 전달되는 'sorted_asc' 변수에 저장됩니다.
따라서 DataFrame의 'names' 열을 오름차순으로 정렬한 결과는 다음과 같이 표시됩니다. 내림차순으로 정렬 작업을 수행하려면 이전 order() 함수에서 열 이름으로 음수 부호를 지정하기만 하면 됩니다.
예제 2: R에서 Order() 메서드 매개 변수를 사용하여 DataFrame 정렬
또한 order() 함수는 감소하는 인수를 사용하여 DataFrame을 정렬합니다. 다음 예제에서는 오름차순 또는 내림차순으로 정렬할 인수가 있는 order() 함수를 지정합니다.
df = 데이터. 액자 (ID = 씨 ( 1 , 삼 , 4 , 5 , 2 ) ,
강의 = 씨 ( '파이썬' , '자바' , '씨++' , '몽고DB' , '아르 자형' ) )
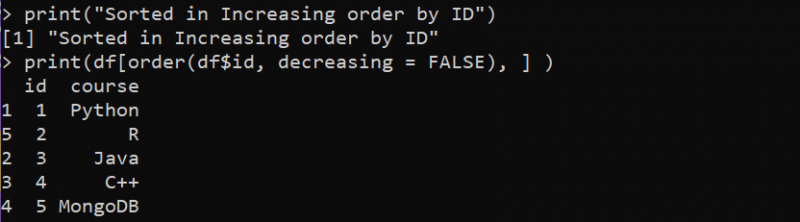
인쇄 ( 'ID별 내림차순으로 정렬' )
인쇄 ( df [ 주문하다 ( df$id , 감소 = 진실 ) , ] )
여기에서 먼저 data.frame() 함수가 세 개의 다른 열로 정의된 'df' 변수를 선언합니다. 다음으로, DataFrame이 'id' 열을 기준으로 내림차순으로 정렬될 것임을 나타내는 메시지를 인쇄하는 print() 함수를 사용합니다. 그런 다음 print() 함수를 다시 배포하여 정렬 작업을 수행하고 해당 결과를 인쇄합니다. print() 함수 내에서 'order' 함수를 호출하여 'course' 열을 기준으로 'df' DataFrame을 정렬합니다. 'decreasing' 인수는 TRUE로 설정되어 내림차순으로 정렬됩니다.
다음 그림에서 DataFrame의 'id' 열은 내림차순으로 정렬됩니다.

그러나 정렬 결과를 오름차순으로 얻으려면 다음과 같이 order() 함수의 감소 인수를 FALSE로 설정해야 합니다.
인쇄 ( 'ID별 오름차순 정렬' )인쇄 ( df [ 주문하다 ( df$id , 감소 = 거짓 ) , ] )
여기에서 'id' 열을 기준으로 오름차순으로 DataFrame의 정렬 작업 결과를 얻습니다.
예제 3: R에서 Arrange() 메서드를 사용하여 DataFrame 정렬
또한 배열() 메서드를 사용하여 DataFrame을 열별로 정렬할 수도 있습니다. 오름차순 또는 내림차순으로 정렬할 수도 있습니다. 다음 주어진 R 코드는 배열() 함수를 사용합니다.
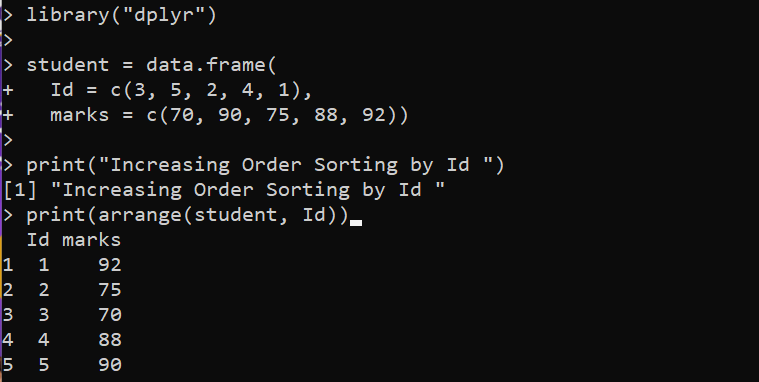
도서관 ( 'dplyr' )학생 = 데이터. 액자 (
ID = 씨 ( 삼 , 5 , 2 , 4 , 1 ) ,
점수 = 씨 ( 70 , 90 , 75 , 88 , 92 ) )
인쇄 ( 'ID별 주문 정렬 증가' )
인쇄 ( 마련하다 ( 학생 , ID ) )
여기에서 R의 'dplyr' 패키지를 로드하여 정렬을 위한 배열() 메서드에 액세스합니다. 그런 다음 두 개의 열을 포함하고 DataFrame을 'student' 변수로 설정하는 data.frame() 함수가 있습니다. 다음으로 주어진 DataFrame을 정렬하기 위해 print() 함수의 'dplyr' 패키지에서 배열() 함수를 배포합니다. 배열() 함수는 첫 번째 인수로 'student' DataFrame을 사용하고 정렬 기준이 되는 열의 'Id'가 뒤따릅니다. 마지막에 있는 print() 함수는 정렬된 DataFrame을 콘솔에 인쇄합니다.
다음 출력에서 'Id' 열이 순서대로 정렬된 위치를 확인할 수 있습니다.
예제 4: R에서 날짜별로 DataFrame 정렬
R의 DataFrame은 날짜 값으로 정렬할 수도 있습니다. 이를 위해 as.date() 함수로 sorted 함수를 지정하여 날짜 형식을 지정해야 합니다.
