이 기사에서 이 두 기능의 차이점을 찾고 작동 방식을 이해할 수 있습니다.
C++의 셔플()
그만큼 혼합() function은 주어진 범위의 요소를 무작위로 섞거나 재정렬하는 데 사용되는 내장 C++ 함수입니다. 함수는 <알고리즘> 헤더 파일에는 두 개의 인수가 있습니다. 범위의 시작 위치는 첫 번째 인수이고 두 번째 인수는 끝 위치를 나타냅니다.
또한 범위의 요소를 섞는 데 사용할 난수를 생성하는 함수 개체인 선택적 세 번째 매개 변수도 사용합니다.
때 혼합() 함수가 호출되면 제공된 난수 생성기를 사용하여 지정된 범위의 요소를 임의로 재정렬합니다. 셔플의 결과는 예측할 수 없으며 요소의 각 가능한 순열이 발생할 가능성이 동일합니다.
예
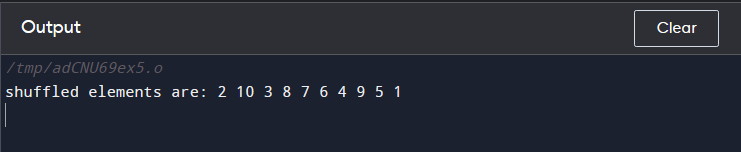
아래의 사용 예를 고려하십시오. shuffle() 함수 C++에서. 이 프로그램에서는 벡터를 만들었습니다. 물건 0에서 10 사이의 정수 값으로. 그런 다음 난수 생성기를 생성하고 벡터의 범위와 함께 다음으로 전달합니다. 혼합() 기능. 그만큼 혼합() 함수는 숫자를 가져와서 이 숫자를 기준으로 요소를 교체합니다. 그런 다음 for 루프를 사용하여 재배열된 벡터 시퀀스를 인쇄했습니다.
#include
#include <벡터>
#include <알고리즘>
#include <무작위>
#include <크로노>
네임스페이스 표준 사용 ;
정수 기본 ( )
{
벡터 < 정수 > 물건 { 1 , 2 , 삼 , 4 , 5 , 6 , 7 , 8 , 9 , 10 } ;
서명되지 않은 씨앗 = 크로노 :: system_clock :: 지금 ( ) . time_since_epoch ( ) . 세다 ( ) ;
혼합 ( 일. 시작하다 ( ) , 일. 끝 ( ) , default_random_engine ( 씨앗 ) ) ;
쿠우트 << '섞인 요소는 다음과 같습니다.' ;
~을 위한 ( 정수 & 나 : 물건 )
쿠우트 << ' ' << 나 ;
쿠우트 << 끝 ;
반품 0 ;
}
C++에서 random_shuffle()
그만큼 random_shuffle() 함수는 또한 임의로 선택한 숫자를 사용하여 주어진 범위의 요소를 임의로 재배열합니다. 난수 생성기를 사용하여 일련의 난수를 생성한 다음 해당 숫자를 사용하여 범위의 요소를 섞기 때문에 프로그램을 실행할 때마다 프로그램의 순서가 달라집니다.
두 개의 매개변수가 필요합니다. random_shuffle() : 범위의 시작 위치는 첫 번째 매개변수이고 두 번째 매개변수는 끝 위치입니다. 추가적으로, random_shuffle() 선택적 세 번째 매개 변수는 요소를 섞기 위한 난수를 생성하는 데 사용할 수 있는 함수 개체입니다.
예
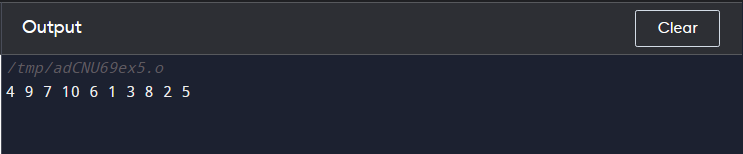
아래 예는 random_shuffle() C++에서. 이 코드에서 우리는 벡터 것 1에서 10까지의 정수 값을 사용한 다음 for 루프 무작위로 섞인 시퀀스를 인쇄하려면 다음을 수행하십시오.
#include#include <알고리즘>
네임스페이스 표준 사용 ;
정수 기본 ( )
{
벡터 < 정수 > 물건 { 1 , 2 , 삼 , 4 , 5 , 6 , 7 , 8 , 9 , 10 } ;
srand ( static_cast < 서명되지 않은 정수 > ( 시간 ( nullptr ) ) ) ;
random_shuffle ( 일. 시작하다 ( ) , 일. 끝 ( ) ) ;
~을 위한 ( 정수 나 : 물건 ) {
쿠우트 << 나 << ' ' ;
}
쿠우트 << ' \N ' ;
반품 0 ;
}
shuffle()과 random_shuffle()의 차이점
다음은 주요 차이점입니다. 혼합() 그리고 random_shuffle() C++의 함수.
1: random_shuffle() 셔플할 요소의 범위를 나타내는 한 쌍의 반복자를 사용하는 반면 혼합() 섞을 요소의 범위를 나타내는 한 쌍의 반복자와 섞기에 사용할 난수 생성기를 사용합니다.
2: random_shuffle() 일반적으로 다음보다 덜 효율적입니다. 혼합() 셔플링에 사용할 일련의 난수를 생성해야 하기 때문입니다.
3: random_shuffle() C++ 표준 라이브러리의 난수 생성기 내부 구현을 사용하여 요소를 섞습니다. 혼합() 셔플링에 사용할 고유한 난수 생성기를 지정할 수 있으므로 셔플링의 임의성을 더 잘 제어할 수 있습니다.
4: random_shuffle()은 C++98에서 도입되었습니다. 모든 버전의 C++ 표준 라이브러리에서 지원하는 반면 혼합() C++11에서 도입되었으며 해당 버전의 표준을 구현하는 컴파일러에서만 지원됩니다.
마지막 생각들
사이의 선택 혼합() 그리고 random_shuffle() 특정 사용 사례 및 요구 사항에 따라 다릅니다. 셔플링의 임의성에 대해 더 많은 제어가 필요하거나 사용자 지정 난수 생성기를 사용하려는 경우 혼합() 더 나은 선택이 될 것입니다. 반면에 그 수준의 제어가 필요하지 않고 요소를 섞는 간단한 방법을 원한다면 random_shuffle() 충분할 수 있습니다.