{ 이름: '알렉사 빌' , 등급: 'ㅏ' , 강의: '파이썬' },
{ 이름: '제인 마크스' , 등급: '비' , 강의: '자바' },
{ 이름: '폴 켄' , 등급: '씨' , 강의: '씨#' },
{ 이름: '에밀리 조' , 등급: '디' , 강의: 'php' }
]);
컬렉션이 내부에 일부 문서와 함께 존재할 때 고유한 인덱스 필드를 생성할 수도 있습니다. 이를 위해 삽입 쿼리가 다음과 같이 제공되는 '후보'인 새 컬렉션에 문서를 삽입합니다.
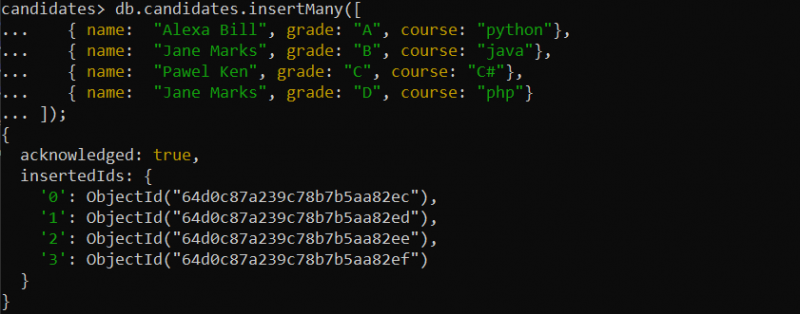
예 1: 단일 필드의 고유 인덱스 생성
createIndex() 메소드를 사용하여 인덱스를 생성할 수 있으며 부울 'true'로 고유 옵션을 지정하여 해당 필드를 고유하게 만들 수 있습니다.
db.candidates.createIndex( { 등급: 1 }, { 고유: 참 } )
여기서는 'candidates' 컬렉션에서 createIndex() 메서드를 시작하여 특정 필드의 고유 인덱스를 생성합니다. 그런 다음 인덱스 사양에 대해 값이 '1'인 '등급' 필드를 제공합니다. 여기서 값 '1'은 컬렉션의 오름차순 인덱스를 나타냅니다. 다음으로, '등급' 필드의 고유성을 강화하기 위해 'true' 값으로 'unique' 옵션을 지정합니다.
출력은 '등급' 필드의 고유 인덱스가 '후보' 컬렉션에 대해 생성되었음을 나타냅니다.

예 2: 두 개 이상의 필드에 대한 고유 인덱스 생성
이전 예에서는 단일 필드만 고유 인덱스로 생성되었습니다. 그러나 createIndex() 메서드를 사용하여 두 개의 필드를 동시에 고유 인덱스로 생성할 수도 있습니다.
db.candidates.createIndex( { 등급: 1 , 강의: 1 }, { 고유: 참 } )
여기서는 동일한 “candidates” 컬렉션에 대해 createIndex() 메서드를 호출합니다. createIndex() 메소드에 'grade'와 'course'라는 두 개의 필드를 지정하고 첫 번째 표현식으로 '1' 값을 지정합니다. 그런 다음 'true' 값으로 고유 옵션을 설정하여 두 개의 고유 필드를 생성합니다.
출력은 다음 '후보자' 컬렉션에 대한 두 개의 고유 인덱스 'grade_1' 및 'course_1'을 나타냅니다.

예 3: 필드의 복합 고유 인덱스 생성
그러나 동일한 컬렉션 내에서 동시에 고유한 복합 인덱스를 생성할 수도 있습니다. 다음 쿼리를 통해 이를 달성합니다.
db.candidates.createIndex( { 이름: 1 , 등급: 1 , 강의: 1 }, { 고유: 참 }createIndex() 메서드를 다시 사용하여 “candidates” 컬렉션에 대한 복합 고유 인덱스를 생성합니다. 이번에는 'candidates' 컬렉션의 오름차순 인덱스 필드 역할을 하는 'grade', 'name' 및 'course'라는 세 가지 필드를 전달합니다. 다음으로 해당 옵션에 대해 'true'가 할당되므로 필드를 고유하게 만들기 위해 'unique' 옵션을 호출합니다.
출력에는 이제 세 필드 모두가 지정된 컬렉션의 고유 인덱스임을 보여주는 결과가 표시됩니다.

예 4: 중복 필드 값의 고유 인덱스 생성
이제 고유성 제약 조건을 유지하기 위해 오류를 유발하는 중복 필드 값에 대한 고유 인덱스를 만들려고 합니다.
db.candidates.createIndex({이름: 1 },{고유:true})여기서는 유사한 값이 포함된 필드에 고유 인덱스 기준을 적용합니다. createIndex() 메서드 내에서 '1' 값으로 'name' 필드를 호출하여 고유 인덱스로 만들고 'true' 값으로 고유 옵션을 정의합니다. 두 문서에는 동일한 값을 가진 '이름' 필드가 있으므로 이 필드를 '후보' 컬렉션의 고유 인덱스로 만들 수 없습니다. 쿼리 실행 시 중복 키 오류가 발생합니다.
예상대로 이름 필드에 두 개의 서로 다른 문서에 대한 동일한 값이 있기 때문에 출력은 결과를 생성합니다.

