정수
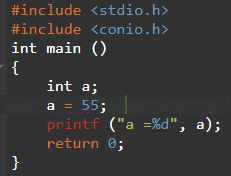
논의할 기본 데이터 유형의 첫 번째 데이터 유형은 정수입니다. 정수 유형은 양수만 의미하는 부호 없는 값 또는 음수 값을 포함하는 부호 있는 값을 가질 수 있습니다. 달리 지정하지 않는 한 정수 값은 항상 서명됩니다. 정수는 int, short int 및 long int와 같은 다른 유형으로 더 분류될 수 있으며, 이는 다시 signed int, unsigned int, signed short int, unsigned short int, signed long int 및 unsigned long int로 분류됩니다. 아래 표시된 예에서 코드 줄은 다음과 같습니다. 정수 ; 변수를 보여줍니다 ㅏ 데이터 유형이 int로 지정되어 숫자를 저장할 수 있습니다(이 경우 55).
숯
이제 다음 데이터 유형은 문자를 나타내는 Char입니다. char는 1바이트로 구성되어 있으므로 한 문자는 char에 보관됩니다. 단일 문자에는 작은따옴표를 사용했지만 아래 예에서는 변수 ㅏ 둘 이상의 문자 또는 일련의 문자를 저장하는 문자 배열입니다. 안녕하세요 세계 . 이를 위해 Strings(문자 배열)에 대한 큰따옴표가 필요합니다.
Char는 int 데이터 유형(0~255)과 마찬가지로 부호가 있거나(범위: -128~+127) 부호가 없는(범위: 0~1) 수 있습니다. 또한 char는 int 값도 허용하므로 char를 int 값으로 생각할 수도 있습니다. char에 정의된 범위 내에서 int를 저장하면 부호 있는 값과 부호 없는 값의 차이가 중요해집니다.
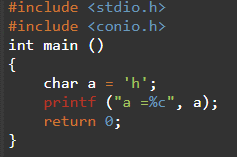
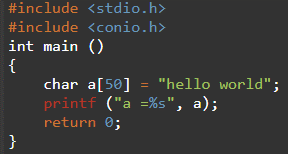
아래 예는 단일 문자가 시간 변수가 할당되었습니다 ㅏ char를 데이터 유형으로 사용합니다. 다음 이미지가 표시되는 반면 ㅏ 할당된 문자 배열로 선언됨 안녕하세요 세계 , 문자 배열.
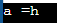
플로트 및 더블
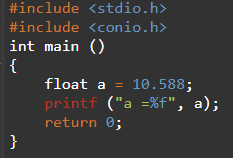
이 부분에서는 float 및 double의 두 가지 데이터 유형을 조사합니다. 10진수와 지수는 float 데이터 유형을 사용하여 C에 저장됩니다. 일반적으로 단정밀도의 10진수 정수(부동 소수점 값이 있는 숫자)를 유지하는 데 사용됩니다. 아래 예에서 변수가 ㅏ float 데이터 유형으로 선언되었으며 10진수 값 10.588이 지정되었습니다.
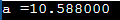
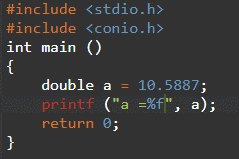
반면 C에서는 배정밀도 십진수(부동 소수점 값을 갖는 숫자)가 Double 데이터 형식을 사용하여 저장됩니다. 이중 데이터 유형은 본질적으로 64비트의 부동 소수점 또는 십진수를 저장할 수 있는 정밀도 데이터 유형입니다. double은 float보다 정밀도가 높기 때문에 부동 소수점 유형보다 두 배의 메모리를 사용한다는 것이 더 명확합니다. 이것은 소수점 이하 자릿수 전후에 16에서 17 사이의 정수를 쉽게 관리할 수 있습니다. 아래 이미지는 변수가 ㅏ 데이터 유형이 double인 경우 값은 10.5887입니다.
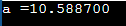
정렬
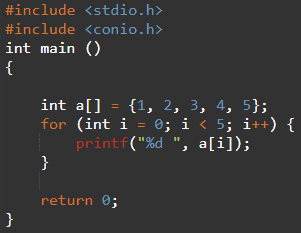
배열은 파생 데이터 유형의 클래스에 속하는 데이터 유형입니다. 따라서 정수, 문자, 부동 소수점, 이중 및 기타 데이터 유형의 배열이 가능합니다. 배열을 초기화하거나 선언에 배열의 크기를 포함해야 합니다. 아래 예에서 배열 변수의 이름은 ㅏ 지정되지 않은 배열의 크기(대괄호 안에 배열의 크기를 선언할 수 있음) 및 데이터 유형은 배열을 의미하는 int ㅏ 1,2,3,4,5가 모두 정수이기 때문에 명확하게 볼 수 있는 int 데이터 유형의 모든 값을 저장합니다.
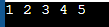
서명된 것과 서명되지 않은 것
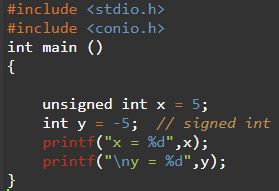
C의 유형 수정자는 서명 및 서명되지 않습니다. 이를 활용하여 데이터 유형이 데이터를 저장하는 방법을 변경할 수 있습니다. 부호를 사용하면 양수 값과 음수 값을 모두 저장할 수 있습니다. 반면 unsigned의 경우 양수만 저장할 수 있습니다. 아래에서 볼 수 있듯이 x라는 이름의 부호 없는 int 데이터 유형은 양의 int(5)를 저장하는 반면 int 변수 y는 음의 정수(-5)를 저장합니다.
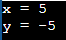
짧고 길다
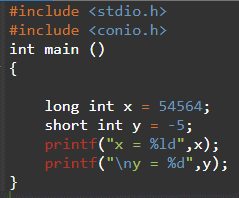
Short 및 Long은 int 데이터 유형의 하위 유형입니다. 작은 정수([32,767, +32,767] 범위)만 사용되는 경우 Short를 사용할 수 있습니다. 반면에 많은 수를 사용하는 경우 int를 long으로 선언할 수 있습니다. 아래 예에서 볼 수 있듯이 long int 엑스 더 큰 숫자 54564가 할당되는 반면 짧은 int y는 -5의 더 작은 값을 얻습니다.
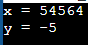
결론
이 기사에서는 모든 기본 데이터 유형, 해당 하위 유형, 파생 데이터 유형까지 살펴보았습니다. C에는 더 많은 데이터 유형이 있습니다. 각 데이터 유형은 목적에 부합하며 C 프로그래밍 언어의 안정성, 안정성 및 내구성에 기여합니다. 기본 데이터 유형과 그 사용법을 더 잘 이해하기 위해 이러한 데이터 유형의 몇 가지 예를 구현했습니다.