HAProxy는 모든 서버의 과부하를 줄이기 위해 노력하며, 트래픽을 분산하여 서버 과부하가 발생하지 않으면서도 다른 서버를 사용할 수 있도록 함으로써 이를 달성합니다. Instagram과 같은 플랫폼은 초당 전송되는 요청으로 인해 막대한 트래픽을 가지므로 과부하를 방지하기 위해 HAProxy를 사용하여 서버의 프런트엔드, 백엔드 및 리스너를 정의해야 합니다.
HAProxy를 사용하는 이유
HAProxy의 설치 및 구성에 대해 알아보기 전에 HAProxy가 제공하는 기능을 통해 HAProxy가 필요한 이유를 이해해야 합니다. HAProxy의 주요 기능은 다음과 같습니다.
- 로드 밸런싱 – HAProxy를 사용하면 단일 서버의 과부하를 방지하기 위해 여러 서버에 트래픽을 편안하게 분산할 수 있습니다. 이렇게 하면 애플리케이션이 다운타임 문제에 직면하지 않고 더 빠른 응답성, 안정성 및 가용성을 얻을 수 있습니다.
- 로깅 및 모니터링 – 문제 해결에 도움이 되도록 서버에 대한 자세한 모니터링 로그를 얻을 수 있습니다. 게다가 HAProxy에는 로드 밸런서에 대한 실시간 성능 분석을 얻을 수 있는 통계 페이지가 있습니다.
- 건강 검진 – 서버에서도 상태를 확인하려면 상태 점검이 필요합니다. HAProxy는 상태 점검을 자주 실행하여 서버 상태를 파악하여 안정성을 향상합니다. 비정상 서버가 감지되면 트래픽을 다른 서버로 다시 라우팅합니다.
- 역방향 프록시 – 보안을 강화하는 한 가지 방법은 내부 구조를 숨기는 것입니다. 다행히 HAProxy를 사용하면 클라이언트로부터 트래픽을 수신하여 적절한 서버로 라우팅할 수 있습니다. 이렇게 하면 내부 구조가 해커의 눈에 숨겨집니다.
- ACL(액세스 제어 목록) – HAProxy를 사용하면 경로, 헤더, IP 주소 등 다양한 기준을 사용하여 트래픽 라우팅이 발생하는 방식을 정의할 수 있습니다. 따라서 트래픽에 대한 사용자 지정 라우팅 논리를 정의하는 것이 더 쉬워집니다.
- SSL 종료 – 기본적으로 SSL/TLS는 백엔드 서버에 의해 오프로드되어 성능이 저하됩니다. 그러나 HAProxy를 사용하면 SSL/TLS 종료가 로드 밸런서에서 발생하여 백엔드 서버에서 작업을 오프로드합니다.
HAProxy 설치
지금까지 HAProxy가 무엇인지 정의하고 애플리케이션에 HAProxy가 필요한 이유를 이해하는 데 도움이 되도록 HAProxy가 제공하는 기능에 대해 논의했습니다. 다음 단계는 시스템에 설치하여 시작하는 방법을 이해하는 것입니다.
Ubuntu 또는 Debian 시스템을 실행하는 경우 APT 패키지 관리자에서 HAProxy를 설치할 수 있습니다. 다음 명령을 실행하십시오.
$ sudo 적절한 업데이트
$ sudo apt 설치 haproxy
마찬가지로 RHEL 기반 시스템이나 CentOS를 사용하는 경우 'yum' 패키지 관리자에서 HAProxy를 사용할 수 있습니다. 다음 명령을 실행하십시오.
$ sudo 냠 업데이트
$ sudo yum 설치 haproxy
우리의 경우 Ubuntu를 사용하고 있습니다. 따라서 우리는 다음과 같은 명령을 받았습니다.
그런 다음 버전을 확인하여 HAProxy를 성공적으로 설치했는지 확인할 수 있습니다.
