이 게시물에서는 PostgreSQL 파티셔닝을 다룹니다. 사용할 수 있는 다양한 파티셔닝 옵션에 대해 논의하고 더 나은 이해를 위해 사용 방법에 대한 예를 제공합니다.
PostgreSQL 파티션을 만드는 방법
모든 데이터베이스에는 여러 항목이 포함된 수많은 테이블이 포함될 수 있습니다. 손쉬운 관리를 위해 테이블을 분할해야 합니다. 이는 데이터베이스 최적화와 안정성을 지원하는 훌륭하고 권장되는 데이터 웨어하우스 루틴입니다. 목록, 범위, 해시를 포함하여 다양한 파티션을 생성할 수 있습니다. 각각에 대해 자세히 논의해 보겠습니다.
1. 목록 분할
파티셔닝을 고려하기 전에 파티션에 사용할 테이블을 생성해야 합니다. 테이블을 생성할 때 모든 파티션에 대해 지정된 구문을 따르십시오.
CREATE TABLE 테이블_이름(column1 데이터_유형, 컬럼2 데이터_유형) PARTITION BY <파티션_유형>(파티션_키);
'table_name'은 테이블에 포함될 다양한 열과 해당 데이터 유형과 함께 테이블의 이름입니다. 'partition_key'의 경우 파티셔닝이 발생하는 열입니다. 예를 들어, 다음 이미지는 세 개의 열이 있는 'courses' 테이블을 생성했음을 보여줍니다. 또한 분할 유형은 LIST이고 분할 키로 교수진 열을 선택합니다.

테이블이 생성되면 필요한 다양한 파티션을 생성해야 합니다. 이를 위해 다음 구문을 진행하십시오.
CREATE TABLE partition_table VALUES IN(VALUE)에 대한 main_table의 PARTITION;예를 들어, 다음 이미지의 첫 번째 예는 값이 'FSET'인 파티션 키로 선택한 'faculty' 열의 모든 값을 보유하는 'Fset'이라는 파티션 테이블을 생성했음을 보여줍니다. 우리가 만든 다른 두 파티션에도 비슷한 논리를 사용했습니다.
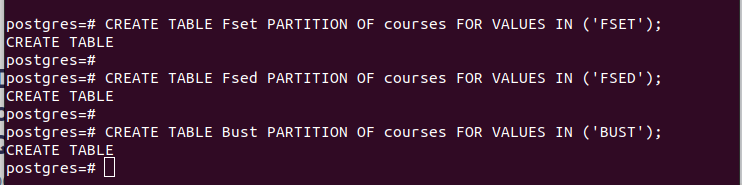
파티션이 있으면 우리가 만든 기본 테이블에 값을 삽입할 수 있습니다. 삽입하는 각 값은 선택한 파티션 키의 값을 기반으로 하는 해당 분할과 일치합니다.
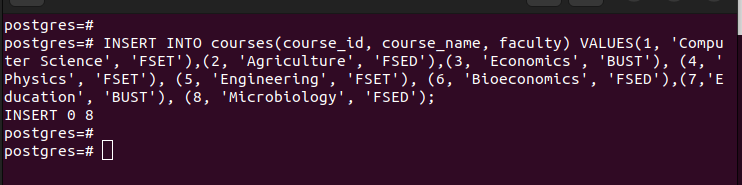
기본 테이블의 모든 항목을 나열하면 삽입한 모든 항목이 있음을 알 수 있습니다.
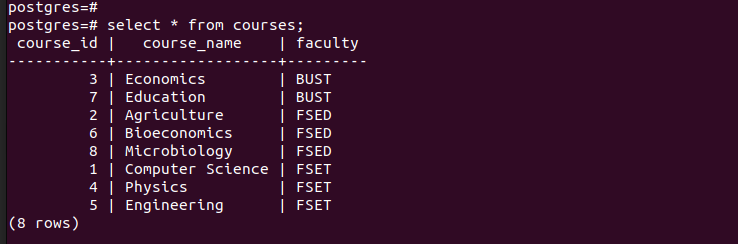
파티션이 성공적으로 생성되었는지 확인하기 위해 생성된 각 파티션의 기록을 확인해 보겠습니다.
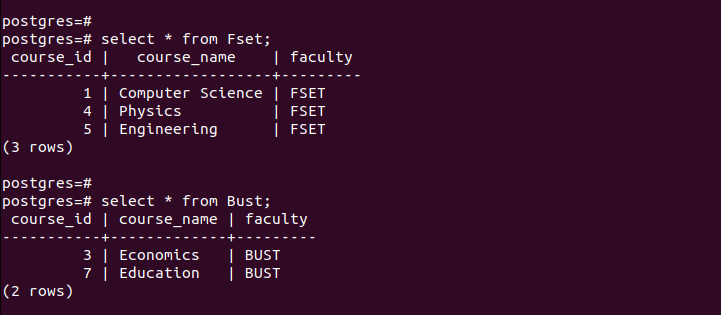
분할된 각 테이블에는 분할 시 정의된 기준과 일치하는 항목만 보관됩니다. 이것이 목록별 분할이 작동하는 방식입니다.
2. 범위 분할
파티션을 생성하는 또 다른 기준은 RANGE 옵션을 사용하는 것입니다. 이를 위해 범위에 사용할 시작 및 끝 값을 지정해야 합니다. 이 방법을 사용하는 것은 날짜 작업에 이상적입니다.
기본 테이블을 생성하는 구문은 다음과 같습니다.
CREATE TABLE 테이블_이름(column1 데이터_유형, 컬럼2 데이터_유형) PARTITION BY RANGE(파티션_키);“cust_orders” 테이블을 생성하고 날짜를 “partition_key”로 사용하도록 지정했습니다.

