“쉼표로 구분된 값(CSV)은 가장 다양하고 사용하기 쉬운 데이터 형식 중 하나입니다. 개발자와 응용 프로그램이 한 소스에서 다른 소스로 데이터를 전송하고 구문 분석할 수 있는 경량 데이터 형식입니다.
CSV 데이터는 각 열이 쉼표로 구분되고 새 행에 새 레코드가 할당되는 테이블 형식으로 데이터를 저장합니다. 따라서 SQL 데이터베이스, Cassandra 데이터 등과 같은 데이터베이스 내보내기에 매우 적합합니다.
따라서 CSV 파일을 데이터베이스로 가져와야 하는 시나리오가 발생하는 것은 놀라운 일이 아닙니다.
이 튜토리얼의 목표는 Kibana 대시보드를 사용하여 CSV 파일을 Elasticsearch 클러스터로 가져오는 빠르고 간단한 방법을 보여주는 것입니다.'
뛰어들어봅시다.
요구 사항
다이빙하기 전에 다음 요구 사항이 있는지 확인하십시오.
- 녹색 상태의 Elasticsearch 클러스터.
- Elasticsearch 클러스터에 연결된 Kibana 서버.
- 클러스터의 인덱스를 관리할 수 있는 충분한 권한.
샘플 CSV 파일
평소와 같이 첫 번째 요구 사항은 소스 CSV 파일입니다. CSV 파일의 데이터 형식이 올바른지, 오류가 없는지 확인하는 것이 좋습니다.
설명을 위해 Amazon Prime의 영화와 TV 프로그램이 포함된 무료 데이터 세트를 사용합니다.
브라우저를 열고 아래 리소스로 이동합니다.
https://www.kaggle.com/datasets/shivamb/amazon-prime-movies-and-tv-shows
절차에 따라 데이터 세트를 로컬 컴퓨터에 다운로드합니다. 다음 명령을 사용하여 다운로드한 아카이브를 추출할 수 있습니다.
$ 압축을 풀다 ~ / 다운로드 / 아카이브.zip
CSV 파일 가져오기
소스 파일이 준비되면 계속 진행하고 가져오기 방법을 논의할 수 있습니다.
먼저 Kibana 홈 대시보드로 이동하여 '파일 업로드' 옵션을 선택하십시오.
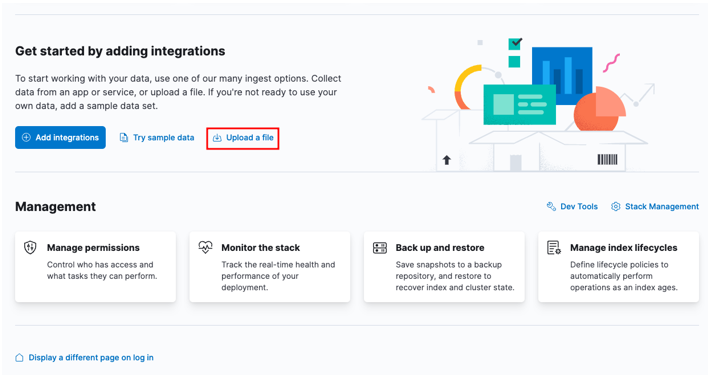
런처 창에서 가져올 대상 CSV 파일을 찾습니다.
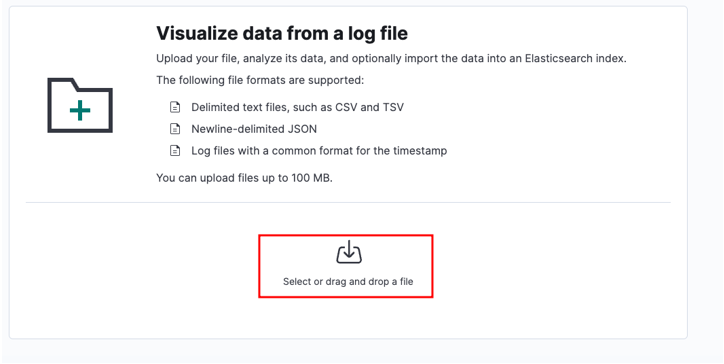
소스 파일을 선택하고 업로드를 클릭합니다.
