C++에서 벡터는 요구 사항에 따라 동적으로 증가하는 1차원 데이터 구조입니다. 이러한 데이터 구조에서는 데이터 정리(삽입/수정/삭제)를 효율적으로 할 수 있습니다. 그 응용 프로그램은 다음과 같습니다:
- 과학 및 공학 응용 분야에서 수학적 벡터 표현
- 이 데이터 구조 등을 사용하여 큐, 스택을 구현할 수 있습니다.
이 데이터 구조와 관련된 대부분의 일반적인 CRUD 작업 및 기능은 구문 및 코드 조각과 함께 시나리오별로 자세히 설명됩니다.
목차 주제:
- 벡터에 요소 삽입
- 벡터에 여러 요소 삽입
- 벡터에서 요소에 액세스
- 벡터의 요소 업데이트
- 벡터에서 특정 요소 제거
- 벡터에서 모든 요소 제거
- 벡터의 합집합
- 벡터의 교차점
- 벡터가 비어 있는지 확인
- Const_Iterator를 사용하여 벡터 탐색
- Reverse_Iterator를 사용하여 벡터 탐색
- 요소를 벡터에 밀어 넣기
- 벡터에서 요소 팝
- 벡터 교환
- 벡터에서 첫 번째 요소를 가져옵니다.
- 벡터에서 마지막 요소를 가져옵니다.
- 벡터에 새 값 할당
- Emplace()를 사용하여 벡터 확장
- Emplace_Back()을 사용하여 벡터 확장
- 벡터의 최대 요소
- 벡터의 최소 요소
- 벡터 요소의 합
- 두 벡터의 요소별 곱셈
- 두 벡터의 내적
- 세트를 벡터로 변환
- 중복 요소 제거
- 벡터를 집합으로 변환
- 빈 문자열 제거
- 텍스트 파일에 벡터 쓰기
- 텍스트 파일에서 벡터 만들기
벡터에 요소 삽입
그만큼 표준::벡터::삽입() C++ STL의 함수는 지정된 위치에 요소를 삽입하는 데 사용됩니다.
통사론:
벡터. 끼워 넣다 ( 위치, 요소 ) ;이 함수를 활용하여 첫 번째 위치를 요소가 삽입되어야 하는 위치를 지정하는 매개변수로 전달하고 해당 요소를 두 번째 매개변수로 제공하겠습니다.
여기서는 Begin() 함수를 사용하여 입력 벡터의 첫 번째 요소를 가리키는 반복자를 반환할 수 있습니다. 이 함수에 위치를 추가하면 해당 위치에 요소가 삽입됩니다.
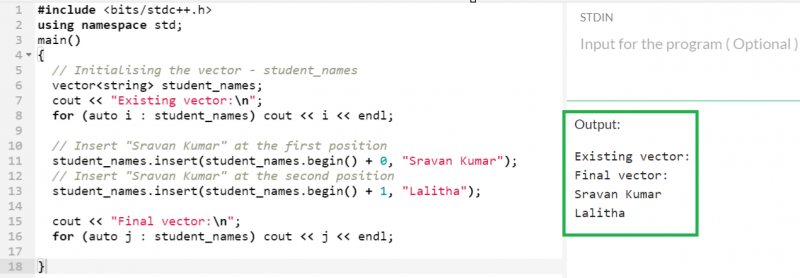
string 유형의 'student_names' 벡터를 생성하고 insert() 함수를 사용하여 첫 번째와 두 번째 위치에 두 개의 문자열을 차례로 삽입해 보겠습니다.
#include사용하여 네임스페이스 성병 ;
기본 ( )
{
// 벡터 초기화 - Student_names
벡터 < 끈 > 학생_이름 ;
시합 << '기존 벡터: \N ' ;
~을 위한 ( 자동 나 : 학생_이름 ) 시합 << 나 << 끝 ;
// 첫 번째 위치에 'Sravan Kumar' 삽입
학생_이름. 끼워 넣다 ( 학생_이름. 시작하다 ( ) + 0 , '쉬라반 쿠마르' ) ;
// 두 번째 위치에 'Sravan Kumar' 삽입
학생_이름. 끼워 넣다 ( 학생_이름. 시작하다 ( ) + 1 , '라리타' ) ;
시합 << '최종 벡터: \N ' ;
~을 위한 ( 자동 제이 : 학생_이름 ) 시합 << 제이 << 끝 ;
}
산출:
이전에는 'student_names' 벡터가 비어 있었습니다. 삽입 후 벡터에는 두 개의 요소가 포함됩니다.
벡터에 여러 요소 삽입
이 시나리오에서는 std::Vector::insert()와 동일한 함수를 사용합니다. 하지만 여러 요소를 벡터에 삽입하려면 동일한 함수에 추가/다른 매개변수를 전달해야 합니다.
