“pandas”에서는 “pandas” 메서드를 사용하여 텍스트 파일을 쉽게 읽을 수 있습니다. 'Pandas'는 텍스트 파일을 읽을 수 있는 기회를 제공합니다. 'Pandas'는 텍스트 파일을 읽기 위한 다양한 내장 방법을 제공합니다. 여기의 모든 매개변수와 함께 이 자습서의 모든 방법에 대해 논의하고 자세히 설명합니다. 또한 여기 코드에서 'pandas' 메서드를 사용하여 'pandas'의 텍스트 파일을 읽습니다.'
'pandas'에서 텍스트 파일을 읽는 방법
'pandas'에는 텍스트 파일을 읽는 데 도움이 되는 세 가지 방법이 있습니다. 또한 여기에서 텍스트 파일을 읽는 몇 가지 예를 수행했습니다. 'pandas'가 제공하는 방법은 아래에 설명되어 있습니다.
-
- pd.read_csv() 메서드를 사용합니다.
- pd.read_table() 메서드를 사용합니다.
- pd.read_fwf() 메서드를 사용합니다.
이제 이 모든 메서드의 구문을 설명하고 이 자습서에서 모든 메서드의 매개 변수에 대해서도 자세히 설명합니다.
read_csv() 구문
pd.read_csv ( '파일 이름.txt', 9월 =' ', 헤더 =없음, 이름 = [ 'Col_name1', 'Col_name2, 'Col_name2', ....... ] )
이 방법에서는 먼저 데이터를 읽고자 하는 텍스트 파일의 이름을 추가하고 이것이 이 방법의 첫 번째 매개변수입니다. 그런 다음 이 방법에서 구분 기호인 'sep'를 배치하고 여기에 공백을 문자로 배치하여 공백을 구분 기호로 간주하도록 합니다. 그 후 header 매개변수가 있고 이 매개변수의 'None' 값이 사용되므로 기본 헤더를 생성하고 이 매개변수를 추가하지 않으면 텍스트 파일의 첫 번째 줄을 고려합니다. 헤더로. 'names' 매개변수에서 헤더로 추가해야 하는 열 이름을 추가할 수 있습니다.
read_table() 구문
pd.read_table ( '파일명.txt' , 구분 기호 = ' ' )
이 방법에서는 텍스트 파일의 파일 이름을 첫 번째 매개변수로 넣습니다. 구분 기호에서 ' '를 배치하면 공백 문자를 구분 기호로 사용합니다.
read_fwf() 구문
pd.read_fwf ( '파일명.txt' )
이 메서드는 텍스트 파일의 이름인 매개변수를 하나만 사용합니다.
이제 'pandas' 코드에서 텍스트 파일을 읽고 터미널에 텍스트 파일의 데이터를 표시하기 위해 이러한 방법을 사용할 것입니다.
예 # 01
'Spyder' 앱은 이 튜토리얼에서 제공하는 모든 코드를 수행한 곳입니다. 읽고자 하는 데이터의 텍스트 파일은 아래와 같습니다. 'pandas'에서 이 텍스트 파일을 읽기 위해 'read_csv()' 메서드를 사용합니다.
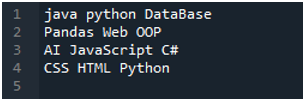
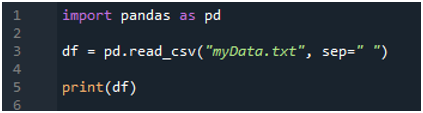
'read_csv()' 메서드를 활용하고 싶기 때문에 'pandas' 라이브러리를 먼저 가져옵니다. 이것이 'pandas' 메서드입니다. 'pandas' 라이브러리를 가져온 경우에만 이 메서드에 액세스합니다. 여기에서는 'pandas as pd'를 언급하므로 이 'pd'는 사용 방법의 이름과 함께 배치됩니다. 그런 다음 여기에서 읽은 후 텍스트 파일의 데이터를 저장하는 데 사용되는 변수 'df'를 만듭니다. 텍스트 파일을 읽고 텍스트 파일 데이터를 DataFrame으로 변환하고 'df' 변수에 저장하는 데 도움이 되는 'pd.read_csv()' 메서드를 여기에 배치합니다.
