MongoDB는 쿼리 결과를 어떻게 정렬합니까?
정렬 방법은 필드와 관련 값을 단일 매개변수로 사용합니다. 정렬 방법은 {Field: Value}와 같은 JSON 형식의 매개변수를 허용합니다. 컬렉션에서 정렬된 문서를 가져오기 위해 여러 필드와 값을 sort() 메서드에 입력할 수도 있습니다. 데이터베이스에 다른 많은 문서를 삽입한 다음 문서를 고려하십시오. 이 MongoDB 데이터베이스의 이름은 'Employees'입니다. 'Employees' 컬렉션에는 아래 표시된 직원의 모든 정보가 있습니다.
db.Employees.insertMany([{
'이름': '로버트',
'생년월일': '14-05-1993',
'성별 남성',
'이메일': ' [이메일 보호됨] ',
'부서': '보안',
'급여' : 5000
},
{
'이름': '카일',
'생년월일': '1999년 5월 31일',
'성별 여성',
'이메일': ' [이메일 보호됨] ',
'부서': 'IT',
'월급' : 6200
},
{
'이름': '매튜',
'생년월일': '1993년 4월 26일',
'성별 남성',
'이메일': ' [이메일 보호됨] ',
'부서': '계정',
'급여' : 3500
},
{
'이름': '케빈',
'생년월일': '14-07-1991',
'성별 남성',
'이메일': ' [이메일 보호됨] ',
'부서': '보안',
'월급' : 4500
},
{
'이름': '줄리아',
'생년월일': '09-12-2000',
'성별 여성',
'이메일': ' [이메일 보호됨] ',
'부서': 'IT',
'월급' : 2500
}
])
'Employee' 컬렉션이 제공된 문서와 함께 삽입되며 다음 출력에 확인이 표시됩니다. 정렬 쿼리 결과의 기능을 보여주기 위해 이 컬렉션 문서를 사용할 것입니다.
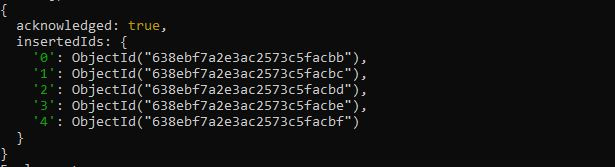
예제 # 1: MongoDB 정렬되지 않은 컬렉션
find() 메서드로 검색 쿼리를 실행하면 항상 정렬되지 않은 문서 모음이 제공됩니다. 이는 아래에 제공된 쿼리 결과로 더 명확해질 수 있습니다.
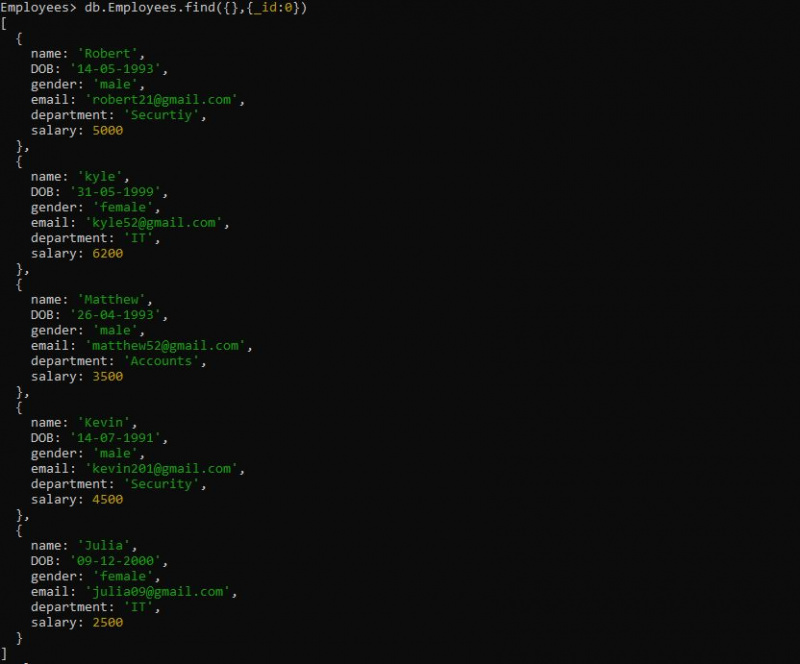
>db.Employees.find({},{_id:0})
여기에는 find() 메서드를 사용하여 'Employee' 컬렉션에 대한 쿼리가 있습니다. find() 메서드는 '_id:0'과 함께 빈 매개변수를 사용합니다. 더 간단한 결과를 위해 '_id:0' 연산자를 사용하여 문서 ID를 제거합니다. 기본적으로 find() 메서드로 쿼리를 검색할 때 정렬되지 않은 컬렉션을 얻습니다. 아래에서 검색된 출력은 삽입 시점에 있는 방식으로 정렬되지 않은 모든 문서입니다.