시나리오 1: 단일 요소를 여러 번 삽입
이 시나리오에서는 동일한 요소를 여러 번 추가합니다.
통사론:
벡터. 끼워 넣다 ( 위치, 크기, 요소 ) ;이렇게 하려면 크기를 insert() 함수의 두 번째 매개변수로 전달해야 합니다. 이 함수에 전달되는 총 매개변수는 3개입니다.
여기:
- position 매개변수는 삽입할 요소의 위치를 지정합니다. 크기가 1보다 큰 경우 시작 위치 인덱스가 위치가 됩니다.
- size 매개변수는 요소가 삽입되는 횟수를 지정합니다.
- 요소 매개변수는 벡터에 삽입할 요소를 사용합니다.
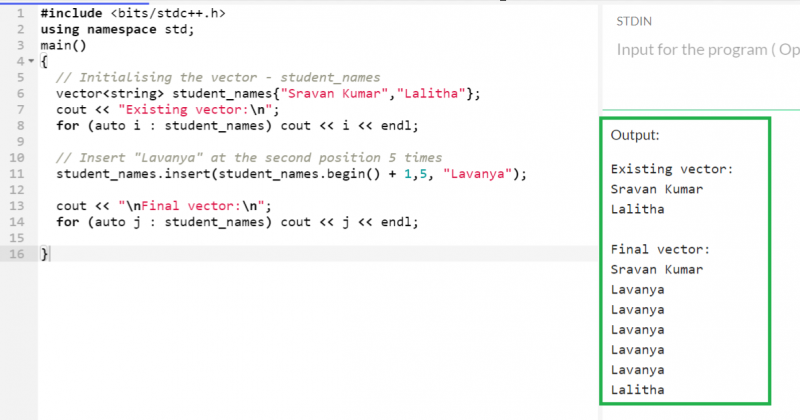
두 개의 문자열이 있는 'student_names' 벡터를 생각해 보세요. 두 번째 위치에 'Lavanya' 문자열을 5번 삽입합니다.
#include사용하여 네임스페이스 성병 ;
기본 ( )
{
// 벡터 초기화 - Student_names
벡터 < 끈 > 학생_이름 { '쉬라반 쿠마르' , '라리타' } ;
시합 << '기존 벡터: \N ' ;
~을 위한 ( 자동 나 : 학생_이름 ) 시합 << 나 << 끝 ;
// 두 번째 위치에 'Lavanya'를 5번 삽입
학생_이름. 끼워 넣다 ( 학생_이름. 시작하다 ( ) + 1 , 5 , '라반야' ) ;
시합 << ' \N 최종 벡터: \N ' ;
~을 위한 ( 자동 제이 : 학생_이름 ) 시합 << 제이 << 끝 ;
}
산출:
기존 벡터에서는 'Sravan Kumar'가 첫 번째 위치에 있고 'Lalitha'가 두 번째 위치에 있습니다. '라반야'를 5번 삽입(두 번째 위치에서 여섯 번째 위치)한 후 '랄리타'는 일곱 번째 위치(마지막)로 이동했습니다.
시나리오 2: 여러 요소 삽입
이 시나리오에서는 다른 벡터에서 다른 요소를 한 번에 추가합니다. 여기서도 동일한 기능을 사용하지만 구문과 매개변수가 변경됩니다.
통사론:
벡터. 끼워 넣다 ( 위치, 첫 번째_반복자, 두 번째_반복자 ) ;이렇게 하려면 크기를 insert() 함수의 두 번째 매개변수로 전달해야 합니다. 이 함수에 전달되는 총 매개변수는 3개입니다.
여기:
- position 매개변수는 삽입할 요소의 위치를 지정합니다.
- 'first_iterator'는 요소가 삽입될 시작 위치를 지정합니다. (기본적으로 start() 함수를 사용하면 컨테이너에 있는 첫 번째 요소를 가리키는 반복자가 반환됩니다.)
- 'second_iterator'는 요소가 삽입될 종료 위치를 지정합니다(기본적으로 end() 함수를 사용하면 컨테이너에 있는 마지막 지점 옆을 가리키는 반복자가 반환됩니다).