여기에 'myData.txt'라는 파일 이름을 전달한 다음 'sep'를 사용하고 이 'sep'에 공백 문자를 할당합니다. 따라서 이 공백 문자는 텍스트 파일에서 구분 기호로 작동합니다. 그런 다음 텍스트 파일의 데이터를 인쇄하는 데 사용되는 아래의 'print()'를 활용했습니다. DataFrame 형식으로 텍스트 파일의 데이터를 표시합니다.
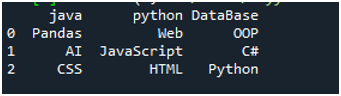
이 코드를 실행하려면 'Shift+Enter'를 눌러야 하며 출력은 'Spyder's' 터미널에서 렌더링됩니다. 위 코드의 결과는 주어진 스크린샷에 표시되며 텍스트 파일의 데이터가 DataFrame으로 표시되고 텍스트 파일의 첫 번째 줄이 여기에 해당 DataFrame의 열 이름으로 표시되는 것을 볼 수 있습니다. 또한 텍스트 파일에서 공백 문자가 있는 데이터를 구분합니다.
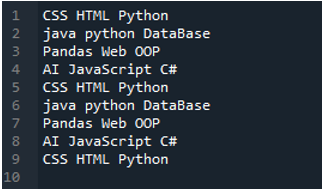
예 # 02
이 예제에서 읽을 텍스트 파일이 여기에 표시되며 'read_csv()' 메서드를 다시 사용하지만 다른 매개변수를 사용합니다.
'pandas' 메소드 'pd.read_csv()'가 사용되며 여기에 세 개의 매개변수를 전달합니다. 먼저 'Record.txt'라는 파일 이름을 배치합니다. 두 번째 매개변수는 'sep' 매개변수이고 여기에 공백 문자를 할당합니다. 그런 다음 'header'를 설정하고 'None'으로 조정하는 세 번째 매개변수가 있으므로 DataFrame의 기본 헤더를 생성합니다. 이 코드를 실행할 때. 이 모든 것을 'My_Record' 변수에 저장했고 인쇄를 위해 'print()' 함수에 'My_Record'도 추가했습니다.

모든 데이터는 DataFrame에 저장되며 텍스트 파일 데이터에서 공백 문자가 있는 데이터를 구분합니다. 또한 'header' 매개변수를 'None'으로 조정했기 때문에 여기에 DataFrame의 기본 헤더를 생성했습니다.
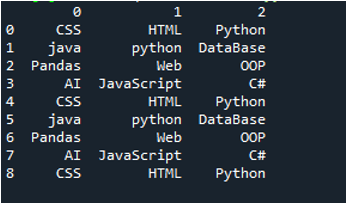
예 # 03
이 예제의 텍스트 파일이 표시되며 수정된 매개변수와 함께 'read_csv()' 메서드를 다시 한 번 사용합니다.
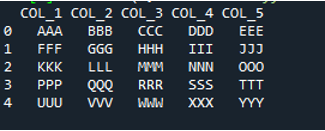
이 코드에서 4개의 매개변수가 'pandas' 메소드 'pd.read_csv()'에 전달됩니다. 텍스트 파일의 이름은 첫 번째 매개변수입니다. 'sep' 매개변수에는 두 번째 매개변수에 공백 문자가 지정됩니다. 세 번째 인수는 'header' 매개변수가 'None'으로 설정되어 있고, 네 번째 매개변수는 텍스트 파일을 읽은 후 DataFrame의 열 이름으로 나타날 '이름'을 설정했으며 이러한 열 이름은 다음과 같습니다. 'COL_1, COL_2, COL_3, COL_4 및 COL_5'. 이 모든 정보는 'My_Record' 변수에 저장되었으며 'My_Record'도 'print()' 메서드에 추가되어 터미널에서 인쇄됩니다.

