이 자습서에서는 도커를 사용하여 Apache Kafka 클러스터를 배포하는 방법을 배웁니다. 이를 통해 제공된 도커 이미지를 사용하여 거의 모든 환경에서 Kafka 클러스터를 빠르게 가동할 수 있습니다.
기본부터 시작하여 Kafka가 무엇인지 논의해 보겠습니다.
아파치 카프카란?
Apache Kafka는 확장성이 뛰어난 무료 오픈 소스 분산형 내결함성 게시-구독 메시징 시스템입니다. 대용량, 높은 처리량 및 실시간 데이터 스트림을 처리하도록 설계되어 로그 집계, 실시간 분석 및 이벤트 기반 아키텍처를 비롯한 많은 사용 사례에 적합합니다.
Kafka는 여러 서버에서 대량의 데이터를 처리할 수 있는 분산 아키텍처를 기반으로 합니다. 생산자가 주제에 메시지를 보내고 소비자가 이를 수신하기 위해 구독하는 게시-구독 모델을 사용합니다. 이를 통해 생산자와 소비자 간의 분리된 통신이 가능하여 높은 확장성과 유연성을 제공합니다.
Docker Compose란 무엇입니까?
Docker Compose는 다중 컨테이너 애플리케이션을 정의하고 실행하기 위한 도커 플러그인 또는 도구를 나타냅니다. Docker는 YAML 파일에서 컨테이너 구성을 정의하도록 우리를 구성합니다. 구성 파일에는 애플리케이션에 필요한 서비스, 네트워크 및 볼륨과 같은 컨테이너 사양이 포함됩니다.
docker-compose 명령을 사용하면 단일 명령으로 여러 컨테이너를 만들고 시작할 수 있습니다.
Docker 및 Docker Compose 설치
첫 번째 단계는 로컬 컴퓨터에 도커를 설치했는지 확인하는 것입니다. 자세한 내용은 다음 리소스를 확인하세요.
- https://linuxhint.com/install_configure_docker_ubuntu/
- https://linuxhint.com/install-docker-debian/
- https://linuxhint.com/install_docker_debian_10/
- https://linuxhint.com/install-docker-ubuntu-22-04/
- https://linuxhint.com/install-docker-on-pop_os/
- 0CE485D339926C718DC100EF344BB17AF0132나쁨
- https://linuxhint.com/install-use-docker-centos-8/
- https://linuxhint.com/install_docker_on_raspbian_os/
이 자습서를 작성하는 시점에서 docker Compose를 설치하려면 대상 머신에 Docker 데스크톱을 설치해야 합니다. 따라서 docker compose를 독립 실행형 장치로 설치하는 것은 더 이상 사용되지 않습니다.
Docker를 설치하면 YAML 파일을 구성할 수 있습니다. 이 파일에는 도커 컨테이너를 사용하여 Kafka 클러스터를 가동하는 데 필요한 모든 세부 정보가 포함되어 있습니다.
Docker-Compose.YAML 설정
docker-compose.yaml을 만들고 원하는 텍스트 편집기로 편집합니다.
$ 터치 docker-compose.yaml$ vim docker-compose.yaml
다음으로 다음과 같이 docker 구성 파일을 추가합니다.
버전 : '삼'서비스 :
사육사 :
영상 : 비트나미 / 사육사 : 3.8
포트 :
- '2181:2181'
볼륨 :
- 'zookeeper_data:/bitnami'
환경 :
- ALLOW_ANONYMOUS_LOGIN 허용 = 예
카프카 :
영상 : 도커. 이것 / 비트나미 / 카프카 : 3.3
포트 :
- '9092:9092'
볼륨 :
- 'kafka_data:/비트나미'
환경 :
- KAFKA_CFG_ZOOKEEPER_CONNECT = 사육사 : 2181
- ALLOW_PLAINTEXT_LISTENER = 예
의존하다 :
- 사육사
볼륨 :
사육사_데이터 :
운전사 : 현지의
kafka_data :
운전사 : 현지의
예제 docker 파일은 조정을 위해 Kafka 클러스터가 Zookeeper 서비스에 연결된 Kafka 클러스터와 Zookeeper를 설정합니다. 이 파일은 또한 서비스에 대한 통신 및 액세스를 허용하도록 각 서비스에 대한 포트 및 환경 변수를 구성합니다.
