예 1:
설명할 그림과 MongoDB 셸에서 '$max' 연산자가 작동하는 방식부터 시작하여 이미 생성되어야 하는 'data'라는 컬렉션이 있어야 합니다. 이 컬렉션을 만들려면 '만들기' 명령을 사용하지 않고 일부 레코드를 직접 추가해야 합니다. 삽입 명령어는 컬렉션을 생성하고 그 안에 레코드를 추가하기에 충분합니다. 쿼리에서 'insertMany' 함수를 사용하여 각각 다른 유형의 4개 필드가 있는 4개의 레코드를 추가합니다.
시험 > db.data.insertMany ( [ { 'ID' : 하나 , '이름' : '브라보' , '샐러리' : 65000 , '나이' : 44 } ,... { 'ID' : 2 , '이름' : '스티븐' , '샐러리' : 77000 , '나이' : 55 } ,
... { 'ID' : 삼 , '이름' : '마리아' , '샐러리' : 42000 , '나이' : 27 } ,
... { 'ID' : 4 , '이름' : '호킨' , '샐러리' : 58000 , '나이' : 33 } ] )
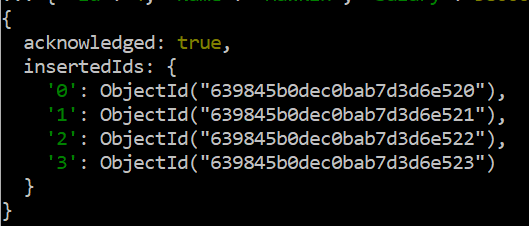
삽입 명령이 성공하고 출력 메시지에 레코드가 추가되었음을 표시합니다.
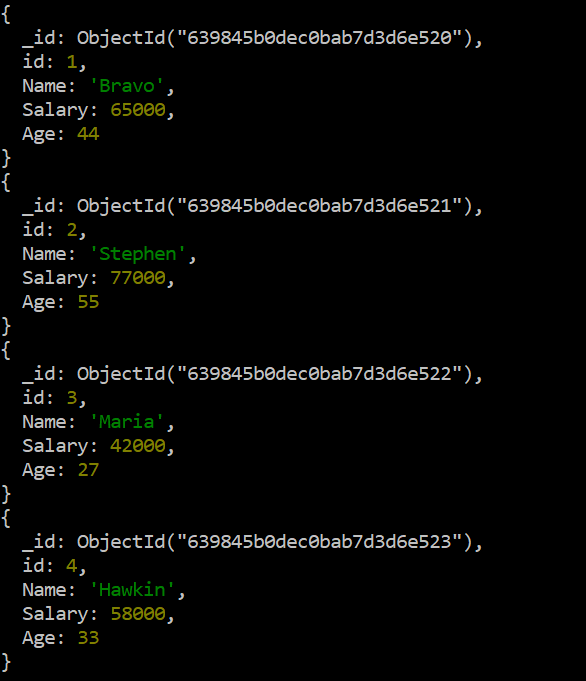
MongoDB의 '데이터' 컬렉션에 레코드를 삽입한 후에는 해당 레코드를 셸에서 볼 차례입니다. 따라서 MongoDB Cli에서 'find()' 함수 명령을 실행한 다음 'forEach()' 함수를 실행하고 printjson 인수를 사용하여 결과를 JSON 형식으로 표시합니다. 셸에 표시되는 결과는 다음 출력 이미지에 표시된 컬렉션의 총 4개 문서를 보여줍니다.
시험 > db.data.find ( ) .각각 ( 프린트 json )
이미 삽입된 레코드를 수정하기 위해 MongoDB의 업데이트 명령에서 '$max' 연산자를 사용해 봅시다. 따라서 updateOne()은 'id' 필드 값이 '2'인 특정 레코드와 같은 '데이터' 컬렉션의 단일 레코드만 수정하는 데 사용됩니다. '$max' 연산자는 '데이터' 컬렉션의 'Salary' 필드에 적용되어 'Salary' 필드의 값이 55000보다 큰지 확인합니다. 그렇지 않은 경우 레코드를 55000으로 업데이트합니다. 이에 대한 출력 결과 레코드 '2'가 55000 급여 값 미만이므로 '0' 수정 횟수를 표시하는 updateOne() 함수 쿼리입니다.