예 # 2: 오름차순으로 된 MongoDB 정렬 쿼리 결과
MongoDB에서 정렬된 컬렉션은 find() 메서드 뒤에 배치되어야 하는 sort() 메서드를 사용하여 얻습니다. MongoDB의 sort() 메서드는 필드 이름과 문서 정렬 순서에 포함된 매개 변수를 사용합니다. 이 특정 예에서는 문서를 오름차순으로 검색하므로 필드에 매개변수로 '1'을 입력해야 합니다. 정렬 쿼리에서 다음은 오름차순입니다.
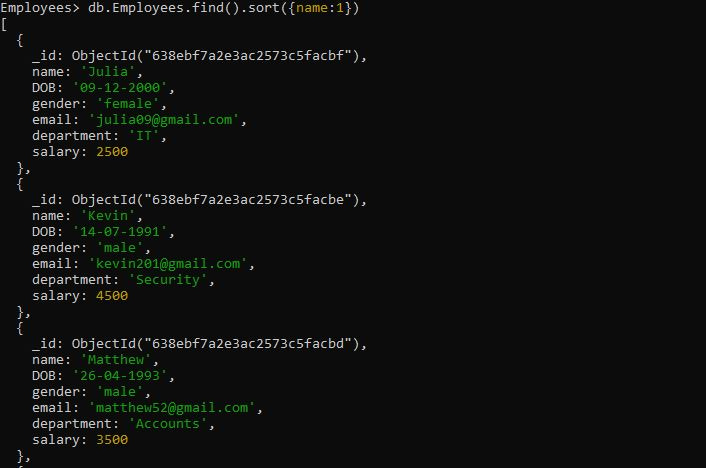
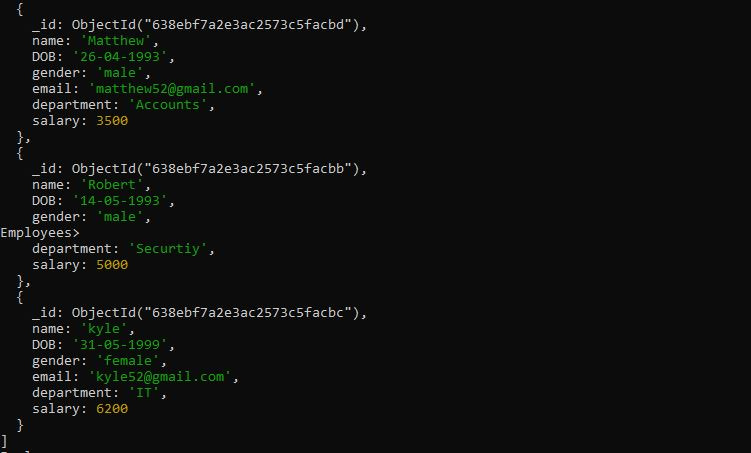
>db.Employees.find().sort({이름:1})
여기서는 찾기 검색어 다음에 sort() 메서드를 사용했습니다. sort() 메서드는 값 '1'이 지정된 필드 옆에 배치되므로 '이름' 필드를 오름차순으로 정렬하는 데 사용됩니다. sort() 메서드가 파라메트릭 값으로 지정되지 않으면 컬렉션이 정렬되지 않습니다. sort() 메서드의 출력은 기본 순서로 가져옵니다. 오름차순 이름 필드별 sort() 메서드의 결과는 다음 MongoDB 셸에 표시됩니다.
예 # 3: 내림차순으로 MongoDB 정렬 쿼리 결과
이제 MongoDB의 정렬 쿼리 결과를 내림차순으로 보여주고 있습니다. 이러한 종류의 쿼리는 위의 예와 동일하지만 한 가지 차이점이 있습니다. 내림차순의 경우 sort() 메서드는 열 이름에 대해 '-1' 값을 사용합니다. 내림차순 정렬 쿼리 결과는 다음과 같습니다.
>db.Employees.find({},{'email':1,_id:0}).sort({'email':-1})여기서 검색 쿼리는 'email' 필드를 찾고 'email' 필드 값만 반환하는 find() 메서드로 시작합니다. 다음으로 'email' 필드를 정렬하는 데 사용되는 sort() 메서드를 지정했으며 그 옆에 있는 값 '-1'은 얻은 정렬 결과가 내림차순임을 나타냅니다. 내림차순 정렬 쿼리 결과는 MongoDB 셸에서 실행한 후 가져옵니다.

