Elasticsearch는 부피가 크고 구조화되지 않은 반구조적 데이터를 저장하는 강력하고 인기 있는 솔루션입니다. 이것은 순전히 NoSQL 데이터베이스이며 데이터를 저장, 관리 및 검색하는 데 완전히 다른 접근 방식을 사용합니다. JSON 형식의 문서에 데이터를 저장하고 나머지 API를 사용하여 저장된 데이터에 대해 다른 작업을 수행합니다.
이 블로그에서는 다음을 시연합니다.
Elasticsearch는 어떻게 데이터를 저장하고 검색합니까?
데이터를 저장하는 데 사용되는 Elasticsearch 주요 구성 요소 또는 계층 구조는 다음과 같습니다.
- 문서: 문서는 데이터를 JSON 형식으로 저장하는 Elasticsearch의 주요 부분입니다. 좋다
- 지수: 인덱스는 인덱스라고 합니다. 문서 모음입니다. SQL과 마찬가지로 데이터베이스라고 합니다.
- 반전 인덱스: 매우 빠른 전체 텍스트 검색을 지원합니다. 단어를 색인으로 저장하고 문서 이름을 참조로 저장합니다.
Elasticsearch 문서란 무엇입니까?
Elasticsearch 문서는 JSON 형식의 데이터 저장 단위입니다. 관계형 데이터베이스와 마찬가지로 문서는 일부 인덱스에 저장된 데이터베이스의 테이블 또는 행이라고 할 수 있습니다. 인덱스는 여러 문서를 가질 수 있으며 여러 테이블이 있는 데이터베이스라고 합니다. 일반적으로 복잡한 데이터 구조를 저장하고 데이터를 JSON 형식으로 살균합니다.
또한 각 문서에는 ' 핵심 가치 ” 테이블이 관계형 데이터베이스의 여러 열 또는 필드를 갖는 것처럼 데이터를 저장하기 위한 쌍입니다. 그런 다음 이러한 키-값 쌍은 문서 매핑을 결정하는 방식으로 인덱싱되어야 합니다. 그런 다음 매핑은 텍스트, 플로트, 지리적 위치, 시간 등과 같은 필드 데이터에 따라 문서의 데이터 유형을 정의합니다.
Elasticsearch는 인덱스 필드 구조를 미리 정의하도록 우리를 구속하지 않으며 문서는 인덱스에서 다른 필드 구조를 가질 수 있습니다. 그러나 필드의 매핑이 특정 데이터 유형에 대해 정의된 경우 인덱스의 모든 Elasticsearch 문서는 동일한 매핑 유형을 따라야 합니다. Elasticsearch에 데이터를 저장하는 문서 작업을 확인하려면 다음 섹션으로 이동하십시오.
Elasticsearch 문서에 데이터를 저장하는 방법은 무엇입니까?
Elasticsearch에 데이터를 저장하려면 사용자가 먼저 인덱스를 생성해야 합니다. 그런 다음 Elasticsearch 문서에 데이터를 저장할 필드를 지정합니다. 데모의 경우 나열된 단계를 수행하십시오.
1단계: Elasticsearch 시작
시스템에서 Elasticsearch 데이터베이스 또는 엔진을 실행하려면 명령 프롬프트와 같은 시스템 터미널을 시작합니다. 그 후 ' 큰 상자 ” 폴더를 통해 Elasticsearch의 CD ' 명령:
CD C:\Users\Dell\Documents\Elk 스택\elasticsearch-8.7.0\bin
그런 다음 Elasticsearch의 배치 파일을 실행하여 시스템에서 데이터베이스를 실행합니다.
elasticsearch.bat
2단계: Kibana 시작
다음으로 시스템에서 Kibana를 실행합니다. 그렇게 하려면 ' 큰 상자 명령 프롬프트에서 ” 폴더:
CD C:\Users\Dell\Documents\Elk 스택\kibana-8.7.0\bin
다음으로 아래 명령을 실행하여 Kibana 실행을 시작합니다.
kibana.bat
메모: 시스템에 Elasticsearch 및 Kibana를 설치 및 설정하지 않은 경우 게시물로 이동하여 시스템에 설치하는 단계별 절차를 확인하십시오.
