이 기사에서는 C++ 프로그래밍 언어에서 XML을 구문 분석하는 방법에 대해 논의할 것입니다. C++에서 XML 구문 분석 메커니즘을 이해하기 위해 몇 가지 작업 예제를 볼 것입니다.
XML이란 무엇입니까?
XML 마크업 언어로 주로 데이터를 체계적으로 저장하고 전송하는 데 사용됩니다. XML은 eXtensible Markup Language의 약자입니다. HTML과 매우 유사합니다. XML은 데이터를 저장하고 전송하는 데 완전히 초점을 맞춘 반면 HTML은 브라우저에 데이터를 표시하는 데 사용됩니다.
샘플 XML 파일/XML 구문
다음은 샘플 XML 파일입니다.
버전='1.0' 부호화='utf-8'?>
>
>
>
HTML과 달리 태그 지향적인 마크업 언어로 XML 파일에 우리만의 태그를 정의할 수 있습니다. 위의 예에는 와 같은 여러 사용자 정의 태그가 있습니다. 모든 태그에는 해당 종료 태그가 있습니다. 의 종료 태그입니다. 데이터를 구성하려는 만큼 사용자 정의 태그를 정의할 수 있습니다.
C++에서 라이브러리 구문 분석:
대부분의 고급 프로그래밍 언어에서 XML 데이터를 구문 분석하는 다양한 라이브러리가 있습니다. C++도 예외는 아닙니다. 다음은 XML 데이터를 구문 분석하는 가장 인기 있는 C++ 라이브러리입니다.
- RapidXML
- PugiXML
- TinyXML
이름에서 알 수 있듯이 RapidXML은 주로 속도에 중점을 두고 있으며 DOM 스타일의 구문 분석 라이브러리입니다. PugiXML은 유니코드 변환을 지원합니다. UTF-16 문서를 UTF-8로 변환하려면 PugiXML을 사용할 수 있습니다. TinyXML은 XML 데이터를 구문 분석하는 최소 버전이며 이전 두 버전에 비해 빠르지 않습니다. 작업을 완료하고 속도는 신경 쓰지 않으려면 TinyXML을 선택할 수 있습니다.
예
이제 C++의 XML 및 XML 구문 분석 라이브러리에 대한 기본적인 이해가 있습니다. 이제 C++에서 xml 파일을 구문 분석하는 몇 가지 예를 살펴보겠습니다.
- 예-1: RapidXML을 사용하여 C++에서 XML 구문 분석
- 예-2: PugiXML을 사용하여 C++에서 XML 구문 분석
- 예-3: TinyXML을 사용하여 C++에서 XML 구문 분석
이러한 각 예에서 우리는 샘플 XML 파일을 구문 분석하기 위해 해당 라이브러리를 사용할 것입니다.
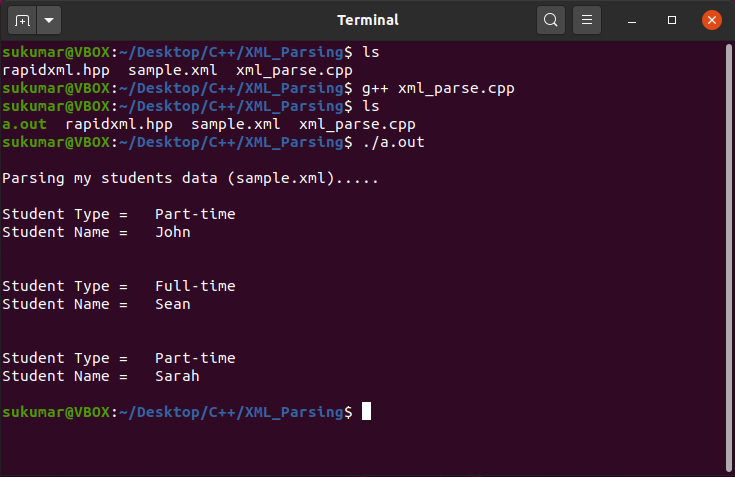
예-1: RapidXML을 사용하여 C++에서 XML 구문 분석
이 예제 프로그램에서는 C++에서 RapidXML 라이브러리를 사용하여 xml을 구문 분석하는 방법을 보여줍니다. 다음은 입력 XML 파일(sample.xml)입니다.
버전='1.0' 부호화='utf-8'?>>
>
>
>
여기서 우리의 목표는 C++를 사용하여 위의 XML 파일을 구문 분석하는 것입니다. 다음은 RapidXML을 사용하여 XML 데이터를 구문 분석하는 C++ 프로그램입니다. RapidXML 라이브러리는 다음에서 다운로드할 수 있습니다. 여기 .
#포함하다#포함하다
#포함하다
#include 'rapidxml.hpp'
사용 네임스페이스시간;
사용 네임스페이스Rapidxml;
xml_document문서
xml_node *root_node= 없는;
정수기본(무효의)
{
비용 << 'N내 학생 데이터 파싱(sample.xml).....' <<끝;
// sample.xml 파일 읽기
파일을 스트림하면('샘플.xml');
벡터<숯>완충기((istreambuf_iterator<숯>(파일)), istreambuf_iterator<숯>());
완충기.푸시백(' 0');
// 버퍼 구문 분석
문서.분석하다<0>(&완충기[0]);
// 루트 노드 찾기
root_node=문서.첫 번째 노드('MyStudentsData');
// 학생 노드를 반복합니다.