$ haproxy --버전 
HAProxy를 구성하는 방법
HAProxy가 설치되면 이제 해당 구성 파일( / etc/haproxy/haproxy.cfg) 로드 밸런서에 사용하려는 설정을 정의합니다.
nano 또는 vim과 같은 편집기를 사용하여 구성 파일을 엽니다.
$sudo nano /etc/haproxy/haproxy.cfg다음과 같은 구성 파일을 얻습니다.
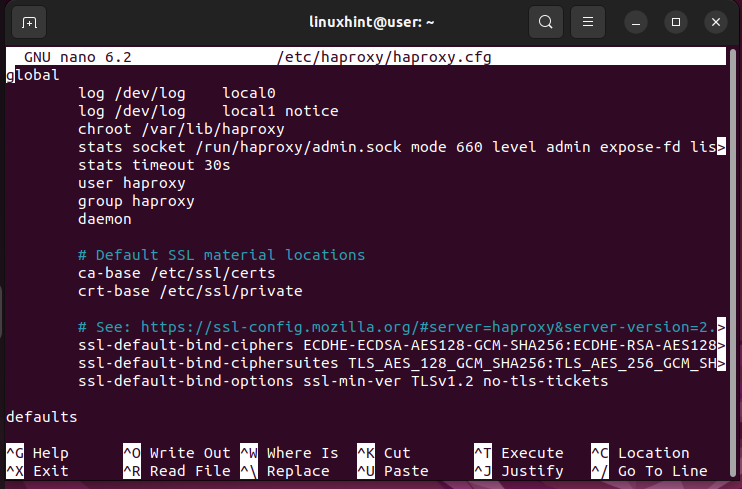
구성 파일에는 다음 두 가지 주요 섹션이 있음을 알 수 있습니다.
- 글로벌 – 이는 파일의 첫 번째 섹션이므로 해당 값을 변경하면 안 됩니다. 여기에는 HAProxy 작동 방식을 정의하는 프로세스 설정이 포함되어 있습니다. 예를 들어 HAProxy 기능을 실행할 수 있는 로깅 세부 정보와 그룹 또는 사용자를 정의합니다. 이 구성 파일에는 전역 섹션이 하나만 있을 수 있으며 해당 값은 변경되지 않은 상태로 유지되어야 합니다.
- 기본값 - 이 섹션에는 노드의 기본값이 포함되어 있습니다. 예를 들어 이 섹션에서 HAProxy에 대한 시간 초과 또는 작동 모드를 추가할 수 있습니다. 게다가 HAProxy 구성 파일에 수많은 기본 섹션이 있을 수도 있습니다.
다음은 '기본값' 섹션의 예입니다.
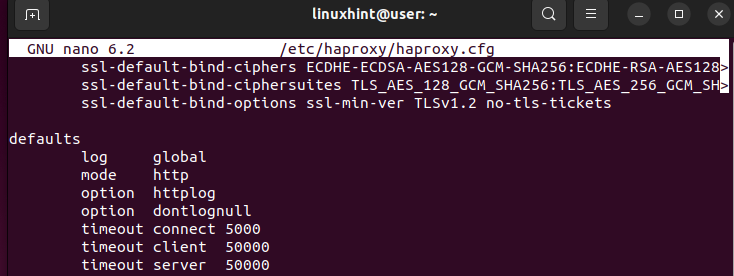
주어진 이미지에서 모드는 HAProxy가 들어오는 요청을 처리하는 방법을 정의합니다. 모드를 HTTP 또는 TCP로 설정할 수 있습니다. 시간 초과는 HAProxy가 기다려야 하는 시간을 지정합니다. 예를 들어 연결 시간 초과는 백엔드 연결이 이루어지기 전에 기다리는 시간입니다. 시간 초과 클라이언트는 클라이언트가 데이터를 보낼 때까지 HAProxy가 기다려야 하는 시간입니다. 타임아웃 서버는 해당 서버가 클라이언트에 전달할 데이터를 보낼 때까지 기다리는 시간입니다. 기본값을 정의하는 방법은 애플리케이션의 응답 시간을 향상시키는 데 매우 중요합니다.