Elasticsearch 및 Kibana가 업로드된 파일을 분석하도록 허용합니다. 이것은 CSV 파일을 구문 분석하고 데이터 형식, 필드, 데이터 유형 등을 결정합니다.
참고: 클러스터 구성 및 데이터 크기에 따라 이 프로세스는 시간이 걸릴 수 있습니다. 시간 초과를 피하기 위해 마스터 노드가 응답하는지 확인하십시오.
프로세스가 완료되면 Elastic에서 분석한 파일 콘텐츠 샘플과 파일 통계를 가져와야 합니다.
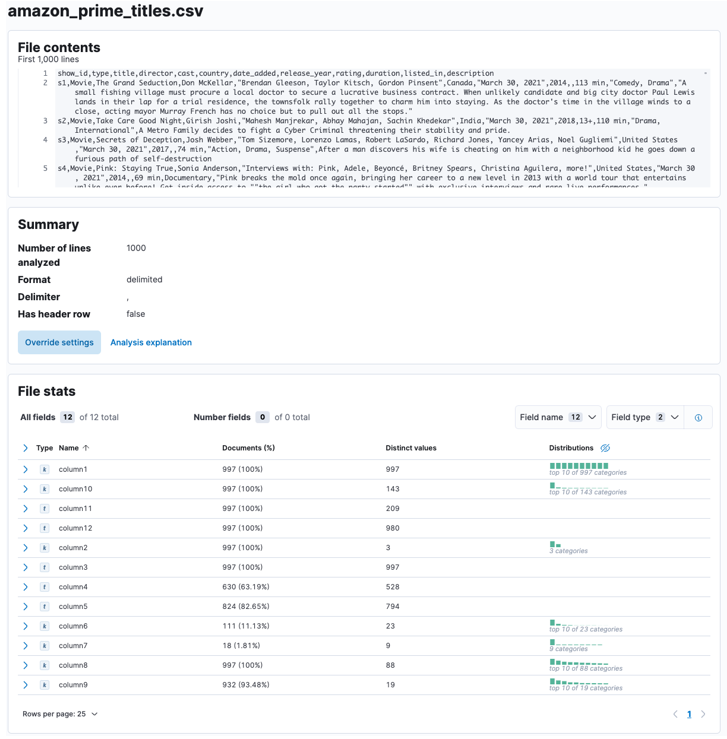
예를 들어 구분 기호, 헤더 행 등 다양한 매개변수를 사용자 지정할 수 있습니다. 예를 들어 위의 출력을 사용자 지정하여 CSV 파일에 헤더 파일이 포함되어 있음을 Elastic에 알릴 수 있습니다.
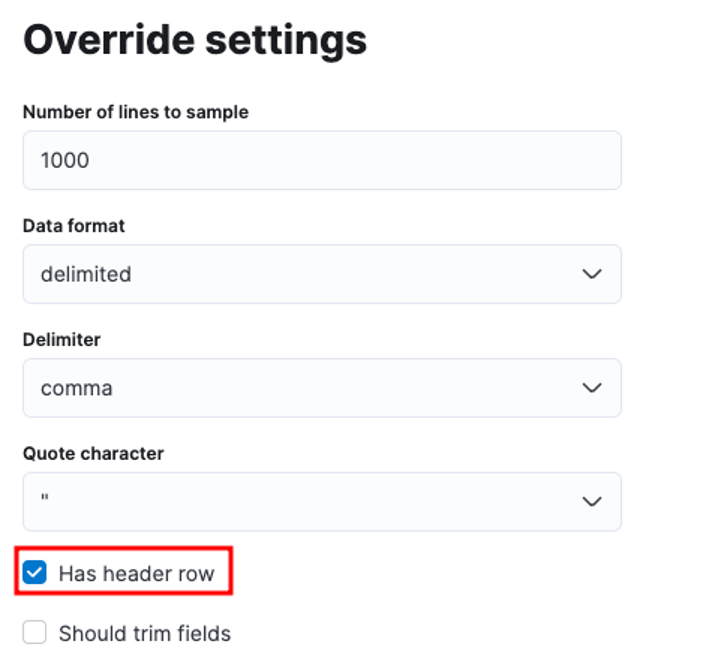
그런 다음 적용을 클릭하고 데이터를 다시 분석할 수 있습니다. 필드를 포함하여 올바른 형식으로 데이터를 포맷해야 합니다.