Elasticsearch의 경우 ' Windows에서 .zip으로 Elasticsearch 설치 및 설정 ' 기사. Windows에서 Kibana를 설정하려면 “ Elasticsearch용 Kibana 설정 ' 기사.
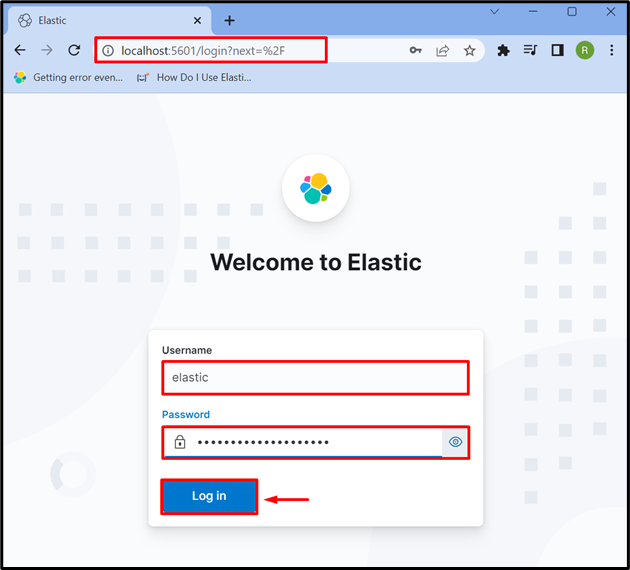
3단계: Kibana에 로그인
시스템에서 Kibana를 시작한 후 기본 주소인 Kibana '로 이동합니다. 로컬 호스트:5601 ”와 같은 Elasticsearch의 로그인 자격 증명을 제공하십시오. 탄력있는 ” 사용자 및 암호. 그런 다음 '를 누르십시오. 로그인 ” 버튼:
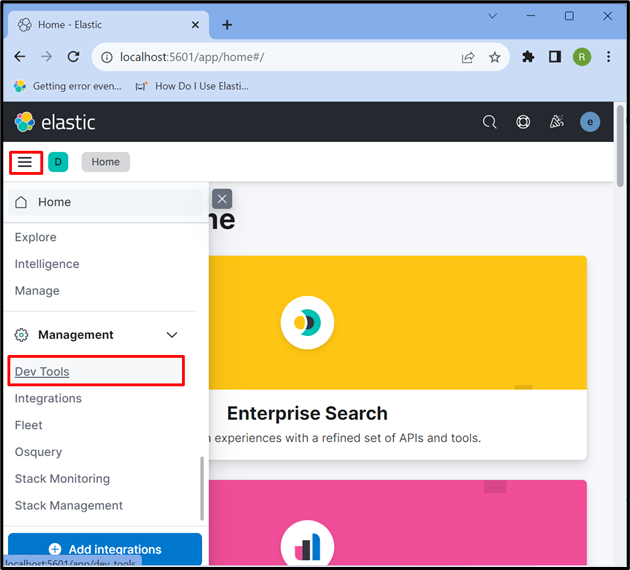
4단계: Kibana '개발 도구' 열기
그런 다음 '를 클릭하십시오. 가로 막대 3개 ” 아이콘을 클릭하고 Kibana “를 엽니다. 개발 도구 ” API를 사용하여 데이터를 저장, 검색 및 업데이트:
5단계: 인덱스 생성
이제 '를 사용하여 새 인덱스를 만듭니다. PUT /<인덱스 이름> ” API 요청:
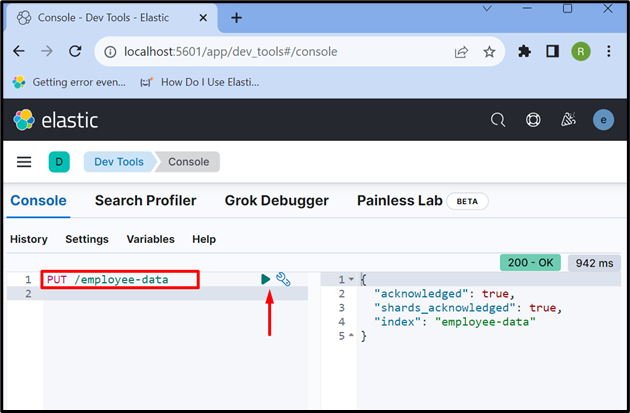
놓다 / 직원 데이터
출력은 ' 직원 데이터 ” 인덱스가 성공적으로 생성되었습니다:
6단계: 문서에 데이터 삽입
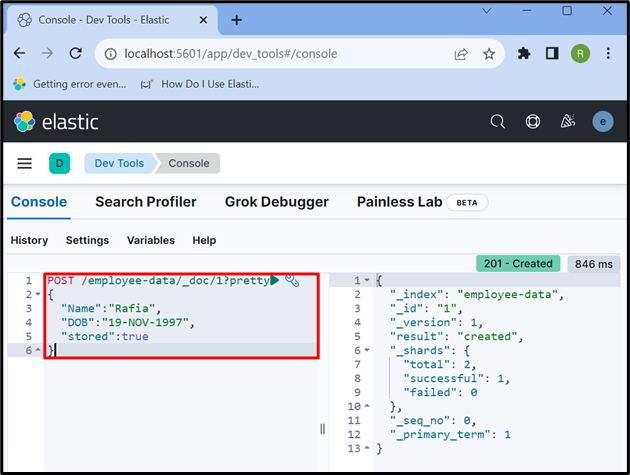