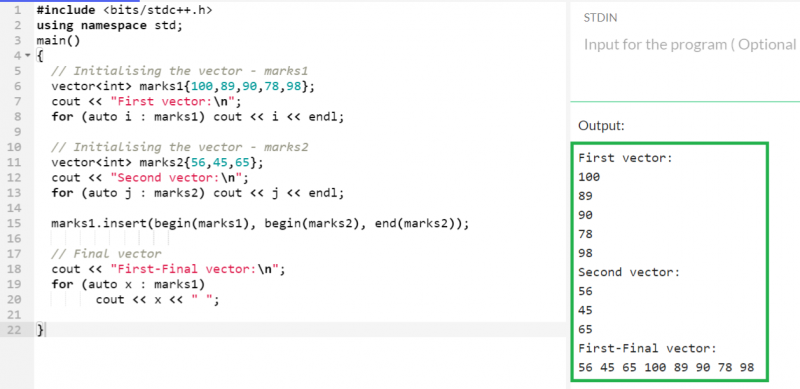
정수형의 두 벡터 'marks1'과 'marks2'를 만듭니다. 'marks2' 벡터에 있는 모든 요소를 'marks1' 벡터의 첫 번째 위치에 삽입합니다.
#include사용하여 네임스페이스 성병 ;
기본 ( )
{
// 벡터 초기화 - mark1
벡터 < 정수 > 마크1 { 100 , 89 , 90 , 78 , 98 } ;
시합 << '첫 번째 벡터: \N ' ;
~을 위한 ( 자동 나 : 마크1 ) 시합 << 나 << 끝 ;
// 벡터 초기화 - mark2
벡터 < 정수 > 마크2 { 56 , 넷 다섯 , 65 } ;
시합 << '두 번째 벡터: \N ' ;
~을 위한 ( 자동 제이 : 마크2 ) 시합 << 제이 << 끝 ;
마크1. 끼워 넣다 ( 시작하다 ( 마크1 ) , 시작하다 ( 마크2 ) , 끝 ( 마크2 ) ) ;
// 최종 벡터
시합 << '첫 번째 최종 벡터: \N ' ;
~을 위한 ( 자동 엑스 : 마크1 )
시합 << 엑스 << ' ' ;
}
산출:
첫 번째 벡터(marks1)는 5개의 요소를 포함하고 두 번째 벡터(marks2)는 3개의 요소를 포함합니다. 두 번째 벡터에 있는 모든 요소가 반복되어 처음에 첫 번째 벡터에 삽입되도록 start(marks1), start(marks2), end(marks2) 매개 변수를 'insert' 함수에 전달했습니다. 따라서 첫 번째 벡터에는 8개의 요소가 포함됩니다.
벡터에서 요소에 액세스
1. [] 연산자 사용
일부 시나리오에서는 벡터에서 특정 요소만 반환해야 할 수도 있습니다. 모든 요소를 반환할 필요는 없습니다. 따라서 인덱스를 기준으로 특정 요소만 반환하기 위해서는 인덱스 연산자와 at() 함수를 활용합니다.
통사론:
벡터 [ index_position ]C++에서는 모든 데이터 구조에 대해 인덱싱이 0부터 시작됩니다. 요소가 존재하지 않으면 비어 있는 값을 반환합니다(오류가 없거나 경고가 발생함).
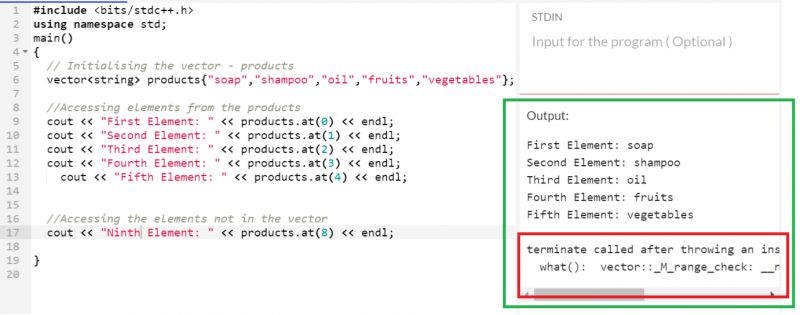
5개의 항목이 있는 '제품' 벡터를 생각해 보세요. 인덱스 위치를 사용하여 모든 요소에 하나씩 액세스합니다.
#include사용하여 네임스페이스 성병 ;
기본 ( )
{
// 벡터 생성 - 문자열이 5개인 제품
벡터 < 끈 > 제품 { '비누' , '샴푸' , '기름' , '과일' , '채소' } ;
//제품의 요소에 접근
시합 << '첫 번째 요소: ' << 제품 [ 0 ] << 끝 ;
시합 << '두 번째 요소: ' << 제품 [ 1 ] << 끝 ;
시합 << '세 번째 요소: ' << 제품 [ 2 ] << 끝 ;
시합 << '네 번째 요소: ' << 제품 [ 삼 ] << 끝 ;
시합 << '다섯 번째 요소: ' << 제품 [ 4 ] << 끝 ;
// 9번째 요소에 접근을 시도합니다.
시합 << '아홉 번째 요소: ' << 제품 [ 8 ] << 끝 ;
}
산출:
인덱스 8에는 요소가 없습니다. 따라서 비어 있는 값이 반환됩니다.