시험 > db.data.updateOne ( { ID: 2 } , { $최대 : { 샐러리: 55000 } } ) 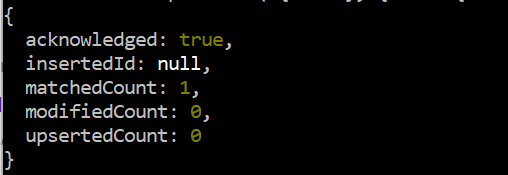
이 업데이트 후에는 동일한 'find()' 함수 쿼리를 시도하여 수정된 결과를 MongoDB 명령줄 셸에 표시합니다. 그러나 '업데이트' 명령을 사용하기 전에 얻은 것과 동일한 출력을 얻습니다. 77000 값이 55000보다 크기 때문에 변화가 없습니다.
시험 > db.data.find ( ) .각각 ( 프린트 json ) 
동일한 updateOne() 쿼리를 약간 수정하여 다시 한 번 시도해 봅시다. 이번에는 'data' 컬렉션의 'Salary' 필드에 이미 상주하는 '77000' 값보다 더 큰 '85000' 값을 시도하여 출력에 차이를 만듭니다. 이 쿼리의 '$max' 연산자 때문에 비교가 발생한 후 '85000' 값이 필드에 이미 상주하는 '77000' 값을 대체하므로 이번에는 수정 횟수 '1'이 출력에 표시됩니다.
시험 > db.data.updateOne ( { ID: 2 } , { $최대 : { 샐러리: 85000 } } ) 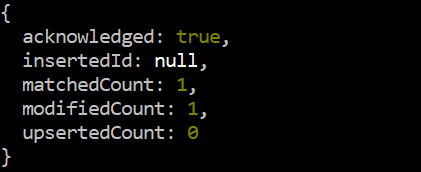
MongoDB의 '$max' 연산자를 통해 '77000'의 작은 값을 새 값 '85000'으로 성공적으로 교체한 후 마지막으로 'db' 명령의 'find()' 함수를 사용하여 이 업데이트를 확인합니다. 성공적으로 업데이트되었는지 여부. 출력은 이 컬렉션에 있는 두 번째 레코드의 'Salary' 필드 값이 완벽하게 업데이트되었음을 보여줍니다.
시험 > db.data.find ( ) .각각 ( 프린트 json ) 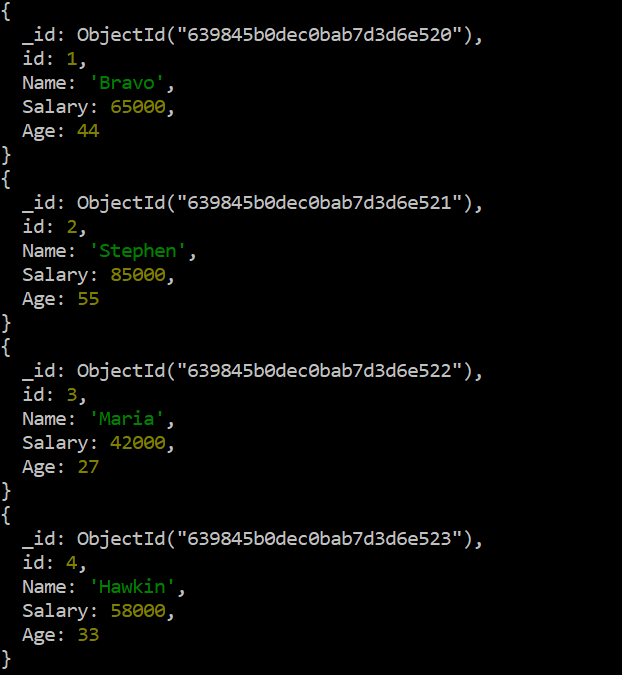
예 2:
MongoDB에서 '$max' 연산자를 사용하는 또 다른 예를 살펴보겠습니다. 이번에는 동일한 필드 값에 대한 중복 항목이 있는 경우 컬렉션의 고유한 레코드를 그룹화하고 표시하기 위해 '$max' 연산자를 캐스트합니다. 이를 위해 '테스트' 데이터베이스의 '데이터' 컬렉션에 2개의 레코드를 더 삽입합니다. 이 레코드에는 이미 삽입된 4개의 레코드에도 있는 '이름' 필드에 2개의 동일한 값이 포함되어 있으며 나머지는 다릅니다. 레코드를 삽입하기 위해 'data' 컬렉션이 업데이트되도록 'insertMany' 함수가 포함된 동일한 'db' 명령을 사용합니다.
