그룹 집계는 MongoDB에서 어떻게 작동합니까?
$group 연산자는 지정된 _id 표현식에 따라 입력 문서를 그룹화하는 데 사용해야 합니다. 그런 다음 각 개별 그룹에 대한 총 값이 포함된 단일 문서를 반환해야 합니다. 구현을 시작하기 위해 MongoDB에 'Books' 컬렉션을 생성했습니다. '도서' 컬렉션을 만든 후 다른 필드와 연결된 문서를 삽입했습니다. 문서는 실행할 쿼리가 아래와 같이 insertMany() 메서드를 통해 컬렉션에 삽입됩니다.
>db.Books.insertMany([{
_id:1,
제목: '안나 카레니나',
가격: 290,
연도: 1879,
order_status: '재고 있음',
작가: {
'이름': '레오 톨스토이'
}
},
{
_id:2,
제목: '앵무새 죽이기',
가격: 500,
연도: 1960,
order_status: '품절',
작가: {
'이름':'하퍼 리'
}
},
{
_id:3,
제목: '투명인간',
가격: 312,
연도: 1953,
order_status: '재고 있음',
작가: {
'이름':'랄프 엘리슨'
}
},
{
_id:4,
제목: '사랑하는',
가격: 370,
연도: 1873,
order_status: 'out_of_stock',
작가: {
'이름': '토니 모리슨'
}
},
{
_id:5,
제목: 'Things Fall Apart',
가격: 200,
연도: 1958,
order_status: '재고 있음',
작가: {
'이름':'치누아 아체베'
}
},
{
_id:6,
제목: '컬러 퍼플',
가격: 510,
연도: 1982,
order_status: '품절',
작가: {
'이름': '앨리스 워커'
}
}
])
출력이 'true'로 승인되기 때문에 문서는 오류 발생 없이 'Books' 컬렉션에 성공적으로 저장됩니다. 이제 '$group' 집계를 수행하기 위해 'Books' 컬렉션의 이러한 문서를 사용할 것입니다.

예 # 1: $group 집계 사용
$group 집계의 간단한 사용법은 여기에서 설명합니다. 집계 쿼리는 '$group' 연산자를 먼저 입력한 다음 '$group' 연산자를 추가로 사용하여 그룹화된 문서를 생성하는 식을 입력합니다.
>db.Books.aggregate([
{ $group:{ _id:'$author.name'} }
])
$group 연산자 위의 쿼리는 모든 입력 문서에 대한 총 값을 계산하기 위해 '_id' 필드로 지정됩니다. 그러면 '_id' 필드는 '_id' 필드에서 다른 그룹을 형성하는 '$author.name'으로 할당됩니다. 누적된 값을 계산하지 않기 때문에 $author.name의 개별 값이 반환됩니다. $group 집계 쿼리 실행 결과는 다음과 같습니다. _id 필드에는 author.names 값이 있습니다.

