이 기사에서는 Elasticsearch multi-get API를 사용하여 ID를 기반으로 여러 JSON 문서를 가져오는 방법에 대해 설명합니다. 또한 Elasticsearch를 사용하면 단일 가져오기 쿼리를 사용하여 문서 ID만 사용하는 인덱스에서 문서를 검색할 수 있습니다.
탐색해 봅시다.
요청 구문
다음은 Elasticsearch multi-get API의 구문입니다.
가져오기 /_mget
GET /<인덱스>/_mget
multi-get API는 여러 색인을 지원하므로 문서가 동일한 색인에 없더라도 문서를 가져올 수 있습니다.
요청은 다음 경로 매개변수를 지원합니다.
- <색인> – 해당 ID로 지정된 문서를 검색할 인덱스의 이름입니다.
다음과 같이 다른 쿼리 매개변수를 지정할 수도 있습니다.
- 선호 – 선호하는 노드 또는 샤드를 정의합니다.
- 실시간 – true로 설정하면 실시간으로 동작한다.
- 새로 고치다 – 지정된 문서를 가져오기 전에 대상 분할을 새로 고치도록 작업을 강제합니다.
- 라우팅 – 작업을 특정 샤드로 라우팅하는 데 사용되는 값입니다.
- Store_fields – 문서가 아닌 인덱스에 저장된 문서 필드를 검색합니다.
- _원천 – 요청이 _source 필드를 반환해야 하는지 여부를 정의하는 부울 값.
쿼리에는 다음 값이 포함된 본문이 필요합니다.
- 문서 – 페치하려는 문서를 지정합니다. 또한 이 섹션은 다음 속성을 지원합니다.
- _ID – 대상 문서의 고유 ID입니다.
- _인덱스 – 대상 문서를 포함하는 인덱스.
- 라우팅 – 문서의 기본 분할에 대한 키입니다.
- _원천 – true인 경우 모든 소스 필드가 포함됩니다. 그렇지 않으면 제외됩니다.
- _stored_fields – 포함하려는 stored_fields.
- 아이디 – 가져오려는 문서의 ID입니다.
예 1: 동일한 인덱스에서 여러 문서 가져오기
다음 예제에서는 Elasticsearch multi-get API를 사용하여 Netflix 인덱스에서 특정 ID가 있는 문서를 검색하는 방법을 보여줍니다.
curl -XGET 'http://localhost:9200/netflix/_mget' -H 'kbn-xsrf: 보고' -H '콘텐츠 유형: 애플리케이션/json' -d'{
'문서': [
{
'_id': 'T3wnVoMBck2AEzXPytlJ'
},
{
'_id': 'W3wnVoMBck2AEzXPytlJ'
}
]
}'
지정된 요청은 Netflix 인덱스에서 지정된 ID를 가진 문서를 가져와야 합니다. 결과 출력은 다음과 같습니다.
{'문서': [
{
'_index': '넷플릭스',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_버전': 1,
'_seq_no': 0,
'_primary_term': 1,
'찾음': 사실,
'_원천': {
'시간': '90분',
'listed_in': '다큐멘터리',
'국가': '미국',
'date_added': '2021년 9월 25일',
'show_id': 's1',
'감독': '커스틴 존슨',
'release_year': 2020년,
'등급': 'PG-13',
'description': '그녀의 아버지가 임종을 앞두고 있을 때, 영화감독인 Kirsten Johnson은 둘 다 피할 수 없는 상황에 직면할 수 있도록 독창적이고 코믹한 방법으로 그의 죽음을 연출합니다.',
'유형': '영화',
'title': '딕 존슨은 죽었다'
}
},
{
'_index': '넷플릭스',
'_id': 'W3wnVoMBck2AEzXPytlJ',
'_버전': 1,
'_seq_no': 12,
'_primary_term': 1,
'찾음': 사실,
'_원천': {
'국가': '독일, 체코',
'show_id': 's13',
'감독': 'Christian Schwochow',
'release_year': 2021년,
'등급': 'TV-MA',
'description': '테러 폭탄 테러로 가족 대부분이 살해된 후, 한 젊은 여성이 자신도 모르는 사이에 그들을 죽인 바로 그 그룹에 가담하게 됩니다.',
'유형': '영화',
'제목': '나는 칼이다',
'지속시간': '127분',
'listed_in': '드라마, 국제 영화',
'출연': 'Luna Wedler, Jannis Niewöhner, Milan Peschel, Edin Hasanović, Anna Fialová, Marlon Boess, Victor Boccard, Fleur Geffrier, Aziz Dyab, Mélanie Fouché, Elizaveta Maximová',
'date_added': '2021년 9월 23일'
}
}
]
}
다음과 같이 문서 ID를 간단한 배열에 넣어 요청을 단순화할 수도 있습니다.
curl -XGET 'http://localhost:9200/netflix/_mget' -H 'kbn-xsrf: 보고' -H '콘텐츠 유형: 애플리케이션/json' -d'{
'ids': ['T3wnVoMBck2AEzXPytlJ', 'W3wnVoMBck2AEzXPytlJ']
}'
이전 요청은 유사한 작업을 수행해야 합니다.
예 2: 여러 인덱스에서 문서 가져오기
다음 예에서 요청은 다음과 같이 서로 다른 인덱스에서 여러 문서를 가져옵니다.
curl -XGET 'http://localhost:9200/_mget' -H 'kbn-xsrf: 보고' -H '콘텐츠 유형: 응용 프로그램/json' -d'{
'문서': [
{
'_index': '넷플릭스',
'_id': 'T3wnVoMBck2AEzXPytlJ'
},
{
'_index': '디즈니',
'_id': '8j4wWoMB1yF5VqfaKCE4'
}
]
}'
결과 출력은 다음과 같습니다.

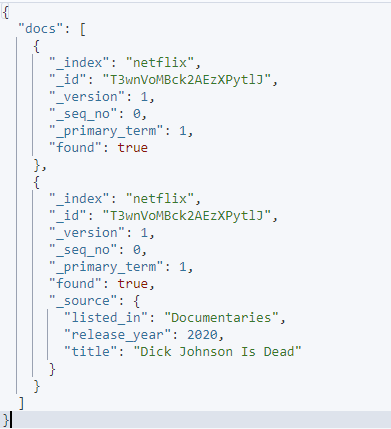
예 3: 특정 필드 제외
source_include 및 source_exclude 매개변수를 사용하여 주어진 요청에서 특정 필드를 제외할 수 있습니다.
예는 다음과 같습니다.
curl -XGET 'http://localhost:9200/_mget' -H 'kbn-xsrf: 보고' -H '콘텐츠 유형: 응용 프로그램/json' -d'{
'문서': [
{
'_index': '넷플릭스',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_source': 거짓
},
{
'_index': '넷플릭스',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_원천': {
'포함': [ 'listed_in', 'release_year', 'title' ],
'제외': [ '설명', '유형', '날짜_추가됨' ]
}
}
]
}'
주어진 요청은 소스 포함 및 제외를 사용하여 주어진 문서에서 검색하려는 필드를 지정합니다.
결과 출력은 다음과 같습니다.
결론
이 게시물에서는 ID를 기반으로 다양한 소스에서 여러 문서를 가져올 수 있는 Elasticsearch multi-get API 작업의 기본 사항에 대해 논의했습니다. 자세한 내용은 다른 문서를 자유롭게 탐색하십시오.
즐거운 코딩!