학생들의 데이터가 배열 형태로 저장되어 있고 실패한 학생들을 걸러내고 싶다고 가정해 봅시다. 단순히 배열을 필터링하고 실패한 학생을 제외하면 통과한 학생의 새 배열이 얻어집니다.
NumPy 배열을 필터링하는 단계
1 단계: NumPy 모듈 가져오기.
2 단계: 배열 생성.
3단계: 필터링 조건을 추가합니다.
4단계: 필터링된 새 배열을 만듭니다.
통사론:
배열을 필터링하는 방법에는 여러 가지가 있습니다. 하나의 조건만 있는 경우 또는 둘 이상의 조건이 있는 경우와 같이 필터의 조건에 따라 다릅니다.
방법 1: 하나의 조건에 대해 다음 구문을 따릅니다.
정렬 [ 정렬 < 상태 ]위에서 언급한 구문에서 '배열'은 요소를 필터링할 배열의 이름입니다. 조건은 요소가 필터링된 상태이고 연산자 '<'는 미만을 나타내는 수학적 기호입니다. 조건이나 문장이 하나만 있을 때 사용하는 것이 효율적입니다.
방법 2: 'OR' 연산자 사용
정렬 [ ( 정렬 < 조건1 ) | ( 정렬 > 조건2 ) ]이 방법에서 '배열'은 값을 필터링하고 조건이 전달되는 배열의 이름입니다. 연산자 '|' 두 조건에서 하나가 참이어야 함을 의미하는 'OR' 함수를 나타내는 데 사용됩니다. 두 가지 조건이 있을 때 유용합니다.
방법 3: 'AND' 연산자 사용.
정렬 [ ( 정렬 < 조건1 ) & ( 정렬 > 조건2 ) ]다음 구문에서 '배열'은 필터링할 배열의 이름입니다. 반면에 조건은 위의 구문에서 설명한 상태이며 '&'를 사용하는 연산자는 AND 연산자입니다. 이는 두 조건이 모두 참이어야 함을 의미합니다.
방법 4: 나열된 값으로 필터링
정렬 [ 예를 들어 in1d ( 정렬 , [ 값 목록 ] ) ]이 방법에서는 필터링할 배열의 요소가 다른 배열에 있는지 여부에 관계없이 두 배열을 비교하는 데 사용되는 정의된 배열 'np.in1d'를 전달했습니다. 그리고 배열은 주어진 배열에서 필터링될 np.in1d 함수로 전달됩니다.
예 # 01:
이제 위에서 설명한 방법을 예제로 구현해 보겠습니다. 먼저 Python에서 제공하는 NumPy 라이브러리를 포함합니다. 그런 다음 '2', '3', '1', '9', '3', '5', '6' 및 '1' 값을 포함하는 'my_array'라는 배열을 만듭니다. 다음으로 'my_array[(my_array < 5)]'인 필터 코드를 '5'보다 작은 값을 필터링한다는 의미인 print 문에 전달합니다. 다음 줄에서 '1', '2', '6', '3', '8', '1' 및 '0' 값을 갖는 'array'라는 이름의 또 다른 배열을 만들었습니다. print 문에 5보다 큰 값을 인쇄한다는 조건을 전달했습니다.
마지막으로 'arr'이라는 또 다른 배열을 만들었습니다. '6', '7','10', '12' 및 '14' 값을 보유하고 있습니다. 이제 이 배열에 대해 배열 내에 존재하지 않는 값을 인쇄하여 조건이 일치하지 않을 경우 어떤 일이 발생하는지 확인합니다. 이를 위해 '5' 값과 같은 값을 필터링하는 조건을 전달했습니다.
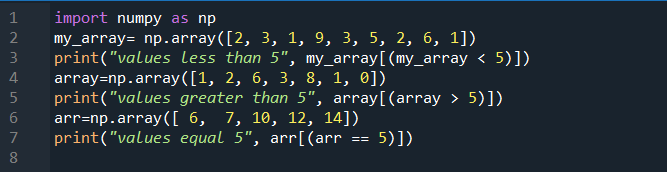
수입 numpy ~처럼 예를 들어my_array = 예를 들어 정렬 ( [ 둘 , 삼 , 1 , 9 , 삼 , 5 , 둘 , 6 , 1 ] )
인쇄 ( '5보다 작은 값' , my_array [ ( my_array < 5 ) ] )
정렬 = 예를 들어 정렬 ( [ 1 , 둘 , 6 , 삼 , 8 , 1 , 0 ] )
인쇄 ( '5보다 큰 값' , 정렬 [ ( 정렬 > 5 ) ] )
아 = 예를 들어 정렬 ( [ 6 , 7 , 10 , 12 , 14 ] )
인쇄 ( '값은 5와 같습니다' , 아 [ ( 아 == 5 ) ] )
코드를 실행한 후 결과적으로 다음과 같은 출력을 얻었습니다. 여기서 3개의 출력을 표시했습니다. 첫 번째 출력은 '5'보다 큰 값을 인쇄한 두 번째 실행에서 '5'보다 작은 요소에 대한 것입니다. 마지막에는 존재하지 않는 값을 출력했는데 오류가 표시되지 않고 빈 배열이 표시되는데, 이는 원하는 값이 주어진 배열에 존재하지 않는다는 것을 의미합니다.

