컬렉션 만들기
인덱스를 사용하기 전에 MongoDB에 새 컬렉션을 만들어야 합니다. 우리는 이미 하나를 만들고 'Dummy'라는 이름의 문서 10개를 삽입했습니다. find() MongoDB 함수는 아래 MongoDB 쉘 화면에 'Dummy' 컬렉션의 모든 레코드를 표시합니다.
테스트> db.Dummy.find() 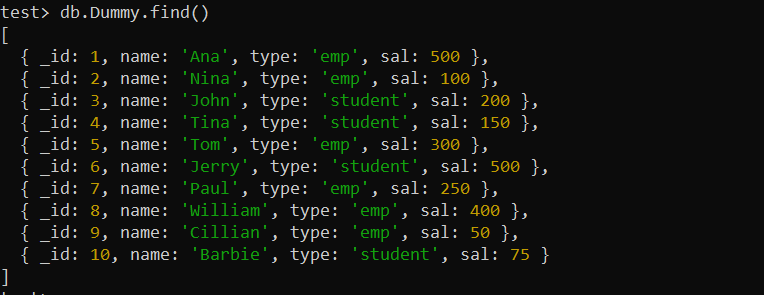
인덱싱 유형 선택
인덱스를 설정하기 전에 먼저 쿼리 기준에 공통적으로 활용될 컬럼을 결정해야 합니다. 인덱스는 자주 필터링, 정렬 또는 검색되는 열에서 좋은 성능을 발휘합니다. 큰 카디널리티(다양한 값)가 있는 필드는 우수한 인덱싱 옵션인 경우가 많습니다. 다음은 다양한 인덱스 유형에 대한 몇 가지 코드 예제입니다.
예제 01: 단일 필드 인덱스
단일 열을 인덱싱하여 해당 열의 쿼리 속도를 향상시키는 가장 기본적인 유형의 인덱스일 것입니다. 이 유형의 인덱스는 단일 키 필드를 사용하여 컬렉션 레코드를 쿼리하는 쿼리에 사용됩니다. 아래와 같이 find 함수 내에서 'Dummy' 컬렉션의 레코드를 조회하기 위해 'type' 필드를 사용한다고 가정합니다. 이 명령은 전체 컬렉션을 조사하므로 대규모 컬렉션을 처리하는 데 오랜 시간이 걸릴 수 있습니다. 따라서 이 쿼리의 성능을 최적화해야 합니다.
테스트> db.Dummy.find({유형: '엠프' })
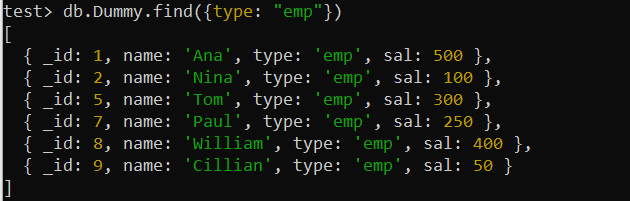
위의 Dummy 컬렉션 기록은 '유형' 필드, 즉 조건이 포함된 필드를 사용하여 발견되었습니다. 따라서 여기에서는 단일 키 인덱스를 활용하여 검색 쿼리를 최적화할 수 있습니다. 따라서 우리는 MongoDB의 createIndex() 함수를 사용하여 'Dummy' 컬렉션의 'type' 필드에 인덱스를 생성할 것입니다. 이 쿼리를 사용하는 그림은 셸에서 'type_1'이라는 단일 키 인덱스가 성공적으로 생성된 것을 보여줍니다.
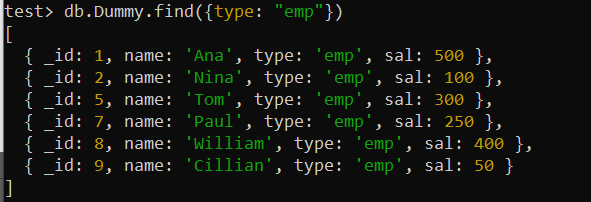
테스트> db.Dummy.createIndex({ 유형: 1 })'type' 필드를 활용하여 find() 쿼리를 사용해 보겠습니다. MongoDB가 인덱스를 활용하여 요청된 직위의 레코드를 신속하게 검색할 수 있기 때문에 인덱스가 있으므로 이전에 사용했던 find() 함수보다 이제 작업이 훨씬 더 빨라질 것입니다.