예 # 4: 여러 필드에 대한 MongoDB 정렬 쿼리 결과
sort() 메서드를 사용하여 MongoDB의 여러 필드를 정렬할 수 있습니다. 정렬할 필드는 sort() 메서드에서 선언해야 합니다. 정렬은 필드의 선언 순서를 기반으로 하며 정렬 순서는 왼쪽에서 오른쪽으로 검사됩니다. 여러 필드를 정렬하기 위한 쿼리는 다음과 같아야 합니다.
>db.Employees.find({},{_id:0}).sort({'name':1,'salary':1})여기서 sort() 메서드는 정렬할 '이름' 및 '급여' 필드와 함께 전달됩니다. 'Employee' 컬렉션의 'name' 필드는 sort() 메서드의 첫 번째 인수 필드이기 때문에 먼저 정렬됩니다. 그런 다음 sort() 메서드는 두 번째 인수 필드인 'salary'를 정렬합니다. 두 필드의 순서는 정렬이 오름차순임을 나타내는 '1'입니다. 정렬 쿼리의 여러 필드에 대한 출력은 아래 지정된 정렬 순서로 생성됩니다.
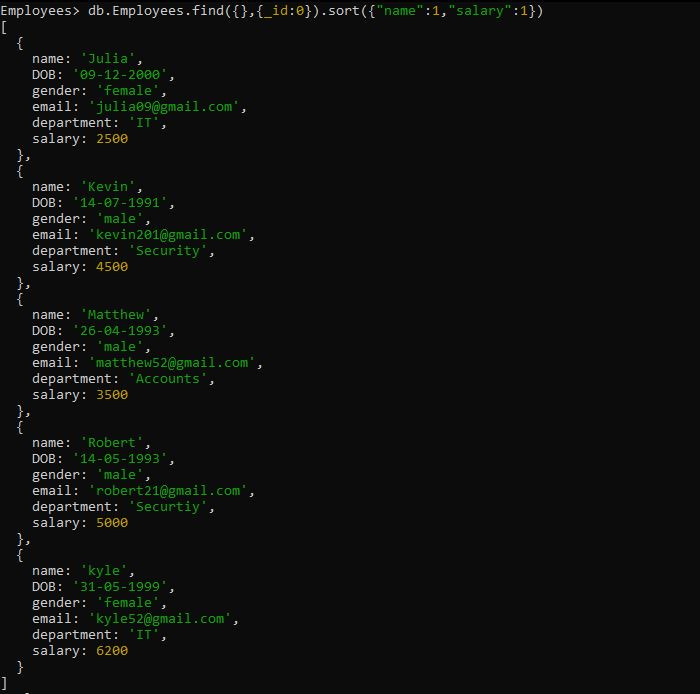
예 # 5: 제한 방법을 사용한 MongoDB 정렬 쿼리 결과
또한 sort() 메서드는 해당 검색 쿼리에 의해 정렬된 문서의 제한된 수를 제공하는 limit() 메서드와 결합할 수도 있습니다. limit() 메소드는 출력 세트에 포함되어야 하는 문서의 수를 제한하는 정수를 매개변수로 요구합니다. 검색 쿼리는 아래에 설정되어 문서를 먼저 정렬한 다음 지정된 제한 문서를 제공합니다.
>db.Employees.find({},{_id:0}).sort({'department':1,'DOB':1}).limit(4).pretty()여기에는 'department' 열에 대한 정렬 작업을 시작한 다음 sort() 메서드를 사용하여 오름차순으로 'DOB' 열에 대한 정렬 작업을 시작하는 검색 쿼리가 있습니다. 정렬이 완료되면 제한된 문서를 검색하기 위해 그 옆에 limit() 메서드를 배치했습니다. limit() 메서드에는 숫자 값 '4'가 지정되며 이는 다음 화면과 같이 정렬된 문서 4개만 출력에 표시함을 의미합니다.
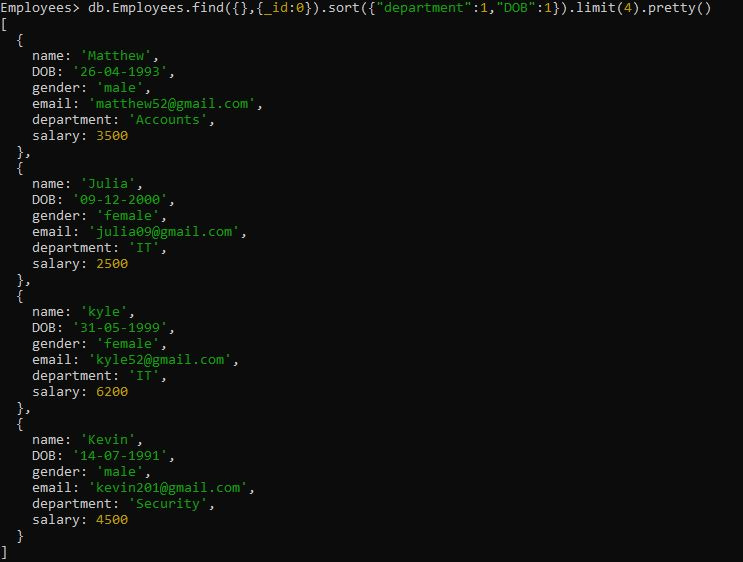
예 # 6: $sort 집계를 사용한 MongoDB 정렬 쿼리 결과
위의 모든 예제에서는 MongoDB의 sort() 메서드를 통해 정렬을 수행했습니다. MongoDB에는 $sort 집계를 통해 수행되는 또 다른 정렬 방법이 있습니다. $sort 연산자는 모든 입력 문서를 정렬한 다음 정렬된 문서를 파이프라인으로 반환합니다. $sort 연산자는 아래 'Employees' 컬렉션에 적용됩니다.
