주어진 데이터 세트가 단일 CSV 파일에 없는 경우가 있습니다. 그들은 모두 다른 Excel 시트에 있습니다. 여러 데이터 세트 대신 단일 데이터 세트에서 모든 계산 또는 전처리 활동을 수행하는 것이 더 좋다는 것을 이미 알고 있습니다. 전처리 작업에 소요되는 시간을 줄이거나 절약합니다. 또한 데이터 분석가 또는 데이터 과학자는 사용 가능한 데이터의 분석 또는 검사를 시작하기도 전에 병합해야 하는 수많은 CSV 파일로 인해 과부하가 걸리는 경우가 많습니다. 반면에 모든 파일이 단일 또는 동일한 데이터 소스에서 가져오고 동일한 열/변수 이름 및 데이터 구조를 갖는 것이 항상 가능한 것은 아닙니다. 이 게시물은 두 개 이상의 CSV 파일을 유사하거나 다른 열 구조로 결합하는 방법을 알려줍니다.
CSV 파일을 결합하는 이유는 무엇입니까?
데이터 세트는 특정 주제와 관련된 값 또는 숫자의 모음 또는 그룹일 수 있습니다. 예를 들어 특정 수업에서 각 학생의 테스트 결과가 데이터 세트의 예입니다. 큰 데이터 세트의 크기로 인해 서로 다른 범주에 대해 별도의 CSV 파일에 저장되는 경우가 많습니다. 예를 들어, 특정 질병에 대해 환자를 검사해야 하는 경우 성별, 병력, 연령, 질병의 중증도 등 모든 요소를 고려해야 합니다. 따라서 CSV 데이터를 결합하여 다양한 예측 변수에 영향을 미치는지 확인해야 합니다. 상들. 또한 계산이나 전처리 작업을 수행할 때 여러 개의 데이터 세트보다 하나의 데이터 세트로 작업하고 관리하는 것이 좋습니다. 메모리 및 기타 계산 리소스를 절약합니다.
Python에서 CSV 파일을 결합하는 방법은 무엇입니까?
Python에서 둘 이상의 CSV 파일을 결합하는 여러 가지 방법과 방법이 있습니다. 아래 섹션에서는 CSV 파일을 pandas 데이터 프레임으로 결합하기 위해 append(), concat() 및 merge() 함수 등을 사용하고 데이터 프레임은 단일 CSV 파일로 변환됩니다. 여러 CSV 파일을 유사하거나 가변적인 열 구조와 결합하는 방법을 알려드립니다.
방법 # 1: CSV를 유사한 구조 또는 열과 결합
현재 작업 디렉토리에는 'test1'과 'test2'라는 두 개의 CSV 파일이 있습니다.
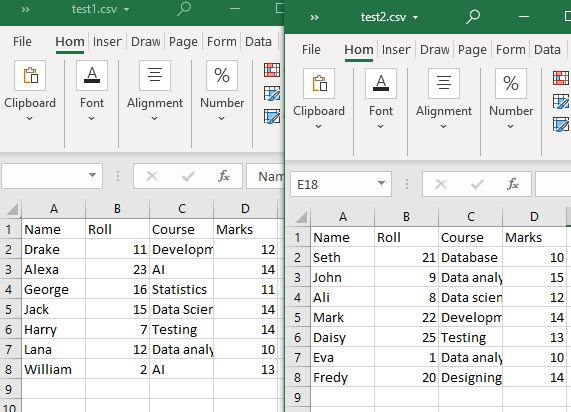
예제 # 1: append() 함수 사용
두 CSV 파일은 모두 동일한 구조입니다. glob() 함수는 이 메서드에서 작업 디렉토리의 CSV 파일만 나열하는 데 사용됩니다. 그런 다음 'pandas.DataFrame.append()'를 사용하여 CSV 파일(공통 테이블 구조 포함)을 읽습니다.

산출:
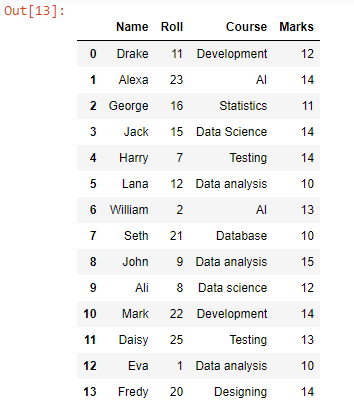
추가 기능을 사용하여 test1.csv의 데이터 행 아래에 test2.csv의 각 데이터 행을 추가하거나 추가했습니다. 파일의 모든 데이터 행이 결합된 것을 볼 수 있습니다. 이 데이터 프레임을 CSV로 변환하려면 to_csv() 함수를 사용할 수 있습니다.