여기서 텍스트 파일의 모든 정보는 DataFrame으로 렌더링되며, 텍스트 파일에서 공백이 추가된 데이터도 분리합니다. 또한 위의 코드에서 추가한 열 이름을 그에 따라 추가합니다.
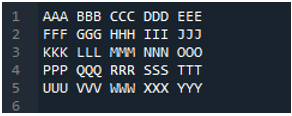
예 # 04
이것은 다른 방법인 'pd.read_table()' 방법을 사용하여 이 예제에서 읽을 텍스트 파일입니다.
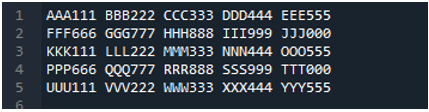
여기에 텍스트 파일을 읽기 위한 'pd.read_table()' 메소드를 추가하고, 텍스트 파일의 이름인 'ABC.txt'를 추가합니다. 이 방법은 텍스트 파일을 읽는 데 도움이 되며 'delimiter' 매개변수를 공백 문자로 조정하여 위에서 설명한 구분 기호처럼 작동합니다. 그러면 모든 텍스트의 파일 데이터가 'My_Data' 변수에 저장되고 여기에도 인쇄됩니다.

텍스트 파일의 첫 번째 줄은 여기에서 DataFrame의 열 이름으로 표시되고 텍스트 파일의 데이터는 DataFrame으로 인쇄됩니다. 또한 공백 문자가 있는 텍스트 파일의 데이터를 구분합니다.
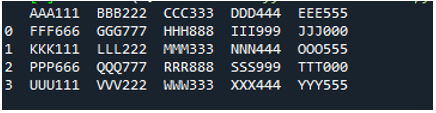
예 # 05
이제 텍스트 파일에는 아래에 표시된 데이터가 포함됩니다. 이번에는 'read_fwf()'를 적용하고 텍스트 파일을 읽은 후 데이터를 렌더링하는 방법을 보여줍니다.
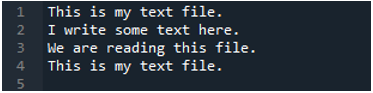
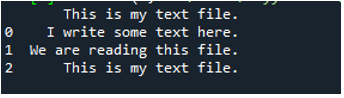
이 'read_fwf()' 메소드는 우리가 읽고자 하는 파일 이름인 하나의 매개변수만 취한다는 것을 알고 있습니다. 여기에 텍스트 파일의 이름인 'textfile.txt'를 추가하고 이 pandas 메서드를 이 텍스트 파일의 데이터를 저장할 'File_Data' 변수에 할당합니다. 그런 다음 'print(File_Data)'를 넣어 이 데이터도 인쇄합니다.

여기에는 텍스트 파일의 모든 데이터가 표시됩니다. 이 함수에는 'Sep' 또는 'delimiter'와 같은 매개변수가 없기 때문에 공백 문자가 있는 데이터를 분리하지 않았습니다.
결론
이 튜토리얼에서는 'pandas'에서 텍스트 파일을 읽는 방법과 'pandas'에서 텍스트 파일을 읽는 데 사용되는 방법에 대해 설명합니다. 우리는 'pandas'에서 텍스트 파일을 읽는 데 도움이 되는 모든 방법에 대해 논의했습니다. 이 튜토리얼에서 'pandas'의 텍스트 파일을 읽기 위한 'pandas'의 세 가지 방법을 살펴보았습니다. 우리는 또한 모든 메소드의 구문과 모든 메소드의 매개변수를 여기에서 자세히 설명했으며 이 튜토리얼에서 가능한 모든 매개변수와 함께 다른 메소드를 적용하여 많은 텍스트 파일을 읽었습니다.