예시 1:
'iostream'은 C++의 기능이 선언되는 첫 번째 헤더 파일입니다. 그런 다음 여기에 포함된 '벡터' 헤더 파일을 추가하여 벡터 및 벡터 작업을 위한 함수를 사용할 수 있습니다. 그러면 여기에 삽입하는 네임스페이스가 'std'이므로 이 코드에서는 모든 함수와 함께 이 'std'를 개별적으로 넣을 필요가 없습니다. 그런 다음 여기에서 'main()'이 호출됩니다. 그 아래에 'myNewData'라는 이름으로 'int' 데이터 유형의 벡터를 만들고 여기에 정수 값을 삽입합니다.
그런 다음 'for' 루프를 배치하고 그 안에 'auto' 키워드를 활용합니다. 이제 이 반복자는 여기에 있는 값의 데이터 유형을 감지합니다. 'myNewData' 벡터의 값을 가져와 'data' 변수에 저장하고 'cout'에 이 'data'를 추가하면 여기에 표시합니다.
코드 1:
#include
#include <벡터>
사용하여 네임스페이스 성병 ;
정수 기본 ( ) {
벡터 < 정수 > myNewData { 열하나 , 22 , 33 , 44 , 55 , 66 } ;
~을 위한 ( 자동 데이터 : myNewData ) {
시합 << 데이터 << 끝 ;
}
}
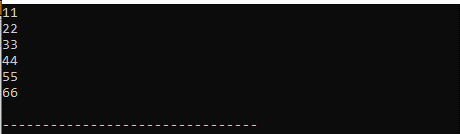
산출 :
우리는 여기에 인쇄된 이 벡터의 모든 값을 보았습니다. 'for' 루프를 활용하고 그 안에 'auto' 키워드를 배치하여 이러한 값을 인쇄합니다.
예 2:
여기서는 모든 함수 선언이 포함된 'bits/stdc++.h'를 추가합니다. 그런 다음 여기에 'std' 네임스페이스를 넣고 'main()'을 호출합니다. 아래에서는 'string'의 'set'을 초기화하고 이름을 'myString'으로 지정합니다. 그런 다음 다음 줄에 문자열 데이터를 삽입합니다. 'insert()' 메소드를 사용하여 이 세트에 일부 과일 이름을 삽입합니다.
이 아래에 'for' 루프를 사용하고 그 안에 'auto' 키워드를 배치합니다. 그런 다음 'auto' 키워드를 사용하여 'my_it'이라는 이름의 반복자를 초기화하고 'begin()' 함수와 함께 'myString'을 여기에 할당합니다.
그런 다음 'my_it'이 'myString.end()'와 같지 않은 조건을 배치하고 'my_it++'를 사용하여 반복자의 값을 증가시킵니다. 그런 다음 '*my_it'을 'cout'에 배치합니다. 이제 알파벳 순서에 따라 과일 이름을 인쇄하고 여기에 'auto' 키워드를 배치하면 데이터 유형이 자동으로 감지됩니다.
코드 2:
#include사용하여 네임스페이스 성병 ;
정수 기본 ( )
{
세트 < 끈 > myString ;
myString. 끼워 넣다 ( { '포도' , '주황색' , '바나나' , '배' , '사과' } ) ;
~을 위한 ( 자동 내_그것 = myString. 시작하다 ( ) ; 내_그것 ! = myString. 끝 ( ) ; 내_그것 ++ )
시합 << * 내_그것 << ' ' ;
반품 0 ;
}
산출:
여기서는 과일 이름이 알파벳 순서로 표시되어 있는 것을 확인할 수 있습니다. 이전 코드에서 'for' 및 'auto'를 사용했기 때문에 문자열 세트에 삽입한 모든 데이터가 여기에 렌더링됩니다.

예시 3:
'bits/stdc++.h'에는 이미 모든 함수 선언이 있으므로 여기에 추가합니다. 'std' 네임스페이스를 추가한 후 이 위치에서 'main()'을 호출합니다. 다음에서 설정한 'int'의 '집합'을 'myIntegers'라고 합니다. 그런 다음, 다음 줄에 정수 데이터를 추가합니다. 이 목록에 몇 가지 정수를 추가하려면 'insert()' 메서드를 사용합니다. 이제 'auto' 키워드가 이 아래에 활용되는 'for' 루프에 삽입됩니다.
다음으로, 'auto' 키워드를 사용하여 'new_it'라는 이름으로 반복자를 초기화하고 'myIntegers' 및 'begin()' 함수를 할당합니다. 다음으로, 'my_it'이 'myIntegers.end()'와 같지 않아야 한다는 조건을 설정하고 'new_it++'를 사용하여 반복자의 값을 늘립니다. 다음으로, 이 “cout” 섹션에 “*new_it”를 삽입합니다. 정수를 오름차순으로 인쇄합니다. “auto” 키워드를 삽입하면 자동으로 데이터 유형을 감지합니다.
코드 3:
#include사용하여 네임스페이스 성병 ;
정수 기본 ( )
{
세트 < 정수 > myIntegers ;
myIntegers. 끼워 넣다 ( { 넷 다섯 , 31 , 87 , 14 , 97 , 이십 일 , 55 } ) ;
~을 위한 ( 자동 new_it = myIntegers. 시작하다 ( ) ; new_it ! = myIntegers. 끝 ( ) ; new_it ++ )
시합 << * new_it << ' ' ;
반품 0 ;
}
산출 :
여기에 정수는 다음과 같이 오름차순으로 표시됩니다. 이전 코드에서 'for' 및 'auto'라는 용어를 사용했기 때문에 정수 세트에 배치한 모든 데이터가 여기에 렌더링됩니다.