db.Employees.aggregate([ { $sort : { 급여 : 1, _id: -1 } } ])여기에서 '$sort' 연산자를 활용할 수 있는 집계 메서드를 호출했습니다. 그런 다음 'salary' 열을 오름차순으로 정렬하고 'id' 열을 내림차순으로 정렬하는 $sort 연산자 표현식이 있습니다. 필드에 적용된 $sort 집계는 다음 결과를 출력합니다.
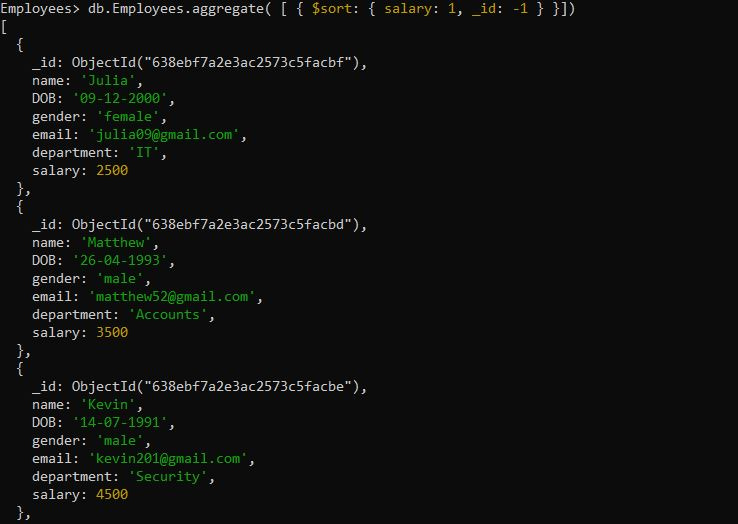

예제 # 6: 건너뛰기 방법을 사용한 MongoDB 정렬 쿼리 결과
sort() 메서드는 skip() 메서드와 쌍을 이룰 수도 있습니다. 결과 데이터 세트에는 skip() 메서드를 사용하여 무시되는 특정 수의 문서가 있을 수 있습니다. limit() 메서드와 마찬가지로 skip() 메서드도 건너뛸 문서 수를 나타내는 숫자 값을 허용합니다. 정렬 쿼리에서 sort() 메서드를 skip() 메서드와 결합했습니다.
>db.Employees.find({},{_id:0}).sort({'salary':1}).skip(4).pretty()여기에서는 sort() 메서드 옆에 skip() 메서드를 사용했습니다. sort() 메서드가 문서를 정렬할 때 정렬 출력을 sort() 메서드에 전달합니다. 그런 다음 skip() 메서드는 처음 4개의 정렬된 문서를 컬렉션에서 제거했습니다.
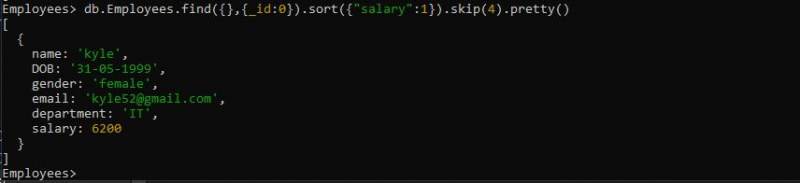
결론
이 기사는 MongoDB의 정렬 쿼리 결과에 관한 것입니다. 이 목적을 위해 지정된 순서로 레코드를 구성하는 sort() 메서드를 사용했습니다. 또한 여러 필드에서 다중 정렬을 위해 sort() 메서드를 사용했습니다. 그런 다음 sort() 메서드는 이러한 작업을 사용하여 정렬된 문서에 대한 limit() 및 skip() 메서드와 쌍을 이룹니다. 또한 MongoDB에서 정렬 쿼리 결과에 대한 $sort 집계를 제공했습니다.