시험 > db.data.insertMany ( [ { 'ID' : 5 , '이름' : '브라보' , '샐러리' : 35000 , '나이' : 오분의 사 } ,… { 'ID' : 6 , '이름' : '호킨' , '샐러리' : 67000 , '나이' : 33 } ] )
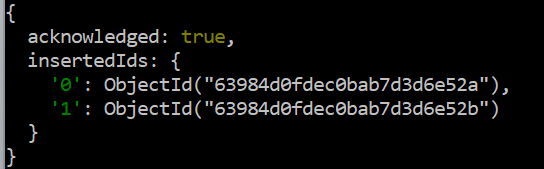
명령이 성공적으로 실행됩니다.
이제 2개의 새 레코드가 추가되었으므로 'db' 명령어에서 'forEach' 함수 뒤에 있는 동일한 '찾기' 함수를 사용하여 레코드를 표시할 수도 있습니다. 이미지의 다음 디스플레이 출력은 이 컬렉션의 끝에 있는 2개의 새 레코드를 보여줍니다.
시험 > db.data.find ( ) .각각 ( 프린트 json ) 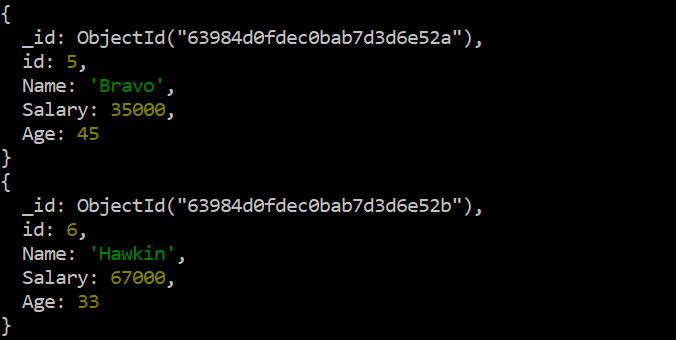
'데이터' 수집의 6개 레코드를 표시한 후 집계 기능을 수행할 준비가 된 것입니다. 따라서 '집계' 기능은 다음 나열된 쿼리에서 사용됩니다. 이 기능으로 '$group' 연산자를 사용하여 'id' 필드와 'Salary' 필드의 고유한 이름에 따라 '데이터' 컬렉션의 레코드를 그룹화합니다. '$max' 연산자는 레코드의 'Salary' 필드에 적용되어 표시할 최대값을 가져옵니다. 표시할 이 그룹화의 'id'로 사용되는 'Name' 필드의 중복 이름에 따라 Salary' 필드에서 가장 큰 값을 가져옵니다. 총 4개의 레코드가 표시됩니다. 가장 큰 값이 표시되는 동안 가장 작은 값(중복 레코드에서)은 무시됩니다.
db.data.aggregate ( [ { $그룹 : { _ID: ' $이름 ' , 샐러리: { $최대 : ' $급여 ' } } } ] ) 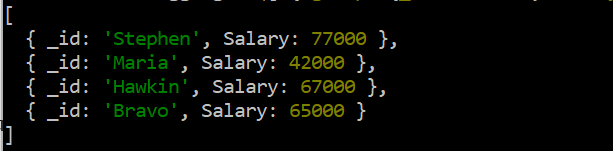
결론
이 가이드의 첫 번째 단락은 MongoDB에서 사용되는 연산자, 특히 “$max” 연산자와 MongoDB 셸에서의 사용법의 중요성을 이해하는 데 도움이 됩니다. 이 안내서에는 '$max' 연산자와 관련된 두 가지 명령 기반 예제가 포함되어 목적을 보여줍니다. MongoDB 그림을 살펴보면 이미 존재하는 레코드를 새 값으로 바꾸거나 '$max' 연산자를 통해 레코드를 그룹화하여 레코드를 표시하는 등 데이터베이스에서 몇 가지 유용한 트랜잭션을 수행할 수 있습니다.