이 기사에서는 다음의 중요성에 대해 알아볼 것입니다. 데이터 구조 , 다양한 유형의 데이터 구조 C++에서 사용할 수 있는 방법과 이를 프로그램에서 효과적으로 사용하는 방법.
C++의 데이터 구조란?
그만큼 데이터 구조 프로그래밍의 필수 개념이며 데이터를 저장하고 구성하는 데 중요한 역할을 합니다. C++에서 데이터 구조는 데이터를 특정 형식으로 저장하고 관리하는 방법으로 정의할 수 있습니다. 이를 통해 데이터에 대한 효율적인 액세스 및 조작이 가능하므로 프로그래머가 코드를 작성하고 유지 관리하기가 더 쉬워집니다.
C++에서는 데이터 구조 다음 구문이 있습니다.
구조체 구조_이름 {
데이터 유형1 이름1 ;
데이터 유형2 이름2 ;
데이터 유형3 이름3 ;
데이터 유형4 이름4 ;
..
..
..
} obj_name ;
위 구문에서 구조체 키워드 구조를 정의하는 데 사용되며 구조_이름 구조의 사용자 정의 이름이며 다를 수 있습니다. 그만큼 데이터 유형1 구조체 멤버의 데이터 유형 및 이름1 구조체 멤버의 이름이고 obj_name 구조가 정의된 개체의 이름입니다.
예
아래 예에서 구조 정보 세 명의 구성원으로 구성됩니다. 이름, 나이, 그리고 시민권.
구조체 정보
{
숯 이름 [ 오십 ] ;
정수 시민권 ;
정수 나이 ;
}
C++에서 이 코드를 실행해 봅시다. 우리는 이러한 모든 멤버를 person 구조에 정의하고 공간을 할당하지 않았습니다. 기본 함수에서 특정 값으로 이러한 멤버를 초기화하고 인쇄했습니다.
#include네임스페이스 표준 사용 ;
구조체 정보
{
문자열 이름 ;
정수 나이 ;
} ;
정수 기본 ( 무효의 ) {
구조체 정보 페이지 ;
피. 이름 = '자이나브' ;
피. 나이 = 23 ;
쿠우트 << '사람 이름: ' << 피. 이름 << 끝 ;
쿠우트 << '사람 나이: ' << 피. 나이 << 끝 ;
반품 0 ;
}
코드는 이름이 지정된 구조체를 정의합니다. 정보 이름과 나이의 두 가지 속성이 있습니다. 메인 함수에서 새로운 정보 객체가 생성되고 이름과 나이가 할당됩니다. 마지막으로 이 필드의 값은 cout을 사용하여 콘솔에 인쇄됩니다.
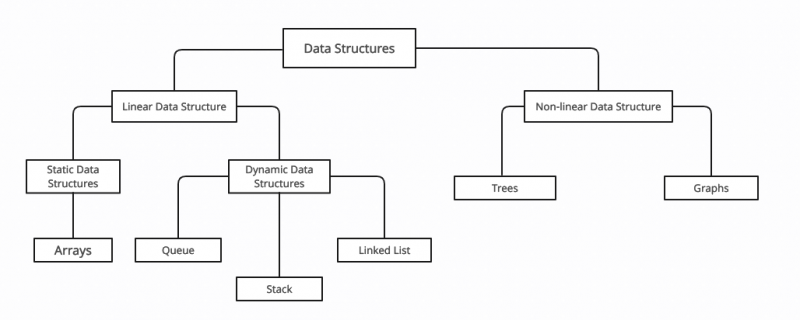
C++의 데이터 구조 분류
C++에서는 데이터 구조 크게 두 가지 범주로 나뉩니다. 선형 및 비선형 데이터 구조 . 데이터 구조는 다음 특성에 따라 구분됩니다.
| 특성 | 설명 | 예 |
| 선의 | 데이터는 선형 순서로 정렬됩니다. | 배열 |
| 비선형 | 데이터 항목이 선형 시퀀스가 아닙니다. | 그래프, 트리 |
| 공전 | 위치, 크기 및 메모리는 고정되어 있습니다. | 배열 |
| 동적 | 프로그램 실행에 따라 크기가 변경됨 | 연결된 목록 |
| 균질 | 항목은 동일한 유형입니다. | 배열 |
| 비균질 | 항목은 동일한 유형일 수도 있고 아닐 수도 있습니다. | 구조 |
C++의 데이터 구조 범주는 다음과 같습니다.
1: 어레이
배열은 C++의 가장 기본적인 데이터 구조입니다. 배열은 동일한 데이터 유형을 가진 요소 그룹입니다. 배열을 사용하면 전체 데이터 세트에 대한 작업을 더 쉽게 수행할 수 있습니다. 배열에 저장된 값을 요소라고 합니다.
2: 연결된 목록
연결된 목록의 데이터 요소는 노드를 통해 연결됩니다. 각 노드는 그 뒤에 오는 노드의 주소와 데이터를 가집니다. 노드를 추가하고 삭제하는 데 가장 적합합니다. 연결 리스트에는 단일 연결 리스트와 이중 연결 리스트 두 가지가 있습니다. 단일 연결 리스트에서 이전 노드는 다음 노드의 데이터를 가지고 있지만 다음 노드는 이전 노드를 인식하지 못합니다. 이중 연결 목록에서 방향은 앞과 뒤입니다.
3: 스택
스택은 LIFO(Last In First Out) 원칙을 따르는 추상 데이터 유형입니다. 이 규칙은 마지막에 삽입된 요소가 먼저 삭제됨을 의미합니다. 재귀 역추적 알고리즘과 함께 사용됩니다.
4: 꼬리
대기열은 또한 추상 데이터 유형이며 FIFO(First In and First Out) 규칙을 따릅니다. 이 규칙은 먼저 삽입된 요소가 먼저 삭제됨을 의미합니다. 실시간 시스템 해석을 처리하는 동안 유용합니다.
5: 나무
트리는 여러 노드가 있는 비선형 데이터 구조 집합입니다. 두 개의 꼭지점이 있는 하나의 가장자리만 허용합니다.
6: 그래프
그래프에서 각 노드는 정점이며 각 정점은 가장자리를 통해 다른 정점에 연결됩니다. 구체는 정점이고 화살표는 가장자리이며 실제 시나리오 또는 신경망을 구현하는 데 사용됩니다. 그래프에는 무방향 그래프, 양방향 그래프 및 가중 그래프의 세 가지 유형이 있습니다.
데이터 구조에서 수행되는 작업
C++의 데이터 구조에서 다음 기능을 수행할 수 있습니다.
- 데이터 구조에 새로운 데이터 요소 삽입.
- 데이터 구조에서 기존 데이터 요소 제거.
- 데이터 구조의 모든 데이터 요소를 표시합니다.
- 데이터 구조에서 특정 요소를 검색합니다.
- 모든 요소를 오름차순 또는 내림차순으로 정렬합니다.
- 두 데이터 구조의 요소를 결합하고 새 구조를 만듭니다.
결론
C++의 데이터 구조는 액세스할 수 있도록 데이터를 효율적으로 처리하는 방법입니다. 데이터를 순차적으로 추가하려는 경우 프로젝트에 적합한 데이터 구조를 선택하는 것이 중요합니다. 그런 다음 배열로 이동하십시오. 데이터 구조 개념을 이해하면 프로그래밍 및 알고리즘 설계 기술을 마스터하는 데 도움이 됩니다.