이렇게 하면 지정된 이름(예: merged.csv)으로 작업 디렉토리에 'test1' 및 'test2' CSV 파일의 결합된 CSV 파일이 생성됩니다.
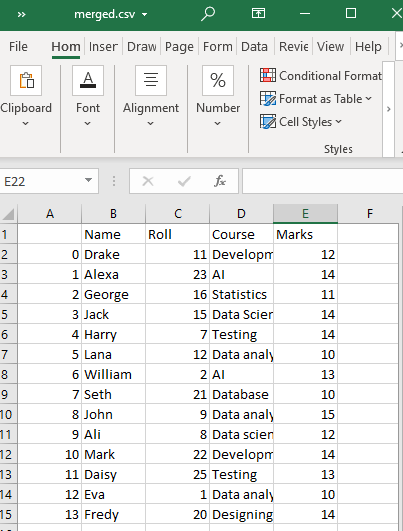
예제 # 2: concat() 함수 사용
먼저 pandas 모듈을 가져옵니다. 지도 메서드는 pd.read_csv()를 사용하여 전달한 각 CSV 파일을 읽습니다. 이렇게 매핑된 파일(CSV 파일)은 기본적으로 pd.concat() 함수를 사용하여 행 축을 따라 결합됩니다. CSV 파일을 가로로 결합하려면 axis=1을 전달할 수 있습니다. 인덱스 무시 = True를 지정하면 결합된 데이터 프레임에 대한 연속 인덱스 값도 생성됩니다.

pd.read_csv()는 연결 후 CSV 파일을 pandas 데이터 프레임으로 읽기 위해 concat() 함수 내부로 전달됩니다.
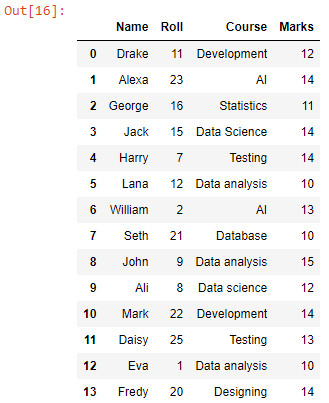
작업 디렉토리에 있는 모든 CSV 파일의 데이터가 결합된 데이터 프레임을 얻었습니다. 이제 CSV 파일로 변환해 보겠습니다.
결합된 CSV는 현재 디렉토리에 생성됩니다.
방법 # 2: CSV를 다른 구조 또는 열과 결합
첫 번째 방법에서 CSV 파일을 동일한 열과 구조로 결합하는 방법에 대해 논의했습니다. 이 방법에서는 CSV 파일을 다른 열과 구조로 결합합니다.
예제 # 1: merge() 함수 사용
pandas 모듈의 'pandas.merge()' 함수는 두 개의 CSV 파일을 결합할 수 있습니다. 병합은 단순히 공유 열 또는 속성을 기반으로 두 개의 데이터세트를 단일 데이터세트로 결합하는 것을 말합니다.
네 가지 조인 방법으로 데이터 프레임을 병합할 수 있습니다.
- 안의
- 오른쪽
- 왼쪽
- 밖의
이러한 유형의 병합을 수행하기 위해 두 개의 CSV 파일을 사용합니다.
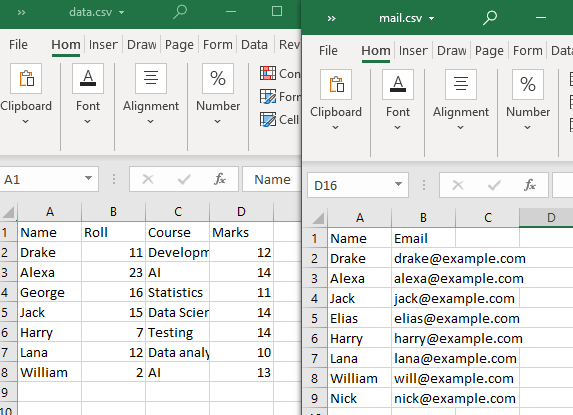
두 CSV 파일에서 하나 이상의 속성 또는 열을 공유해야 합니다. 관찰한 바와 같이 '이름' 열과 해당 속성 중 일부는 두 CSV 파일에서 공유됩니다.