또한 컨테이너가 다시 시작되거나 다시 생성되더라도 서비스 데이터를 유지하도록 명명된 볼륨을 설정합니다.
이전 파일을 간단한 섹션으로 분류해 보겠습니다.
bitnami/zookeeper:3.8 이미지를 사용하여 Zookeeper 서비스부터 시작합니다. 그런 다음 이 이미지는 호스트 머신의 포트 2181을 컨테이너의 포트 2181에 매핑합니다. 또한 ALLOW_ANONYMOUS_LOGIN 환경 변수를 'yes'로 설정했습니다. 마지막으로 서비스가 데이터를 저장하는 볼륨을 zookeeper_data 볼륨으로 설정합니다.
두 번째 블록은 Kafka 서비스를 설정하기 위한 세부 정보를 정의합니다. 이 경우 호스트 포트 9092를 컨테이너 포트 9092에 매핑하는 docker.io/bitnami/kafka:3.3 이미지를 사용합니다. 마찬가지로 KAFKA_CFG_ZOOKEEPER_CONNECT 환경 변수를 정의하고 해당 값을 매핑된 Zookeeper의 주소로 설정합니다. 포트 2181. 이 섹션에서 정의하는 두 번째 환경 변수는 ALLOW_PLAINTEXT_LISTENER 환경 변수입니다. 이 환경 변수의 값을 'yes'로 설정하면 Kafka 클러스터에 대한 보안되지 않은 트래픽이 허용됩니다.
마지막으로 Kafka 서비스가 데이터를 저장하는 볼륨을 제공합니다.
도커가 Zookeeper 및 Kafka에 대한 볼륨을 구성하도록 하려면 볼륨 섹션에 표시된 대로 볼륨을 정의해야 합니다. 그러면 zookeeper_data 및 kafka_data 볼륨이 설정됩니다. 두 볼륨 모두 데이터가 호스트 시스템에 저장됨을 의미하는 로컬 드라이버를 사용합니다.
당신은 그것을 가지고 있습니다! 간단한 단계로 도커를 사용하여 Kafka 컨테이너를 스핀업할 수 있는 간단한 구성 파일입니다.
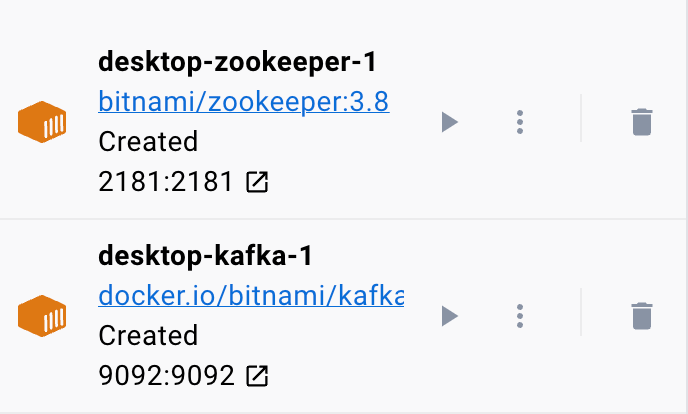
컨테이너 실행
도커가 실행 중인지 확인하기 위해 다음 명령을 사용하여 YAML 파일에서 컨테이너를 실행할 수 있습니다.
$ 스도 도커 작성명령은 YAML 구성 파일을 찾고 지정된 값으로 컨테이너를 실행해야 합니다.
결론
이제 docker compose YAML 구성 파일에서 Apache Kafka를 구성하고 실행하는 방법을 배웠습니다.