테스트> db.Dummy.find({유형: '엠프' })
예시 02: 복합 지수
특정 상황에서는 다양한 기준에 따라 항목을 찾고 싶을 수도 있습니다. 이러한 필드에 대한 복합 인덱스를 구현하면 쿼리 성능을 향상시키는 데 도움이 될 수 있습니다. 이번에는 쿼리가 표시될 때 서로 다른 검색 조건이 포함된 여러 필드를 사용하여 'Dummy' 컬렉션에서 검색하려고 한다고 가정해 보겠습니다. 이 쿼리는 'type' 필드가 'emp'로 설정되고 'sal' 필드가 350보다 큰 컬렉션에서 레코드를 검색했습니다.
$gte 논리 연산자는 'sal' 필드에 조건을 적용하는 데 사용되었습니다. 총 10개의 레코드로 구성된 전체 컬렉션을 검색한 결과 총 2개의 레코드가 반환되었습니다.
테스트> db.Dummy.find({유형: '엠프' , 살: {$gte: 350 } }) 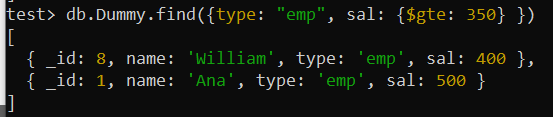
앞서 언급한 쿼리에 대한 복합 인덱스를 만들어 보겠습니다. 이 복합 인덱스에는 'type' 및 'sal' 필드가 있습니다. 숫자 '1'과 '-1'은 각각 'type' 및 'sal' 필드의 오름차순과 내림차순을 나타냅니다. 복합 인덱스 열의 순서는 중요하며 쿼리 패턴과 일치해야 합니다. MongoDB는 표시된 대로 이 복합 인덱스에 'type_1_sal_-1'이라는 이름을 지정했습니다.
테스트> db.Dummy.createIndex({ 유형: 1 , 할 것이다:- 1 }) 
동일한 find() 쿼리를 사용하여 'type' 필드 값이 'emp'이고 'sal' 필드 값이 350보다 큰 레코드를 검색한 후 순서가 약간 변경된 동일한 출력을 얻었습니다. 이전 쿼리 결과와 비교합니다. 이제 “sal” 필드에 대한 더 큰 값 레코드가 첫 번째 위치에 있는 반면, 위의 복합 인덱스에서 “sal” 필드에 대해 설정된 “-1”에 따라 가장 작은 값이 가장 낮은 레코드에 있습니다.
테스트> db.Dummy.find({유형: '엠프' , 살: {$gte: 350 } }) 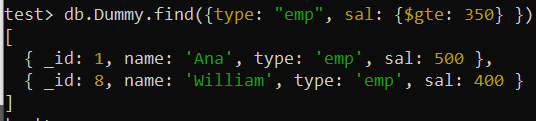
예시 03: 텍스트 인덱스
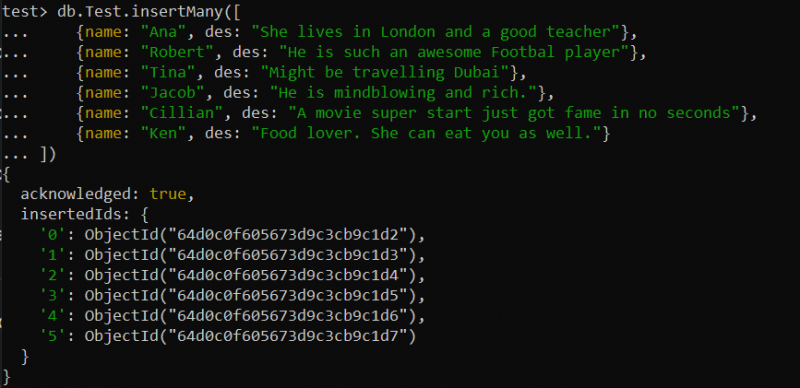
때로는 제품, 성분 등에 대한 자세한 설명과 같은 대규모 데이터 세트를 처리해야 하는 상황에 직면할 수 있습니다. 텍스트 인덱스는 큰 텍스트 필드에서 전체 텍스트 검색을 수행하는 데 유용할 수 있습니다. 예를 들어 테스트 데이터베이스 내에 'Test'라는 새 컬렉션을 만들었습니다. 아래 find() 쿼리에 따라 insertMany() 함수를 사용하여 이 컬렉션에 총 6개의 레코드를 삽입했습니다.