로드 밸런서가 예상대로 작동하려면 정의해야 하는 섹션이 세 개 더 있습니다.
- 프론트엔드 – 이 섹션에는 클라이언트가 연결을 설정하는 데 사용할 IP 주소가 포함되어 있습니다.
- 백엔드 – 프런트엔드 섹션에 정의된 대로 요청을 처리하는 서버 풀을 보여줍니다.
- 듣다 - 특정 서버 그룹을 라우팅하고자 할 때 순차적으로 사용됩니다. 이 섹션에서는 프런트엔드와 백엔드의 작업을 결합합니다.
예를 들어보자
이 예에서는 특정 포트와 함께 로컬 호스트를 사용하도록 프런트엔드를 정의합니다. 다음으로, 이를 localhost를 실행하는 백엔드와 바인딩한 다음 Python 서버를 실행하여 로드 밸런싱에 대해 모든 것이 예상대로 작동하는지 테스트합니다. 주어진 단계를 따르십시오.
1단계: 기본값 섹션 구성
'기본값' 섹션에서는 노드 전체에서 공유할 값을 설정합니다. 우리의 경우 모드를 HTTP로 설정하고 클라이언트와 서버에 대한 시간 초과를 설정합니다. 귀하의 필요에 맞게 시간을 조정할 수 있습니다.

이러한 모든 편집 내용은 '/etc/haproxy/haproxy.cfg'에 있는 HAProxy 구성에 있습니다. 기본 섹션이 구성되면 프런트엔드를 정의해 보겠습니다.
2단계: 프런트엔드 섹션 구성
프런트엔드 섹션에서는 클라이언트가 온라인으로 애플리케이션이나 웹사이트에 액세스하는 방법을 정의합니다. 우리는 애플리케이션의 IP 주소를 제공합니다. 하지만 이 경우에는 localhost를 사용하여 작업합니다. 따라서 우리의 IP 주소는 대체 주소 127.0.0.1이고 포트 80을 통한 연결을 허용하려고 합니다.

지정된 포트에서 IP 주소에 대한 수신기 역할을 하는 'bind' 키워드를 추가해야 합니다. 정의한 IP 주소와 포트는 로드 밸런서가 수신 요청을 수락하는 데 사용하는 것입니다.
구성 파일에 이전 줄을 추가한 후 다음 명령을 사용하여 'haproxy.service'를 다시 시작해야 합니다.
$ sudo systemctl 재시작 haproxy 
이 시점에서 'curl' 명령을 사용하여 웹사이트에 요청을 보낼 수 있습니다. 명령을 실행하고 대상 IP 주소를 추가합니다.
$ 컬HAProxy의 백엔드가 어떻게 될지 아직 정의하지 않았으므로 다음과 같이 503 오류가 발생합니다. 로드 밸런서가 요청을 수신했지만 현재 이를 처리할 수 있는 서버가 없으므로 오류가 발생합니다.

3단계: 백엔드 구성
백엔드 섹션은 들어오는 요청을 처리할 서버를 정의하는 곳입니다. 로드 밸런서는 이 섹션을 참조하여 서버가 오버로드되지 않도록 수신 요청을 배포하는 방법을 확인합니다.
이전에 발생한 503 오류는 요청을 처리할 백엔드가 없었기 때문에 발생했습니다. 요청을 처리하기 위해 'default_backend'를 정의하는 것부터 시작하겠습니다. 프론트엔드 섹션에서 정의합니다. 이 경우에는 이름을 'linux_backend'로 지정했습니다.
다음으로, 프론트엔드 섹션에 정의된 것과 동일한 이름을 가진 백엔드 섹션을 생성하십시오. 그런 다음 'server' 키워드와 서버 이름 및 해당 IP 주소를 사용해야 합니다. 다음 이미지는 IP 127.0.0.1 및 포트 8001을 사용하여 'linuxhint1' 서버를 정의했음을 보여줍니다.
