통사론:
이동 평균은 다음과 같은 다양한 방법으로 계산할 수 있습니다.
방법 1:
넘파이. 정액 ( )주어진 배열에 있는 요소의 합을 반환합니다. cumsum()의 출력을 배열의 크기로 나누어 이동 평균을 계산할 수 있습니다.
방법 2:
넘파이. 그리고 . 평균 ( )다음과 같은 매개변수가 있습니다.
a: 평균을 낼 배열 형태의 데이터.
axis: 데이터 유형은 int이고 선택적 매개변수입니다.
weight: 배열이자 선택적 매개변수이기도 합니다. 1차원 모양과 같은 모양일 수 있습니다. 1차원의 경우 'a' 배열과 길이가 같아야 합니다.
NumPy에는 이동 평균을 계산하는 표준 함수가 없는 것 같으므로 다른 방법으로 수행할 수 있습니다.
방법 3:
이동 평균을 계산하는 데 사용할 수 있는 또 다른 방법은 다음과 같습니다.
예를 들어 말다 ( ㅏ , 안에 , 방법 = '가득한' )이 구문에서 a는 첫 번째 입력 차원이고 v는 두 번째 입력 차원 값입니다. 모드는 선택적 값이며 전체, 동일 및 유효할 수 있습니다.
예 # 01:
이제 Numpy의 이동 평균에 대해 더 자세히 설명하기 위해 예를 들어보겠습니다. 이 예에서는 NumPy의 convolve 함수를 사용하여 배열의 이동 평균을 가져옵니다. 따라서 1,2,3,4,5를 요소로 하는 배열 'a'를 사용합니다. 이제 np.convolve 함수를 호출하고 그 출력을 'b' 변수에 저장합니다. 그런 다음 변수 'b'의 값을 인쇄합니다. 이 함수는 입력 배열의 이동 합계를 계산합니다. 출력이 올바른지 여부를 확인하기 위해 출력을 인쇄합니다.
그런 다음 동일한 컨볼브 방법을 사용하여 출력을 이동 평균으로 변환합니다. 이동 평균을 계산하려면 이동 합계를 샘플 수로 나누어야 합니다. 그러나 여기서 주요 문제는 이것이 이동 평균이므로 샘플 수가 우리가 있는 위치에 따라 계속 변한다는 것입니다. 따라서 이 문제를 해결하려면 단순히 분모 목록을 만들고 이를 평균으로 변환해야 합니다.
이를 위해 분모에 대해 또 다른 변수 'denom'을 초기화했습니다. 범위 트릭을 사용하여 목록 이해에 간단합니다. 배열에는 5개의 다른 요소가 있으므로 각 위치의 샘플 수는 1에서 5로 이동한 다음 다시 5에서 1로 줄어듭니다. 따라서 두 개의 목록을 함께 추가하고 'denom' 매개변수에 저장합니다. 이제 이 변수를 인쇄하여 시스템이 진정한 분모를 제공했는지 여부를 확인합니다. 그런 다음 이동 합계를 분모로 나누고 출력을 'c' 변수에 저장하여 인쇄합니다. 코드를 실행하여 결과를 확인합시다.
수입 numpy ~처럼 예를 들어ㅏ = [ 1 , 둘 , 삼 , 4 , 5 ]
비 = 예를 들어 말다 ( ㅏ , 예를 들어 one_like ( ㅏ ) )
인쇄 ( '이동합계' , 비 )
이름 = 목록 ( 범위 ( 1 , 5 ) ) + 목록 ( 범위 ( 5 , 0 , - 1 ) )
인쇄 ( '분모' , 이름 )
씨 = 예를 들어 말다 ( ㅏ , 예를 들어 one_like ( ㅏ ) ) / 이름
인쇄 ( '이동 평균 ' , 씨 )
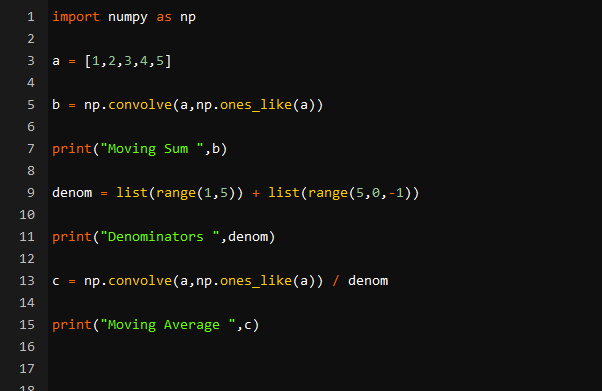
코드를 성공적으로 실행하면 다음과 같은 결과를 얻을 수 있습니다. 첫 번째 줄에는 '이동 합계'가 인쇄되었습니다. 원래 배열에서와 마찬가지로 배열의 시작 부분에 '1'이 있고 끝 부분에 '5'가 있음을 알 수 있습니다. 나머지 숫자는 배열의 다른 요소의 합입니다.
예를 들어, 배열의 세 번째 인덱스에 있는 6은 입력 배열에서 1,2, 3을 더한 것입니다. 네 번째 색인의 10은 1,2,3, 4에서 나옵니다. 15는 모든 숫자를 합산하는 식으로 진행됩니다. 이제 출력의 두 번째 줄에서 배열의 분모를 인쇄했습니다.
출력에서 모든 분모가 정확하다는 것을 알 수 있습니다. 즉, 이동 합계 배열로 나눌 수 있습니다. 이제 출력의 마지막 줄로 이동합니다. 마지막 줄에서 이동 평균 배열의 첫 번째 요소가 1임을 알 수 있습니다. 1의 평균은 1이므로 첫 번째 요소가 정확합니다. 1+2/2의 평균은 1.5가 됩니다. 출력 배열의 두 번째 요소가 1.5이므로 두 번째 평균도 정확하다는 것을 알 수 있습니다. 1,2,3의 평균은 6/3=2가 됩니다. 또한 우리의 출력을 올바르게 만듭니다. 따라서 출력에서 배열의 이동 평균을 성공적으로 계산했다고 말할 수 있습니다.
결론
이 가이드에서 우리는 이동 평균에 대해 배웠습니다: 이동 평균이 무엇인지, 그 용도와 이동 평균을 계산하는 방법. 우리는 그것을 수학적 관점과 프로그래밍 관점에서 자세히 연구했습니다. NumPy에는 이동 평균을 계산하는 특정 기능이나 프로세스가 없습니다. 그러나 이동 평균을 계산할 수 있는 다른 기능이 있습니다. 우리는 이동 평균을 계산하는 예제를 만들고 예제의 모든 단계를 설명했습니다. 이동 평균은 기존 데이터의 도움으로 미래 결과를 예측하는 유용한 접근 방식입니다.