테스트> db.Test.insertMany([{이름: '어록' , 중: '그녀는 런던에 살고 있고 좋은 선생님이에요' },
{이름: '로버트' , 중: '그는 정말 대단한 축구선수야' },
{이름: '에서' , 중: '두바이를 여행하고 있을지도 몰라' },
{이름: '야곱' , 중: '그는 정말 멋지고 부자예요.' },
{이름: '킬리언' , 중: '영화 슈퍼 스타트는 단 몇 초 만에 명성을 얻었습니다.' },
{이름: '시야' , 중: '음식 애호가. 그녀도 당신을 먹을 수 있습니다.' }
])
이제 MongoDB의 createIndex() 함수를 사용하여 이 컬렉션의 'Des' 필드에 텍스트 인덱스를 생성하겠습니다. 필드 값의 키워드 'text'는 인덱스 유형, 즉 'text' 인덱스를 표시합니다. 인덱스 이름 des_text가 자동 생성되었습니다.
테스트> db.Test.createIndex({ des: '텍스트' })이제 find() 함수는 'des_text' 인덱스를 통해 컬렉션에 대한 '텍스트 검색'을 수행하는 데 사용되었습니다. $search 연산자는 수집 기록에서 'food'라는 단어를 검색하고 해당 특정 기록을 표시하는 데 사용되었습니다.
테스트> db.Test.find({ $text: { $search: '음식' }}); 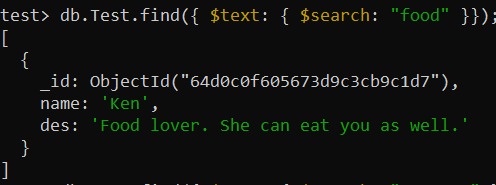
인덱스 확인:
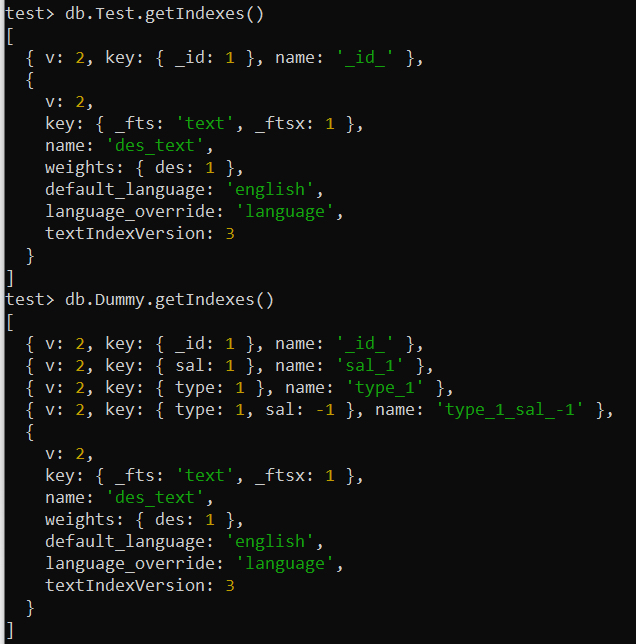
MongoDB에서 다양한 컬렉션에 적용된 모든 인덱스를 확인하고 나열할 수 있습니다. 이를 위해 MongoDB 쉘 화면에서 컬렉션 이름과 함께 getIndexes() 메소드를 사용하십시오. 우리는 'Test' 및 'Dummy' 컬렉션에 대해 이 명령을 별도로 사용했습니다. 이는 화면의 내장 및 사용자 정의 색인에 관한 모든 필수 정보를 표시합니다.
테스트> db.Test.getIndexes()테스트> db.Dummy.getIndexes()
하락 지수:
이제 인덱스가 적용된 동일한 필드 이름과 함께 dropIndex() 함수를 사용하여 컬렉션에 대해 이전에 생성된 인덱스를 삭제할 차례입니다. 아래 쿼리는 단일 인덱스가 제거되었음을 보여줍니다.
테스트> db.Dummy.dropIndex({유형: 1 }) 
같은 방법으로 복합 인덱스를 삭제할 수 있습니다.
테스트> db.Dummy.drop index({유형: 1 , 할 것이다: 1 }) 
결론
MongoDB에서 데이터 검색 속도를 높여서 쿼리 효율성을 높이기 위해서는 인덱싱이 필수적입니다. 인덱스가 부족하면 MongoDB는 전체 컬렉션에서 일치하는 레코드를 검색해야 하는데, 이는 세트 크기가 커질수록 효율성이 떨어집니다. 인덱스 데이터베이스 구조를 활용하여 올바른 레코드를 신속하게 검색하는 MongoDB의 기능은 적절한 인덱싱을 사용할 때 쿼리 처리 속도를 높입니다.