따라서 문서의 각 '이름' 필드에 고유한 값을 제공하여 '후보' 컬렉션을 업데이트한 다음 '이름' 필드를 고유 인덱스로 생성합니다. 해당 쿼리를 실행하면 일반적으로 다음과 같이 '이름' 필드가 고유 인덱스로 생성됩니다.

예 5: 누락된 필드의 고유 인덱스 생성
또는 컬렉션의 어떤 문서에도 존재하지 않는 필드에 createIndex() 메서드를 적용합니다. 결과적으로 인덱스는 해당 필드에 대해 null 값을 저장하고 필드 값에 대한 위반으로 인해 작업이 실패합니다.
db.candidates.createIndex( { 이메일: 1 }, { 고유: 참 } )여기서는 'email' 필드에 '1' 값이 제공되는 createIndex() 메서드를 사용합니다. 'email' 필드는 'candidates' 컬렉션에 존재하지 않으며 고유 옵션을 'true'로 설정하여 'candidates' 컬렉션에 대한 고유 인덱스로 만들려고 합니다.
이에 대한 쿼리가 실행되면 '후보자' 컬렉션에 'email' 필드가 누락되어 출력에 오류가 발생합니다.

예 6: 스파스 옵션을 사용하여 필드의 고유 인덱스 생성
다음으로 sparse 옵션을 사용하여 고유 인덱스를 생성할 수도 있습니다. 희소 인덱스의 기능은 인덱스된 필드가 있는 문서만 포함하고 인덱스된 필드가 없는 문서는 제외한다는 것입니다. 희소 옵션을 설정하기 위해 다음 구조를 제공했습니다.
db.candidates.createIndex( { 코스 : 1 },{ 이름: 'unique_sparse_course_index' , 고유함: true, 희소함: true } )
여기서는 'course' 필드 값이 '1'로 설정된 createIndex() 메서드를 제공합니다. 그런 다음 'course'라는 고유 인덱스 필드를 설정하는 추가 옵션을 지정합니다. 옵션에는 'unique_sparse_course_index' 인덱스를 설정하는 'name'이 포함됩니다. 그런 다음 'true' 값으로 지정된 'unique' 옵션이 있고 'sparse' 옵션도 'true'로 설정됩니다.
출력은 다음과 같이 'course' 필드에 고유한 희소 인덱스를 생성합니다.

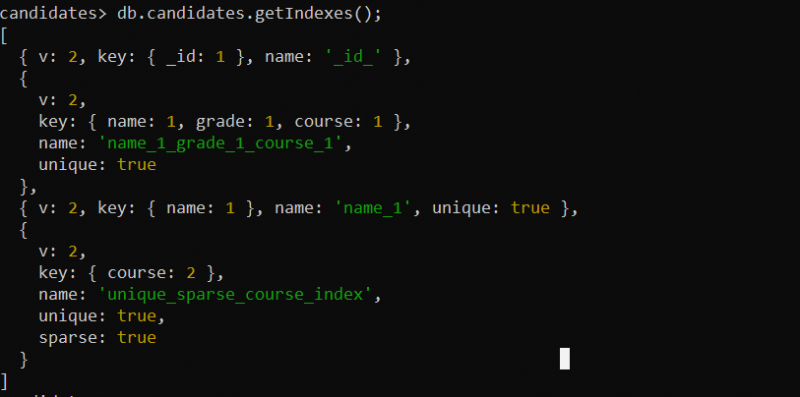
예제 7: GetIndexes() 메서드를 사용하여 생성된 고유 인덱스 표시
이전 예에서는 제공된 컬렉션에 대해 고유 인덱스만 생성되었습니다. 'candidates' 컬렉션의 고유 인덱스에 대한 정보를 보고 얻으려면 다음 getIndexes() 메서드를 사용합니다.
db.candidates.getIndexes();여기서는 'candidates' 컬렉션에 대해 getIndexes() 함수를 호출합니다. getIndexes() 함수는 이전 예제에서 생성한 'candidates' 컬렉션에 대한 모든 인덱스 필드를 반환합니다.
출력에는 컬렉션에 대해 생성한 고유 인덱스(고유 인덱스, 복합 인덱스 또는 고유 희소 인덱스)가 표시됩니다.
결론
우리는 컬렉션의 특정 필드에 대한 고유 인덱스를 생성하려고 했습니다. 단일 필드와 여러 필드에 대한 고유 인덱스를 생성하는 다양한 방법을 살펴보았습니다. 또한 고유 제약 조건 위반으로 인해 작업이 실패하는 고유 인덱스를 생성하려고 시도했습니다.