파티션을 생성하려면 다음 구문을 사용하십시오.
CREATE TABLE partition_table PARTITION OF main_table FOR VALUES FROM (start_value) TO (end_value);'날짜' 열을 사용하여 분기별로 작동하도록 파티션을 정의했습니다.
모든 파티션을 생성하고 데이터를 삽입한 후 테이블은 다음과 같습니다.
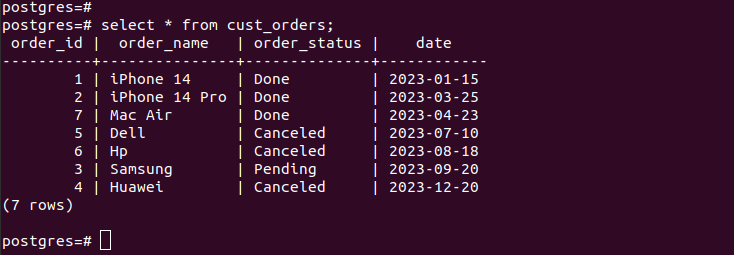
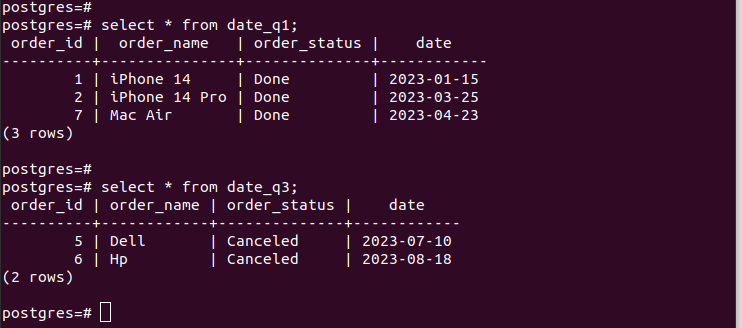
생성된 파티션의 항목을 확인하면 파티셔닝이 작동하고 지정한 파티셔닝 기준에 따라 적절한 레코드만 있는지 확인할 수 있습니다. 테이블에 추가하는 모든 새 항목은 해당 파티션에 자동으로 추가됩니다.
3. 해시 파티셔닝
우리가 논의할 마지막 분할 기준은 해시를 사용하는 것입니다. 다음 구문을 사용하여 기본 테이블을 빠르게 생성해 보겠습니다.
CREATE TABLE 테이블 이름(열1 데이터 유형, 열2 데이터_유형) PARTITION BY HASH(파티션_키); 
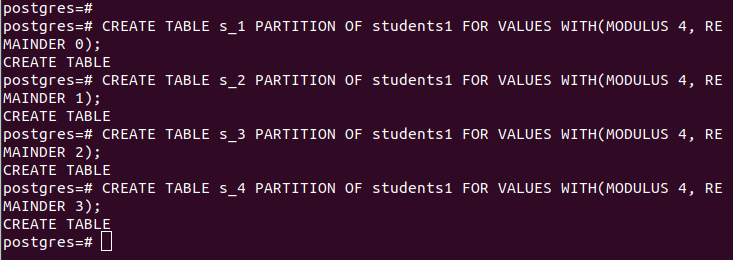
해시로 파티셔닝할 때 모듈러스와 나머지, 즉 지정된 'partition_key'의 해시 값으로 나눌 행을 제공해야 합니다. 우리의 경우 모듈러스 4를 사용합니다.
우리의 구문은 다음과 같습니다:
CREATE TABLE partition_table PARTITION OF main_table FOR VALUES WITH (MODULUS num1, REMAINDER num2);우리의 파티션은 다음과 같습니다:
“main_table”의 경우 다음과 같은 항목이 포함됩니다.
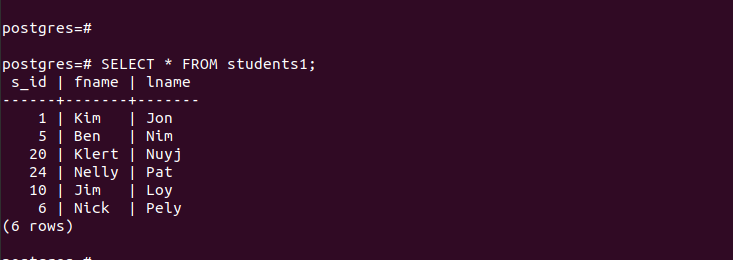
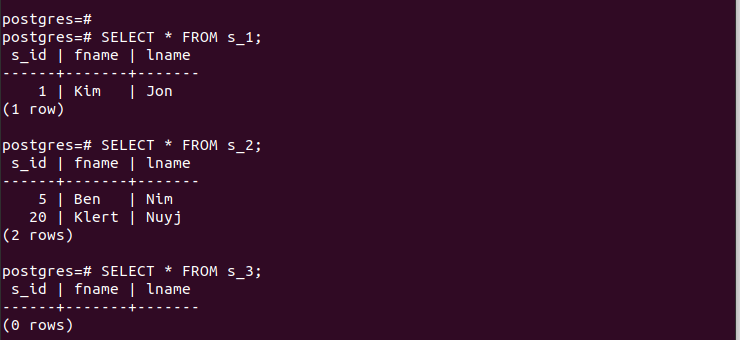
생성된 파티션의 경우 해당 항목에 빠르게 액세스하여 파티셔닝이 작동하는지 확인할 수 있습니다.
결론
PostgreSQL 파티션은 데이터베이스를 최적화하여 시간을 절약하고 안정성을 향상시키는 편리한 방법입니다. 우리는 사용 가능한 다양한 옵션을 포함하여 파티셔닝에 대해 자세히 논의했습니다. 또한 파티션을 구현하는 방법에 대한 예도 제공했습니다. 시험해 보세요!