예 # 02:
이 경우 배열을 필터링하기 위해 둘 이상의 조건을 사용할 수 있는 몇 가지 방법을 사용할 것입니다. 이를 수행하기 위해 NumPy 라이브러리를 가져온 다음 '24', '3', '12', '9', '3', '5' 값을 갖는 '9' 크기의 1차원 배열을 생성합니다. '2', '6' 및 '7'입니다. 다음 줄에서는 조건을 인수로 사용하여 'my_array'라는 이름으로 초기화한 배열을 전달한 print 문을 사용했습니다. 여기에서 우리는 둘 다에서 하나의 조건이 참이어야 함을 의미하는 or 조건을 전달했습니다. 둘 다 참이면 두 조건에 대한 데이터를 표시합니다. 이 조건에서 '5'보다 작고 '9'보다 큰 값을 인쇄하려고 합니다. 다음 줄에서는 AND 연산자를 사용하여 조건을 사용하여 배열을 필터링할 경우 어떤 일이 발생하는지 확인했습니다. 이 조건에서 '5'보다 크고 '9'보다 작은 값을 표시했습니다.
numpy 가져오기 ~처럼 예를 들어my_array = 예를 들어 정렬 ( [ 24 , 삼 , 12 , 9 , 삼 , 5 , 둘 , 6 , 7 ] )
인쇄 ( '보다 작은 값 5 또는 ~보다 큰 9 ' , my_array [ ( my_array < 5 ) | ( my_array > 9 ) ] )
인쇄 ( '보다 큰 가치 5 그리고 미만 9 ' , my_array [ ( my_array > 5 ) & ( my_array < 9 ) ] )

아래 스니펫에서 볼 수 있듯이 위의 코드에 대한 결과가 표시되어 배열을 필터링하고 다음 결과를 얻었습니다. 보시다시피 9보다 크고 5보다 작은 값이 첫 번째 출력에 표시되고 5와 9 사이의 값은 무시됩니다. 반면에 다음 줄에서는 '5'와 '9' 사이의 값인 '6'과 '7'을 인쇄했습니다. 배열의 다른 값은 표시되지 않습니다.

결론
이 가이드에서는 NumPy 패키지에서 제공하는 필터 방법의 사용에 대해 간략하게 논의했습니다. numpy에서 제공하는 필터 방법론을 구현하는 가장 좋은 방법에 대해 자세히 설명하기 위해 여러 예제를 구현했습니다.