~을위한 (xml_node *학생 노드=root_node->첫 번째 노드('학생');학생 노드;학생 노드=학생 노드->next_sibling())
{
비용 << 'N학생 유형 = ' <<학생 노드->첫 번째_속성('학생_유형')->값();
비용 <<끝;
// 학생 이름에 대해 상호작용
~을위한(xml_node *학생_이름_노드=학생 노드->첫 번째 노드('이름');학생_이름_노드;학생_이름_노드=학생_이름_노드->next_sibling())
{
비용 << '학생 이름 = ' <<학생_이름_노드->값();
비용 <<끝;
}
비용 <<끝;
}
반품 0;
}
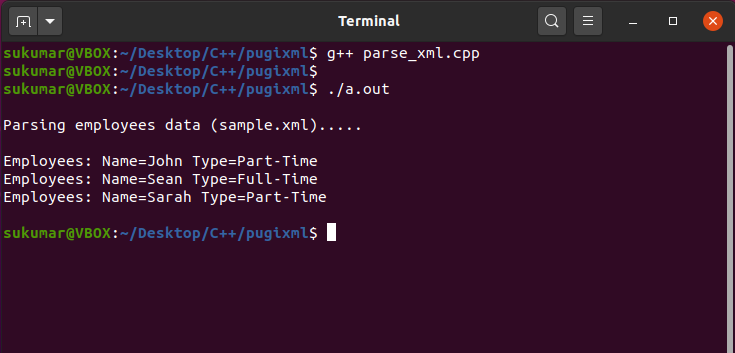
예-2: PugiXML을 사용하여 C++에서 XML 구문 분석
이 예제 프로그램에서는 C++에서 PugiXML 라이브러리를 사용하여 xml을 구문 분석하는 방법을 보여줍니다. 다음은 입력 XML 파일(sample.xml)입니다.
버전='1.0' 부호화='UTF-8' 독립형='아니요' ?>>
>
>
>
>
이 예제 프로그램에서는 C++에서 pugixml 라이브러리를 사용하여 xml을 구문 분석하는 방법을 보여줍니다. PugiXML 라이브러리는 다음에서 다운로드할 수 있습니다. 여기 .
#포함하다#include 'pugixml.hpp'
사용 네임스페이스시간;
사용 네임스페이스푸기;
정수기본()
{
비용 << 'N직원 데이터 파싱(sample.xml).....NN';
xml_document 문서;
// XML 파일 로드
만약 (!문서.load_file('샘플.xml')) 반품 -1;
xml_node tools=문서.아이('직원 데이터').아이('직원');
~을위한 (xml_node_iterator=도구.시작하다();그것!=도구.끝(); ++그것)
{
비용 << '직원:';
~을위한 (xml_attribute_iterator ait=그것->속성_시작();귀속!=그것->속성_종료(); ++귀속)
{
비용 << '' <<귀속->이름() << '=' <<귀속->값();
}
비용 <<끝;
}
비용 <<끝;
반품 0;
}
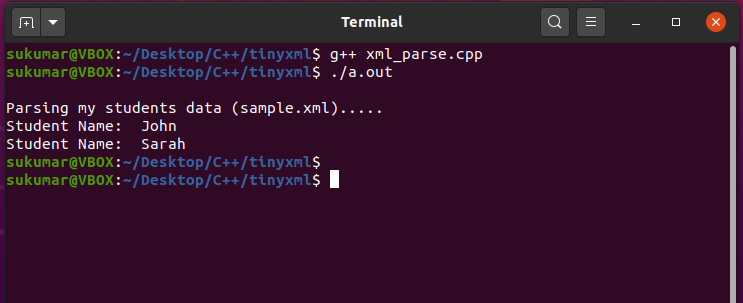
예-3: TinyXML을 사용하여 C++에서 XML 구문 분석
이 예제 프로그램에서는 C++에서 TinyXML 라이브러리를 사용하여 xml을 구문 분석하는 방법을 보여줍니다. 다음은 입력 XML 파일(sample.xml)입니다.
버전='1.0' 부호화='utf-8'?>>
이 예제 프로그램에서는 C++에서 TinyXML 라이브러리를 사용하여 xml을 구문 분석하는 방법을 보여줍니다. 다음에서 TinyXML 라이브러리를 다운로드할 수 있습니다. 여기 .
#포함하다#포함하다
#포함하다
#include 'tinyxml2.cpp'
사용 네임스페이스시간;
사용 네임스페이스작은 XML2;
정수기본(무효의)
{
비용 << 'N내 학생 데이터 파싱(sample.xml).....' <<끝;
// sample.xml 파일 읽기
XML문서 문서;
문서.로드파일( '샘플.xml' );
상수 숯*제목=문서.FirstChild요소( 'MyStudentsData' )->FirstChild요소( '학생' )->텍스트 가져오기();
인쇄( '학생 이름: %sN', 제목);
XML텍스트*텍스트 노드=문서.LastChild요소( 'MyStudentsData' )->LastChild요소( '학생' )->첫째 아이()->텍스트();
제목=텍스트 노드->값();
인쇄( '학생 이름: %sN', 제목);
반품 0;
}
결론
이 기사에서 우리는 간략하게 논의했습니다 XML C++에서 XML을 구문 분석하는 방법에 대한 세 가지 다른 예를 살펴보았습니다. TinyXML은 XML 데이터를 구문 분석하기 위한 최소한의 라이브러리입니다. 대부분의 프로그래머는 주로 RapidXML 또는 PugiXML을 사용하여 XML 데이터를 구문 분석합니다.