조건에 따라 배열에 임의의 기능을 적용하는 두 가지 방법이 있습니다. 배열의 각 요소에 하나씩 함수를 적용할 때 유용한 '축에 적용' 기능을 적용할 수 있으며 n차원 배열에 유용합니다. 두 번째 방법은 1차원 배열에 적용되는 '축을 따라 적용'입니다.
통사론:
방법 1: 축을 따라 적용
멍멍. 축을 따라 적용 ( 1d_기능 , 중심선 , 아 , *인수 , **쿼그 )구문에는 5개의 인수를 전달하는 'numpy.apply' 함수가 있습니다. '1d_function'인 첫 번째 인수는 1차원 배열에서 작동하며 이는 필수입니다. 두 번째 인수인 '축'은 배열을 슬라이스하고 해당 기능을 적용하려는 축입니다. 세 번째 매개변수는 함수를 적용하려는 지정된 배열인 'arr'입니다. '*args' 및 '*kwargs'는 추가할 필요가 없는 추가 인수입니다.
예 1:
'적용' 방법을 더 잘 이해하기 위해 적용 방법의 작동을 확인하는 예제를 수행합니다. 이 경우 'apply_along_Axis' 기능을 수행합니다. 첫 번째 단계를 진행해 보겠습니다. 먼저 NumPy 라이브러리를 np로 포함합니다. 그런 다음 '8, 1, 7, 4, 3, 9, 5, 2, 6'의 정수 값을 가진 3x3 행렬을 포함하는 'arr'이라는 배열을 만듭니다. 다음 줄에서 apply_along_Axis 함수의 결과를 유지하는 역할을 하는 'array'라는 변수를 만듭니다.
해당 함수에 세 개의 인수를 전달합니다. 첫 번째는 배열에 적용하려는 함수입니다. 우리의 경우 배열이 정렬되기를 원하기 때문에 정렬된 함수입니다. 그런 다음 두 번째 인수 '1'을 전달합니다. 이는 axis=1을 따라 배열을 슬라이스하려는 것을 의미합니다. 마지막으로 이 경우 정렬할 배열을 전달합니다. 코드의 끝에서 우리는 단순히 print() 문을 사용하여 표시되는 두 배열(원래 배열과 결과 배열)을 모두 인쇄합니다.
수입 numpy ~처럼 예를 들어
아 = 예를 들어 정렬 ( [ [ 8 , 1 , 7 ] , [ 4 , 삼 , 9 ] , [ 5 , 둘 , 6 ] ] )
정렬 = 예를 들어 축을 따라 적용 ( 정렬 , 1 , 아 )
인쇄 ( '원래 배열은:' , 아 )
인쇄 ( '정렬된 배열은 다음과 같습니다.' , 정렬 )
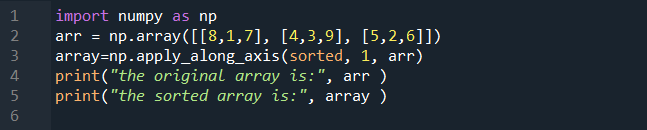
다음 출력에서 볼 수 있듯이 두 배열을 모두 표시했습니다. 첫 번째 값은 행렬의 각 행에 무작위로 배치됩니다. 그러나 두 번째 항목에서는 정렬된 배열을 볼 수 있습니다. 축 '1'을 전달했기 때문에 전체 배열을 정렬하지 않았지만 표시된 대로 행별로 정렬했습니다. 각 행이 정렬됩니다. 주어진 배열의 첫 번째 행은 '8, 1, 7'입니다. 정렬된 배열에서 첫 번째 행은 '1, 7, 8'입니다. 이와 동일하게 각 행이 정렬됩니다.
방법 2: 축에 적용
멍멍. apply_over_axes ( 기능 , ㅏ , 축 )주어진 구문에는 주어진 축에 함수를 적용하는 numpy.apply_over_axis 함수가 있습니다. apply_over_axis 함수 내에서 세 개의 인수를 전달합니다. 첫 번째는 수행할 기능입니다. 두 번째는 배열 자체입니다. 마지막은 함수를 적용하려는 축입니다.
예 2:
다음 예에서 우리는 3차원 배열의 합을 계산하는 '적용' 함수의 두 번째 방법을 수행합니다. 한 가지 기억해야 할 점은 두 배열의 합이 전체 배열을 계산한다는 의미는 아니라는 것입니다. 일부 배열에서는 행 단위 합계를 계산합니다. 즉, 행을 추가하고 행에서 단일 요소를 가져옵니다.
우리의 코드로 넘어갑시다. 먼저 NumPy 패키지를 가져온 다음 3차원 배열을 포함하는 변수를 만듭니다. 이 경우 변수는 'arr'입니다. 다음 줄에서는 apply_over_axis 함수의 결과 배열을 보유하는 또 다른 변수를 만듭니다. 세 개의 인수를 사용하여 'arr' 변수에 apply_over_Axis 함수를 할당합니다. 첫 번째 인수는 np.sum인 합계를 계산하는 NumPy의 내장 함수입니다. 두 번째 매개변수는 배열 자체입니다. 세 번째 인수는 함수가 적용되는 축이며 이 경우 '[0, 2]' 축이 있습니다. 코드 끝에서 print() 문을 사용하여 두 배열을 모두 실행합니다.
수입 numpy ~처럼 예를 들어아 = 예를 들어 정렬 ( [ [ [ 6 , 12 , 둘 ] , [ 둘 , 9 , 6 ] , [ 18 , 0 , 10 ] ] ,
[ [ 12 , 7 , 14 ] , [ 둘 , 17 , 18 ] , [ 0 , 이십 일 , 8 ] ] ] )
정렬 = 예를 들어 apply_over_axes ( 예를 들어 합집합 , 아 , [ 0 , 둘 ] )
인쇄 ( '원래 배열은:' , 아 )
인쇄 ( '배열의 합은 다음과 같습니다.' , 정렬 )
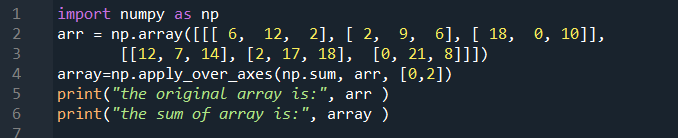
다음 그림과 같이 apply_over_axis 함수를 사용하여 3차원 배열 중 일부를 계산했습니다. 첫 번째 표시된 배열은 '2, 3, 3' 모양의 원래 배열이고 두 번째 배열은 행의 합입니다. 첫 번째 행의 합은 '53', 두 번째 행은 '54', 마지막 행은 '57'입니다.

결론
이 기사에서 우리는 NumPy에서 적용 함수가 어떻게 사용되는지, 그리고 축을 따라 배열에 다른 함수를 어떻게 적용할 수 있는지 연구했습니다. NumPy에서 제공하는 '적용' 메소드를 사용하여 원하는 행이나 열에 기능을 쉽게 적용할 수 있습니다. 전체 배열에 적용할 필요가 없을 때 효율적인 방법입니다. 이 게시물이 적용 방법을 활용하는 방법을 배우는 데 도움이 되기를 바랍니다.