이번 글에서는 할당 방법에 대해 알아보겠습니다. 다른 '를 통한 메모리 pytorch_cuda_alloc_conf ' 방법.
PyTorch의 “pytorch_cuda_alloc_conf” 메서드는 무엇입니까?
기본적으로 “ pytorch_cuda_alloc_conf ”는 PyTorch 프레임워크 내의 환경 변수입니다. 이 변수를 사용하면 사용 가능한 처리 리소스를 효율적으로 관리할 수 있습니다. 즉, 가능한 최소한의 시간 내에 모델을 실행하고 결과를 생성합니다. 제대로 수행되지 않으면 ' 다른 ” 계산 플랫폼에 “ 기억이 부족하다 ” 오류가 발생하고 런타임에 영향을 미칩니다. 대용량 데이터에 대해 학습해야 하는 모델 또는 ' 배치 크기 ” 기본 설정이 충분하지 않을 수 있으므로 런타임 오류가 발생할 수 있습니다.
“ pytorch_cuda_alloc_conf ” 변수는 다음과 같은 “를 사용합니다. 옵션 '를 사용하여 리소스 할당을 처리합니다.
- 토종의 : 이 옵션은 PyTorch에서 이미 사용 가능한 설정을 사용하여 진행 중인 모델에 메모리를 할당합니다.
- max_split_size_mb : 지정된 크기보다 큰 코드 블록이 분할되지 않도록 합니다. 이는 ' 분열 '. 이 기사에서는 데모를 위해 이 옵션을 사용할 것입니다.
- roundup_power2_divisions : 이 옵션은 할당 크기를 가장 가까운 “ 2의 거듭제곱 ”를 메가바이트(MB) 단위로 나눕니다.
- roundup_bypass_threshold_mb: 지정된 임계값보다 많은 요청 목록에 대한 할당 크기를 반올림할 수 있습니다.
- 쓰레기_수집_임계값 : 모두 회수 프로토콜이 시작되지 않도록 GPU에서 사용 가능한 메모리를 실시간으로 활용하여 지연 시간을 방지합니다.
'pytorch_cuda_alloc_conf' 방법을 사용하여 메모리를 할당하는 방법은 무엇입니까?
상당한 규모의 데이터 세트가 있는 모든 모델에는 기본적으로 설정된 것보다 더 큰 추가 메모리 할당이 필요합니다. 모델 요구 사항과 사용 가능한 하드웨어 리소스를 고려하여 사용자 지정 할당을 지정해야 합니다.
'를 사용하려면 아래 단계를 따르십시오. pytorch_cuda_alloc_conf ” 복잡한 기계 학습 모델에 더 많은 메모리를 할당하기 위한 Google Colab IDE의 메소드:
1단계: Google Colab 열기
구글을 검색해 보세요 협업 브라우저에서 ' 새 노트북 ' 작업을 시작하려면 다음 단계를 따르세요.
2단계: 사용자 정의 PyTorch 모델 설정
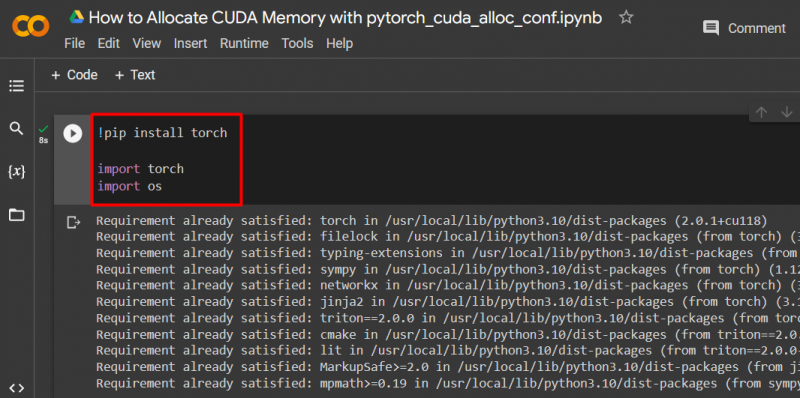
'를 사용하여 PyTorch 모델을 설정합니다. !씨 ” 설치 패키지를 사용하여 “ 토치 ” 도서관과 “ 수입 '가져오기 명령' 토치 ' 그리고 ' 너 ” 라이브러리를 프로젝트에 추가:
수입 토치
우리를 수입하다
이 프로젝트에는 다음 라이브러리가 필요합니다.
- 토치 – 이는 PyTorch의 기반이 되는 기본 라이브러리입니다.
- 너 – “ 운영 체제 ” 라이브러리는 “와 같은 환경 변수와 관련된 작업을 처리하는 데 사용됩니다. pytorch_cuda_alloc_conf ” 뿐만 아니라 시스템 디렉터리와 파일 권한도 다음과 같습니다.
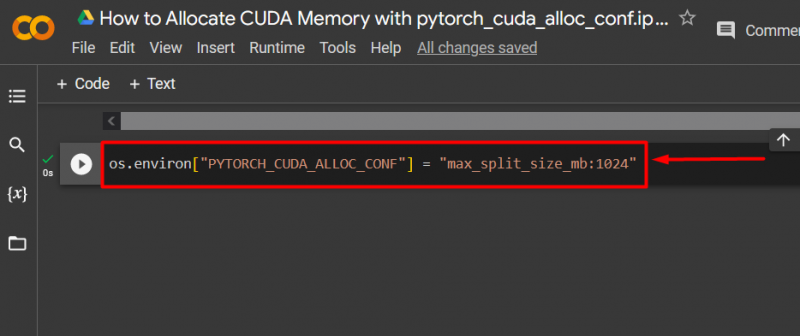
3단계: CUDA 메모리 할당
사용 ' pytorch_cuda_alloc_conf '를 사용하여 최대 분할 크기를 지정하는 방법입니다. max_split_size_mb ':
4단계: PyTorch 프로젝트 계속하기
'를 지정한 후 다른 ”를 사용한 공간 할당 “ max_split_size_mb ' 옵션을 선택하면 '에 대한 두려움 없이 정상적으로 PyTorch 프로젝트 작업을 계속할 수 있습니다. 기억이 부족하다 ” 오류.
메모 : 여기에서 Google Colab 노트북에 액세스할 수 있습니다. 링크 .
전문가의 팁
앞서 언급한 바와 같이 “ pytorch_cuda_alloc_conf ” 메소드는 위에 제공된 옵션 중 하나를 사용할 수 있습니다. 딥 러닝 프로젝트의 특정 요구 사항에 따라 사용하세요.
성공! 우리는 방금 “ pytorch_cuda_alloc_conf ” 메서드를 사용하여 “ max_split_size_mb ” PyTorch 프로젝트의 경우.
결론
사용 ' pytorch_cuda_alloc_conf ” 모델의 요구 사항에 따라 사용 가능한 옵션 중 하나를 사용하여 CUDA 메모리를 할당하는 방법입니다. 이러한 옵션은 각각 더 나은 런타임과 원활한 작업을 위해 PyTorch 프로젝트 내의 특정 처리 문제를 완화하기 위한 것입니다. 이 기사에서는 '를 사용하는 구문을 보여주었습니다. max_split_size_mb ” 옵션을 사용하여 분할의 최대 크기를 정의합니다.