예시 4:
여기에서 벡터 작업을 수행할 때 'iostream' 및 '벡터' 헤더 파일이 포함됩니다. 그런 다음 “std” 네임스페이스가 추가되고 “main()”을 호출합니다. 그런 다음 'myVectorV1'이라는 이름으로 'int' 데이터 유형의 벡터를 초기화하고 이 벡터에 일부 값을 추가합니다. 이제 'for' 루프를 배치하고 여기에 'auto'를 활용하여 데이터 유형을 감지합니다. 벡터 값으로 액세스한 다음 'cout'에 'valueOfVector'를 배치하여 인쇄합니다.
그런 다음 그 안에 또 다른 'for'와 'auto'를 배치하고 '&& valueOfVector : myVectorV1'로 초기화합니다. 여기서는 참조로 액세스한 다음 'cout'에 'valueOfVector'를 넣어 모든 값을 인쇄합니다. 이제 루프 내부에서 'auto' 키워드를 활용하므로 두 루프 모두에 데이터 유형을 삽입할 필요가 없습니다.
코드 4:
#include#include <벡터>
사용하여 네임스페이스 성병 ;
정수 기본 ( ) {
벡터 < 정수 > myVectorV1 = { 0 , 1 , 2 , 삼 , 4 , 5 , 6 , 7 , 8 , 9 , 10 } ;
~을 위한 ( 자동 벡터의 값 : myVectorV1 )
시합 << 벡터의 값 << ' ' ;
시합 << 끝 ;
~을 위한 ( 자동 && 벡터의 값 : myVectorV1 )
시합 << 벡터의 값 << ' ' ;
시합 << 끝 ;
반품 0 ;
}
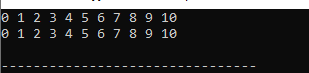
산출:
벡터의 모든 데이터가 표시됩니다. 첫 번째 줄에 표시된 숫자는 값으로 접근한 숫자이고, 두 번째 줄에 표시된 숫자는 코드에서 참조로 접근한 숫자입니다.
예시 5:
이 코드에서 'main()' 메소드를 호출한 후 'int' 데이터 유형의 '7' 크기의 'myFirstArray'와 'double'의 크기 '7'의 'mySecondArray'인 두 개의 배열을 초기화합니다. 데이터 형식. 두 배열 모두에 값을 삽입합니다. 첫 번째 배열에는 '정수' 값을 삽입합니다. 두 번째 배열에는 'double' 값을 추가합니다. 그런 다음 'for'를 활용하고 이 루프에 'auto'를 삽입합니다.
여기서는 'myFirstArray'에 대해 'range base for' 루프를 사용합니다. 그런 다음 'cout'에 'myVar'를 배치합니다. 아래에 루프를 다시 배치하고 'range base for' 루프를 활용합니다. 이 루프는 'mySecondArray'에 대한 것이며 해당 배열의 값도 인쇄합니다.
코드 5:
#include사용하여 네임스페이스 성병 ;
정수 기본 ( )
{
정수 myFirstArray [ 7 ] = { 열 다섯 , 25 , 35 , 넷 다섯 , 55 , 65 , 75 } ;
더블 mySecondArray [ 7 ] = { 2.64 , 6.45 , 8.5 , 2.5 , 4.5 , 6.7 , 8.9 } ;
~을 위한 ( const 자동 & myVar : myFirstArray )
{
시합 << myVar << ' ' ;
}
시합 << 끝 ;
~을 위한 ( const 자동 & myVar : mySecondArray )
{
시합 << myVar << ' ' ;
}
반품 0 ;
}
산출:
두 벡터의 모든 데이터가 이 결과에 여기에 표시됩니다.

결론
'자동차용' 개념은 이 기사에서 철저하게 연구되었습니다. “auto”는 데이터 유형을 언급하지 않고 감지한다고 설명했습니다. 이 문서에서는 여러 예제를 살펴보고 여기에 코드 설명도 제공했습니다. 우리는 이 기사에서 '자동차용' 개념의 작동 방식을 자세히 설명했습니다.