예 # 2: $push 누산기와 함께 $group 집계 사용
$group 집계의 예는 위에서 이미 언급한 누산기를 사용합니다. 그러나 $group 집계에서 누산기를 사용할 수 있습니다. 누산기 연산자는 '_id' 아래에 '그룹화'된 연산자 이외의 입력 문서 필드에 사용되는 연산자입니다. 식의 필드를 배열로 푸시하려는 경우 '$push' 누산기가 '$group' 연산자에서 호출된다고 가정해 보겠습니다. 예제는 '$group'의 '$push' 누산기를 보다 명확하게 이해하는 데 도움이 됩니다.
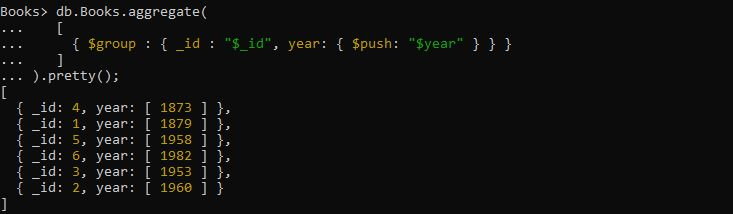
>db.Books.aggregate([
{ $그룹: { _id: '$_id', 연도: { $push: '$year' } } }
]
).예쁜();
여기에서 주어진 책의 출판 연도를 배열로 그룹화하려고 합니다. 이를 위해서는 위의 쿼리를 적용해야 합니다. 집계 쿼리는 '$group' 연산자가 '_id' 필드 표현식과 'year' 필드 표현식을 사용하여 $push 누산기를 사용하여 그룹 연도를 가져오는 표현식과 함께 제공됩니다. 이 특정 쿼리에서 검색된 출력은 연도 필드의 배열을 만들고 반환된 그룹화된 문서를 그 안에 저장합니다.
예 # 3: '$min' 누산기와 함께 $group 집계 사용
다음으로 컬렉션의 모든 문서에서 최소 일치 값을 가져오기 위해 $group 집계에 사용되는 '$min' 누산기가 있습니다. $min 누산기에 대한 쿼리 표현식은 다음과 같습니다.
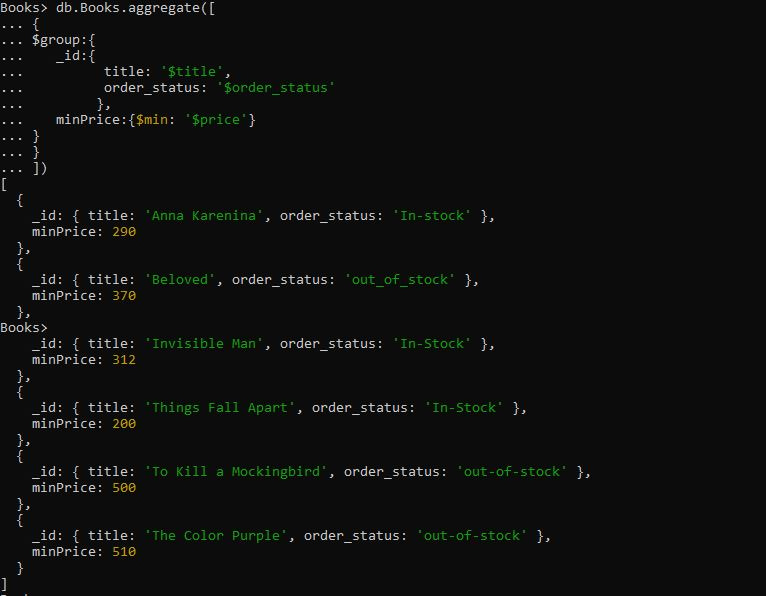
>db.Books.aggregate([{
$그룹:{
_ID:{
제목: '$제목',
order_status: '$주문_상태'
},
minPrice:{$min: '$price'}
}
}
])
쿼리에는 'title' 및 'order_status' 필드에 대한 문서를 그룹화한 '$group' 집계 표현식이 있습니다. 그런 다음 그룹화되지 않은 필드에서 최소 가격 값을 가져와 문서를 그룹화하는 $min 누산기를 제공했습니다. 아래 $min accumulator 쿼리를 실행하면 제목과 order_status별로 그룹화된 문서를 순서대로 반환합니다. 최저 가격이 먼저 표시되고 문서의 최고 가격이 마지막에 표시됩니다.
예 # 4: $sum Accumulator와 함께 $group 집계 사용
$group 연산자를 사용하여 모든 숫자 필드의 합계를 얻기 위해 $sum 누산기 작업이 배포됩니다. 컬렉션의 숫자가 아닌 값은 이 누산기에 의해 고려됩니다. 또한 여기에서는 $group 집계와 함께 $match 집계를 사용하고 있습니다. $match 집계는 문서에 제공된 쿼리 조건을 수락하고 일치하는 문서를 $group 집계에 전달한 다음 각 그룹에 대한 문서의 합계를 반환합니다. $sum 누산기의 경우 쿼리가 아래에 표시됩니다.
>db.Books.aggregate([{ $match:{ order_status:'재고 있음'}},
{ $group:{ _id:'$author.name', totalBooks: { $sum:1 } }
}])
위의 집계 쿼리는 상태가 'In-Stock'인 모든 'order_status'와 일치하고 $group에 입력으로 전달되는 $match 연산자로 시작합니다. 그런 다음 $group 연산자에는 주식에 있는 모든 책의 합계를 출력하는 $sum accumulator 표현식이 있습니다. '$sum:1'은 동일한 그룹에 속하는 각 문서에 1을 추가합니다. 여기서 출력에는 'In-Stock'과 연결된 'order_status'가 있는 두 개의 그룹화된 문서만 표시되었습니다.

예 # 5: $sort 집계와 함께 $group 집계 사용
여기서 $group 연산자는 그룹화된 문서를 정렬하는 데 사용되는 '$sort' 연산자와 함께 사용됩니다. 다음 쿼리에는 정렬 작업에 대한 세 단계가 있습니다. 첫 번째는 $match 단계, 그 다음은 $group 단계, 마지막은 그룹화된 문서를 정렬하는 $sort 단계입니다.
>db.Books.aggregate([{ $match:{ order_status:'품절'}},
{ $group:{ _id:{ authorName :'$author.name'}, totalBooks: { $sum:1} } },
{ $정렬:{ 작성자 이름:1}}
])
여기에서 'order_status'가 품절인 일치하는 문서를 가져왔습니다. 그러면 일치하는 문서가 'authorName' 필드와 'totalBooks'로 문서를 그룹화한 $group 단계에 입력됩니다. $group 표현식은 총 '재고 없음' 책 수에 대한 $sum 누산기와 연결됩니다. 그런 다음 그룹화된 문서는 $sort 표현식을 사용하여 오름차순으로 정렬됩니다. 여기에서 '1'은 오름차순을 나타냅니다. 지정된 순서로 정렬된 그룹 문서는 다음 출력에서 얻습니다.

예 # 6: 고유 값에 대해 $group 집계 사용
집계 절차는 또한 $group 연산자를 사용하여 문서를 항목별로 그룹화하여 고유한 항목 값을 추출합니다. MongoDB에서 이 명령문의 쿼리 표현식을 갖도록 합시다.
>db.Books.aggregate( [ { $group : { _id : '$title' } } ] ).pretty();그룹 문서의 고유한 값을 가져오기 위해 집계 쿼리가 Books 컬렉션에 적용됩니다. 여기에서 $group은 '제목' 필드를 입력한 고유한 값을 출력하는 _id 표현식을 사용합니다. 그룹 문서의 출력은 _id 필드에 대한 제목 이름 그룹이 있는 이 쿼리를 실행하면 얻을 수 있습니다.

결론
이 가이드는 MongoDB 데이터베이스에서 문서를 그룹화하기 위한 $group 집계 연산자의 개념을 명확하게 하는 것을 목표로 했습니다. MongoDB 집계 방식은 그룹화 현상을 개선합니다. $group 연산자의 구문 구조는 예제 프로그램과 함께 설명됩니다. $group 연산자의 기본 예제 외에도 $push, $min, $sum과 같은 일부 누산기 및 $match 및 $sort와 같은 연산자와 함께 이 연산자를 사용했습니다.