이제 ' 우편 ” 인덱스에 데이터를 저장하는 API. 아래 요청에서 ' 직원 데이터 '는 Elasticsearch의 인덱스, ' _문서 ”는 Elasticsearch 문서에 데이터를 저장하는 데 사용되며 “ 1 ”는 아이디입니다:
우편 / 직원 데이터 / _문서 / 1 ?예쁜{
'이름' : '라피아' ,
'생년월일' : '1997년 11월 19일' ,
'저장' :진실
}
7단계: Elasticsearch 문서에서 데이터 검색
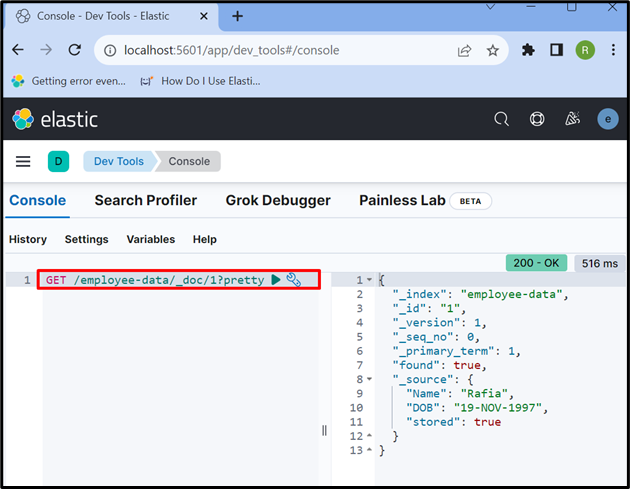
인덱스 또는 Elasticsearch 문서에서 데이터에 액세스하려면 ' 얻다 ” 아래에 사용된 API:
얻다 / 직원 데이터 / _문서 / 1 ?예쁜
출력은 id가 '인 Elasticsearch 문서에서 성공적으로 데이터를 추출했음을 보여줍니다. 1 ”:
이것이 Elasticsearch 문서에 관한 전부입니다.
결론
Elasticsearch 문서는 일반적으로 JSON 형식으로 데이터를 저장하는 데 사용됩니다. 관계형 데이터베이스와 마찬가지로 문서는 일부 인덱스에 저장된 행으로 참조될 수 있습니다. 이러한 인덱스는 데이터베이스에 다른 테이블이 있는 것처럼 여러 문서를 가질 수 있습니다. 이러한 문서에는 ' 핵심 가치 ” 쌍으로 데이터를 저장합니다. 이 기사에서는 Elasticsearch Documents가 무엇이고 Elasticsearch에서 어떻게 작동하는지 설명했습니다.