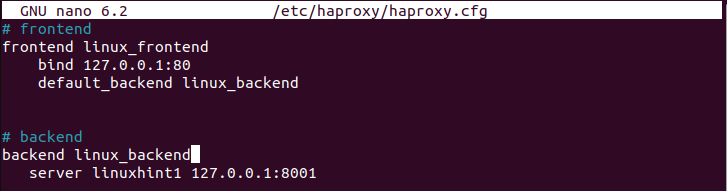
백엔드 서버 풀을 가질 수 있지만 이 경우에는 하나만 정의했습니다. 파일을 저장했는지 확인하십시오. HAProxy 서비스를 다시 시작해야 합니다.

생성된 HAProxy 로드 밸런서를 테스트하기 위해 Python3을 사용하여 웹 서버를 생성하고 지정한 IP 주소를 사용하여 백엔드 포트를 바인딩합니다. 다음과 같이 명령을 실행합니다.
$ python3 -m http.server 8001 --bind 127.0.0.1IP 주소 및 바인딩하려는 포트와 일치하도록 값을 바꿔야 합니다. 웹 서버가 어떻게 생성되고 들어오는 요청을 수신하는지 확인하세요.

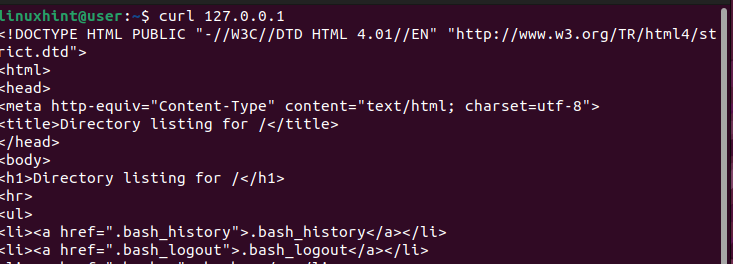
다른 터미널에서는 'curl' 명령을 사용하여 서버에 요청을 보내겠습니다.
$ 컬이전에 요청을 처리할 수 있는 서버가 없음을 나타내는 503 오류가 발생한 것과 달리 이번에는 HAProxy 로드 밸런서가 작동하고 있음을 확인하는 출력을 얻습니다.
웹 서버를 생성했던 이전 터미널로 돌아가면 HAProxy가 요청을 수신하고 이를 백엔드 섹션에 정의된 서버로 전송하여 처리했음을 확인하는 성공 출력 200을 얻는 것을 볼 수 있습니다.
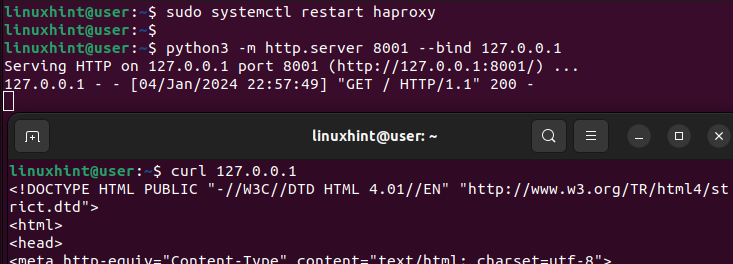
이것이 웹사이트나 애플리케이션에 간단한 HAProxy를 설정하는 방법입니다.
규칙 작업
이 초보자용 HAProxy 튜토리얼을 마무리하기 전에 로드 밸런서에서 요청을 처리하는 방법을 안내하는 규칙을 정의하는 방법에 대해 빠르게 이야기해 보겠습니다.
이전과 동일한 단계에 따라 기본 섹션을 그대로 두고 프런트엔드 섹션에서 다른 IP 주소를 정의하겠습니다. 동일한 IP 주소를 바인딩하지만 다른 포트의 연결을 허용합니다.