내부 조인을 사용하여 병합
merge() 함수에서 매개변수 how='inner'를 지정하면 지정된 열에 따라 두 데이터 프레임을 결합한 다음 두 원본 데이터 프레임에서 동일한/동일한 값을 가진 행만 포함하는 새 데이터 프레임을 제공합니다.
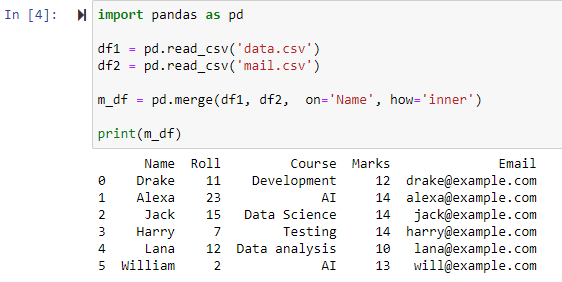
보시다시피 이 함수는 두 CSV 파일을 병합하고 '이름' 열의 공통 속성을 기반으로 행을 반환했습니다.
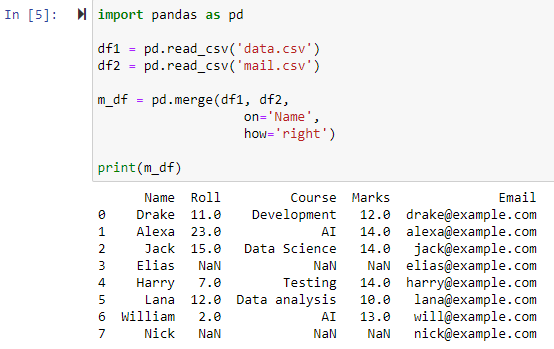
오른쪽 외부 조인을 사용하여 병합
매개변수 how='right'가 지정되면 매개변수 'on'에 대해 지정한 열을 기반으로 두 데이터 프레임이 결합됩니다. 그리고 왼쪽 데이터 프레임에 값이 없는 행을 포함하여 오른쪽 데이터 프레임의 모든 행을 포함하는 새 데이터 프레임이 반환되며 왼쪽 데이터 프레임의 열 값은 NAN으로 설정됩니다.
Left Outer Join을 사용한 병합
매개변수가 'left'로 지정되는 경우 'on' 매개변수를 사용하여 지정된 열을 기반으로 두 데이터 프레임이 결합되어 왼쪽 데이터 프레임의 모든 행과 NAN이 있는 행이 포함된 새 데이터 프레임이 반환됩니다. 또는 오른쪽 데이터 프레임의 null 값이고 오른쪽 데이터 프레임 열 값을 NAN으로 설정합니다.
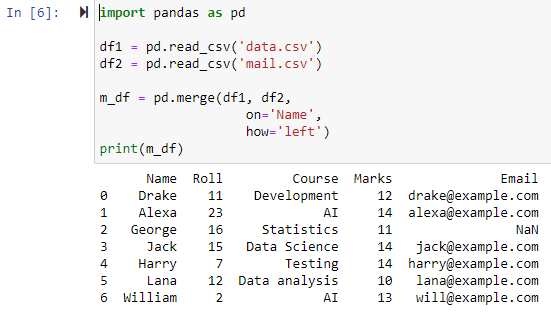
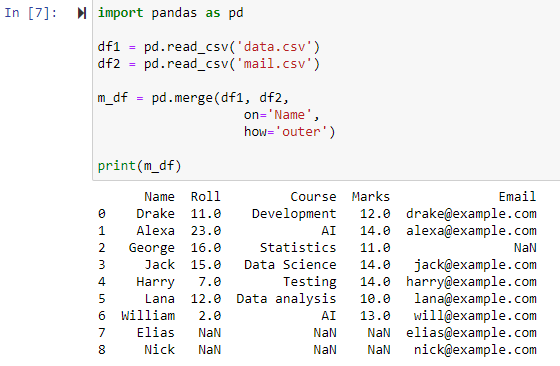
완전 외부 조인을 사용하여 병합
how='outer'가 지정되면 'on' 매개변수에 지정된 열에 따라 두 개의 데이터 프레임이 결합되어 df1 및 df2 데이터 프레임의 행을 모두 포함하는 새 데이터 프레임을 반환하고 모든 행의 값으로 NAN을 설정합니다. 데이터 프레임 중 하나에 데이터가 없는 경우.