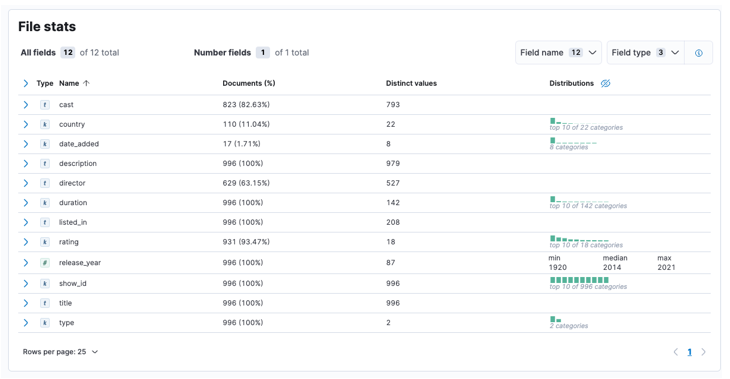
그런 다음 가져오기를 클릭하여 가져온 대시보드로 이동할 수 있습니다.
여기서 CSV 데이터가 저장되는 인덱스를 생성해야 합니다. 지원되는 모든 이름을 색인에 할당할 수 있습니다.
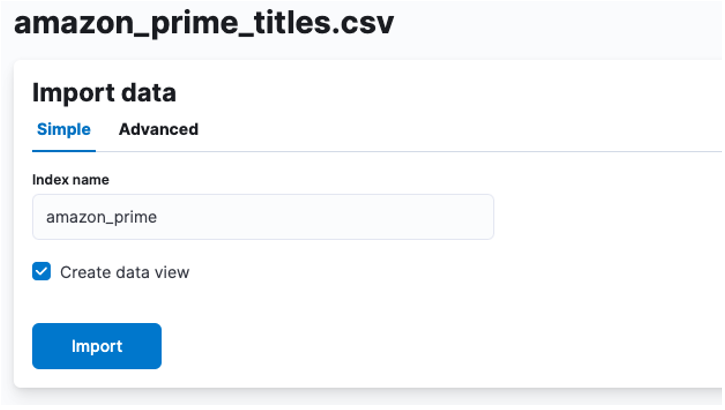
샤드, 복제본, 매핑 등의 수와 같은 인덱스 속성을 사용자 지정하려면 고급 옵션을 선택하고 원하는 대로 설정을 조정합니다.
마지막으로 가져오기를 클릭하고 Kibana가 '마법'을 수행하는 것을 지켜보십시오. 완료되면 Elasticsearch API를 통해 인덱스에 액세스하거나 Kibana 대시보드를 사용할 수 있습니다.
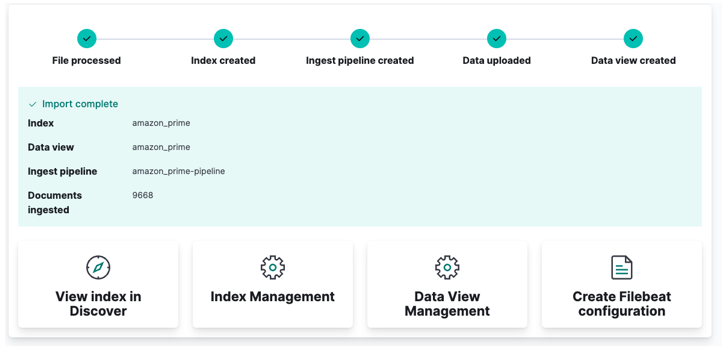
그리고 당신은 끝났습니다!!
결론
이 게시물에서는 Kibana 대시보드를 사용하여 CSV 데이터 세트를 Elasticsearch 클러스터로 가져오고 가져오는 프로세스를 다루었습니다.
읽어주셔서 감사합니다 & 해피코딩!!