또한 요청이 들어오는 포트에 따라 사용할 다른 서버 풀인 'default_backend'와 또 다른 'use_backend'가 있습니다. 다음 구성에서는 포트 81을 통한 모든 요청이 'Linux2_backend'의 서버에 의해 처리됩니다. 다른 요청은 'default_backend'에 의해 처리됩니다.
그런 다음 프런트엔드에 정의된 대로 백엔드 섹션을 생성합니다. 각 백엔드마다 요청 처리에 사용하도록 지정하는 서로 다른 서버가 있습니다.
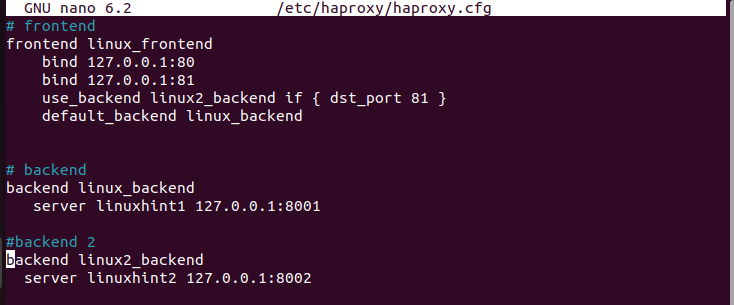
HAProxy 서비스를 빠르게 다시 시작하세요.

Python3을 사용하여 웹 서버를 만들고 대체 백엔드 서버인 포트 8002에서 요청을 바인딩해 보겠습니다.

요청을 보낼 때 로드 밸런서를 트리거하여 기본 서버가 아닌 대체 서버로 요청을 보내도록 포트를 81로 지정합니다.
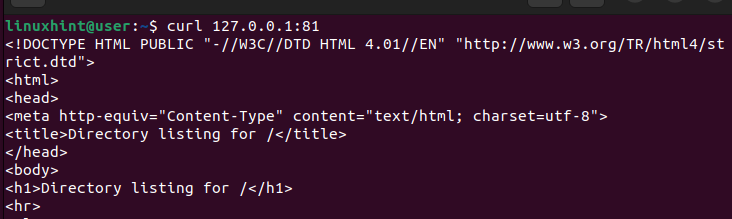
웹 서버를 다시 확인하면 요청 수신 및 처리를 관리하고 200(성공) 응답을 제공하는 것을 볼 수 있습니다.
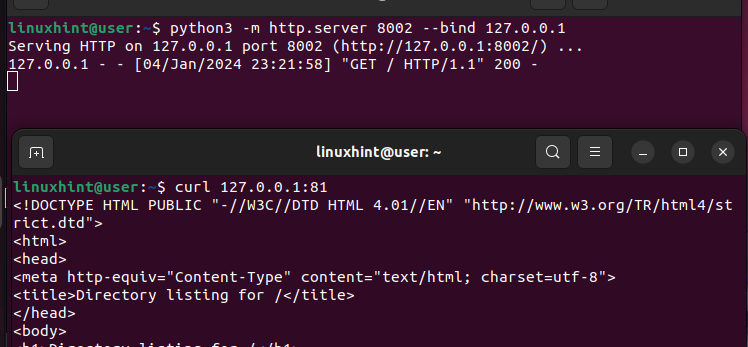
이것이 로드 밸런서가 요청을 수신하고 처리하는 방법을 안내하는 규칙을 정의하는 방법입니다.
결론
HAProxy는 TCP/HTTP 애플리케이션의 로드 밸런싱을 위한 이상적인 솔루션입니다. 설치한 후에는 구성 파일을 편안하게 편집하여 로드 밸런서의 작동 방식을 안내하는 기본값, 프런트엔드 및 백엔드 섹션을 정의할 수 있습니다. 이 게시물은 HAProxy에 대한 초보자 가이드입니다. HAProxy와 그 기능을 정의하는 것부터 시작되었습니다. 다음으로 HAProxy를 구성하는 방법을 자세히 알아보고 HAProxy를 로드 밸런서로 사용하는 방법에 대한 예를 제공하여 결론을 내렸습니다.