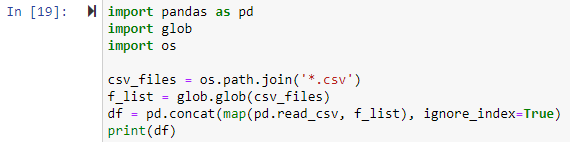
예 # 2: 작업 디렉토리의 모든 CSV 파일 결합
이 방법에서는 glob 모듈을 사용하여 모든 .csv 파일을 pandas DataFrame으로 결합합니다. 모든 라이브러리를 먼저 가져와야 했습니다. 다음으로 결합하려는 각 CSV 파일의 경로를 설정합니다. 파일 경로는 아래 예제에서 os.path.join() 함수의 첫 번째 인수이고 두 번째 인수는 조인할 경로 구성 요소 또는 .csv 파일입니다. 여기서 '*.csv' 식은 작업 디렉터리에서 .csv 파일 확장자로 끝나는 각 파일을 찾아 반환합니다. glob.glob(조인된 파일) 함수는 병합된 파일의 이름 목록을 입력으로 받아들이고 모든 병합/결합된 파일 목록을 출력합니다.
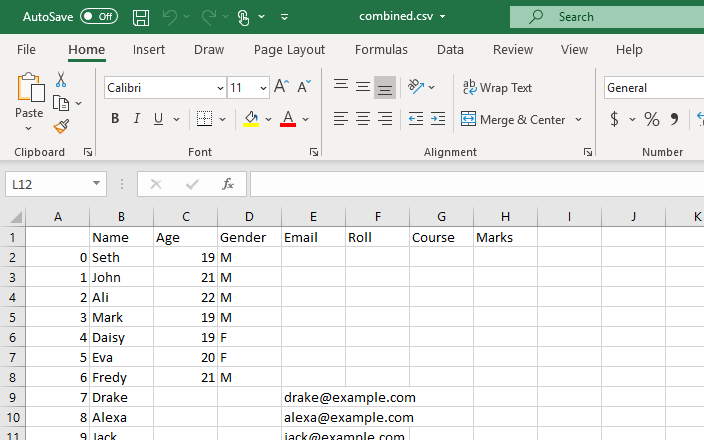
이 스크립트는 작업 디렉터리에 있는 모든 CSV 파일의 데이터가 결합된 데이터 프레임을 반환합니다.
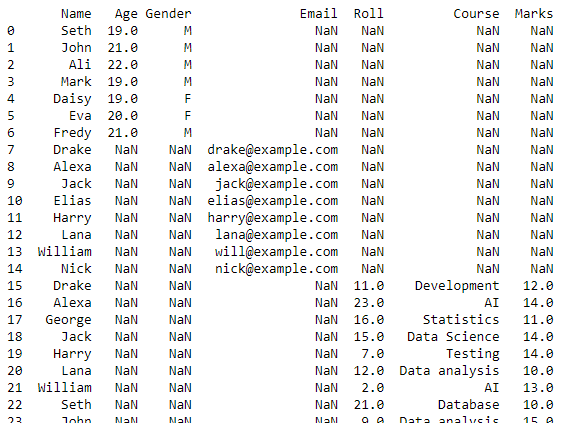
이 데이터 프레임은 CSV 파일로 변환되며 이 변환에는 to_csv() 함수가 사용됩니다. 이 새 CSV 파일은 현재 작업 디렉토리에 저장된 모든 CSV 파일에서 생성된 결합된 CSV 파일입니다.
결론
이 게시물에서는 CSV 파일을 결합해야 하는 이유에 대해 논의했습니다. Python에서 두 개 이상의 CSV 파일을 결합하는 방법에 대해 논의했습니다. 이 자습서를 두 섹션으로 나누었습니다. 첫 번째 섹션에서는 동일한 구조 또는 열 이름의 CSV 파일을 결합하기 위해 append() 및 concat() 함수를 사용하는 방법을 설명했습니다. 두 번째 섹션에서는 다른 열과 구조의 CSV 파일을 결합하기 위해 merge() 메서드, os.path.join() 및 glob 메서드를 사용했습니다.