행사 날 = 데이터. 액자 ( 이벤트 = 씨 ( '2023년 3월 4일' , '2023년 2월 2일' ,'2023년 10월 1일' , '2023년 3월 29일' ) ,
요금 = 씨 ( 3100 , 2200 , 1000 , 2900 ) )
행사 날 [ 주문하다 ( ~처럼 . 날짜 ( event_date$이벤트 , 체재 = '%d/%m/%Y' ) ) , ]
여기에는 '월/일/년' 형식의 날짜 문자열이 있는 'event' 열을 포함하는 'event_date' DataFrame이 있습니다. 이러한 날짜 문자열을 오름차순으로 정렬해야 합니다. DataFrame을 'event' 열을 기준으로 오름차순으로 정렬하는 order() 함수를 사용합니다. 'as.Date' 함수를 사용하여 'event' 열의 날짜 문자열을 실제 날짜로 변환하고 'format' 매개변수를 사용하여 날짜 문자열의 형식을 지정하여 이를 수행합니다.
따라서 '이벤트' 날짜 열을 기준으로 오름차순으로 정렬된 데이터를 나타냅니다.

예제 5: R에서 Setorder() 메서드를 사용하여 DataFrame 정렬
마찬가지로 setorder()도 DataFrame을 정렬하는 또 다른 방법입니다. 배열() 메서드와 마찬가지로 인수를 취하여 DataFrame을 정렬합니다. setorder() 메서드의 R 코드는 다음과 같습니다.
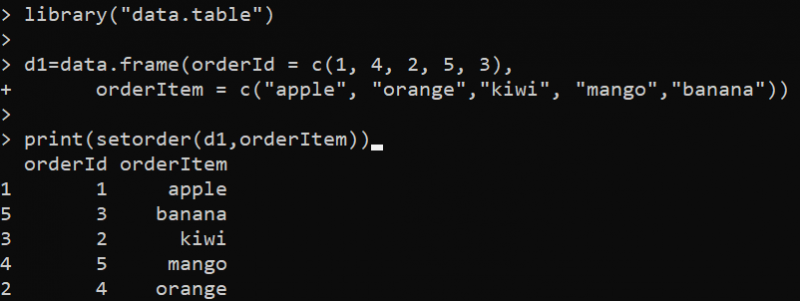
도서관 ( '데이터 테이블' )d1 = 데이터. 액자 ( 주문 아이디 = 씨 ( 1 , 4 , 2 , 5 , 삼 ) ,
주문 항목 = 씨 ( '사과' , '주황색' , '키위' , '망고' , '바나나' ) )
인쇄 ( 순서를 정하다 ( d1 , 주문 항목 ) )
여기에서는 setorder()가 이 패키지의 기능이므로 먼저 data.table 라이브러리를 설정합니다. 그런 다음 data.frame() 함수를 사용하여 DataFrame을 만듭니다. DataFrame은 정렬에 사용하는 두 개의 열로만 지정됩니다. 그런 다음 print() 함수 내에 setorder() 함수를 설정합니다. setorder() 함수는 'd1' DataFrame을 첫 번째 매개변수로 사용하고 'orderId' 열을 DataFrame을 정렬하는 두 번째 매개변수로 사용합니다. 'setorder' 함수는 'orderId' 열의 값을 기준으로 데이터 테이블의 행을 오름차순으로 재정렬합니다.
정렬된 DataFrame은 다음 R 콘솔의 출력입니다.
예제 6: R에서 Row.Names() 메서드를 사용하여 DataFrame 정렬
row.names() 메서드는 R에서 DataFrame을 정렬하는 방법이기도 합니다. row.names()는 지정된 행을 기준으로 DataFrame을 정렬합니다.
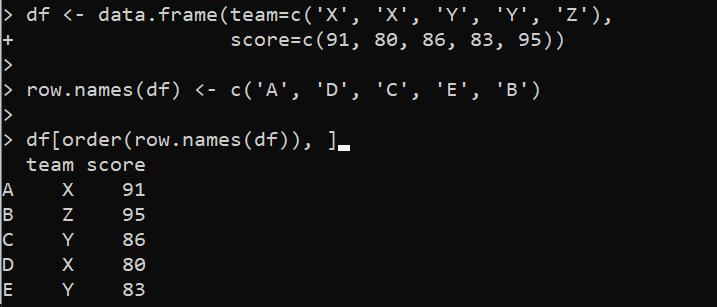
df < - 데이터. 액자 ( 팀 = 씨 ( '엑스' , '엑스' , '그리고' , '그리고' , '와 함께' ) ,점수 = 씨 ( 91 , 80 , 86 , 83 , 95 ) )
열. 이름 ( df ) < - 씨 ( 'ㅏ' , '디' , '씨' , '그리고' , '비' )
df [ 주문하다 ( 열. 이름 ( df ) ) , ]
여기에서 data.frame() 함수는 열이 값으로 지정되는 'df' 변수 내에서 설정됩니다. 그런 다음 DataFrame의 행 이름은 row.names() 함수를 사용하여 지정됩니다. 그런 다음 order() 함수를 호출하여 행 이름별로 DataFrame을 정렬합니다. order() 함수는 DataFrame의 행을 재구성하는 데 사용되는 정렬된 행의 인덱스를 반환합니다.
출력에는 알파벳순으로 행별로 정렬된 DataFrame이 표시됩니다.
결론
우리는 R에서 DataFrames를 정렬하는 다양한 기능을 보았습니다. 각 방법에는 장점이 있으며 정렬 작업이 필요합니다. R 언어에서 DataFrame을 정렬하는 더 많은 방법이나 방법이 있을 수 있지만 order(), 배열() 및 setorder() 메서드는 정렬에 가장 중요하고 사용하기 쉽습니다.