2. At() 함수 사용하기
At()는 이전 사용 사례와 유사한 멤버 함수이지만 범위를 벗어난 인덱스가 제공되면 'std::out_of_range' 예외를 반환합니다.
통사론:
벡터. ~에 ( index_position )이 함수에 인덱스 위치를 전달해야 합니다.
5개의 항목이 있는 '제품' 벡터를 생각해 보세요. 인덱스 위치를 이용하여 모든 요소에 하나씩 접근하고, 9번째 위치에 있는 요소에 접근을 시도합니다.
#include사용하여 네임스페이스 성병 ;
기본 ( )
{
// 벡터 생성 - 문자열이 5개인 제품
벡터 < 끈 > 제품 { '비누' , '샴푸' , '기름' , '과일' , '채소' } ;
//제품의 요소에 접근
시합 << '첫 번째 요소: ' << 제품. ~에 ( 0 ) << 끝 ;
시합 << '두 번째 요소: ' << 제품. ~에 ( 1 ) << 끝 ;
시합 << '세 번째 요소: ' << 제품. ~에 ( 2 ) << 끝 ;
시합 << '네 번째 요소: ' << 제품. ~에 ( 삼 ) << 끝 ;
시합 << '다섯 번째 요소: ' << 제품. ~에 ( 4 ) << 끝 ;
//벡터에 없는 요소에 액세스
시합 << '아홉 번째 요소: ' << 제품. ~에 ( 8 ) << 끝 ;
}
산출:
9번째 요소에 액세스할 때 오류가 발생합니다.
인스턴스를 던진 후 호출되는 종료 '표준::범위 밖'무엇 ( ) : 벡터 :: _M_범위_체크 : __N ( 이는 8 ) >= 이것 - > 크기 ( ) ( 이는 5 )
벡터의 요소 업데이트
1. [] 연산자 사용
인덱스 위치를 사용하여 벡터의 요소를 업데이트할 수 있습니다. [] 연산자는 업데이트해야 하는 요소의 인덱스 위치를 사용합니다. 새 요소가 이 연산자에 할당됩니다.
통사론:
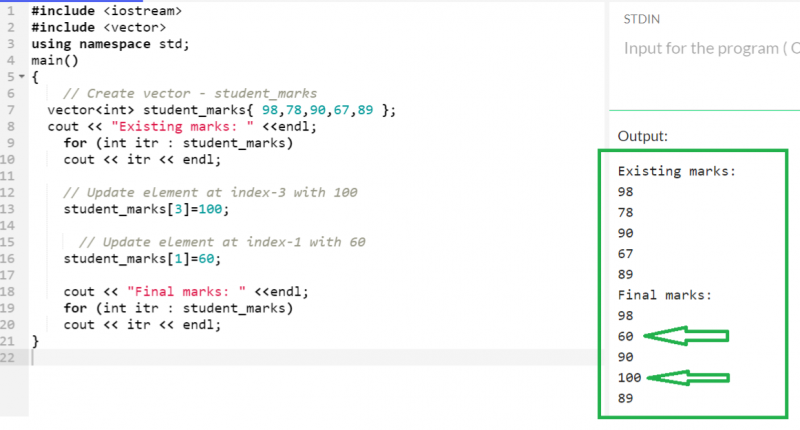
벡터 [ index_position ] = 요소5개의 값을 가진 'student_marks' 벡터를 생각해 보세요. 인덱스 1과 3에 있는 요소를 업데이트합니다.
#include#include <벡터>
사용하여 네임스페이스 성병 ;
기본 ( )
{
// 벡터 생성 - Student_marks
벡터 < 정수 > 학생_마크 { 98 , 78 , 90 , 67 , 89 } ;
시합 << '기존 마크: ' << 끝 ;
~을 위한 ( 정수 그것 : 학생_마크 )
시합 << 그것 << 끝 ;
// 인덱스 3의 요소를 100으로 업데이트합니다.
학생_마크 [ 삼 ] = 100 ;
// index-1의 요소를 60으로 업데이트합니다.
학생_마크 [ 1 ] = 60 ;
시합 << '최종 점수: ' << 끝 ;
~을 위한 ( 정수 그것 : 학생_마크 )
시합 << 그것 << 끝 ;
}
산출:
최종 벡터에는 인덱스 1과 3에 업데이트 요소가 포함되어 있음을 알 수 있습니다.
2. At() 함수 사용하기
인덱스 연산자와 유사하게 at()은 기본적으로 반복자의 인덱스를 기반으로 값을 업데이트하는 멤버 함수입니다. 이 함수 내에 지정된 인덱스가 존재하지 않으면 “std::out_of_range” 예외가 발생합니다.
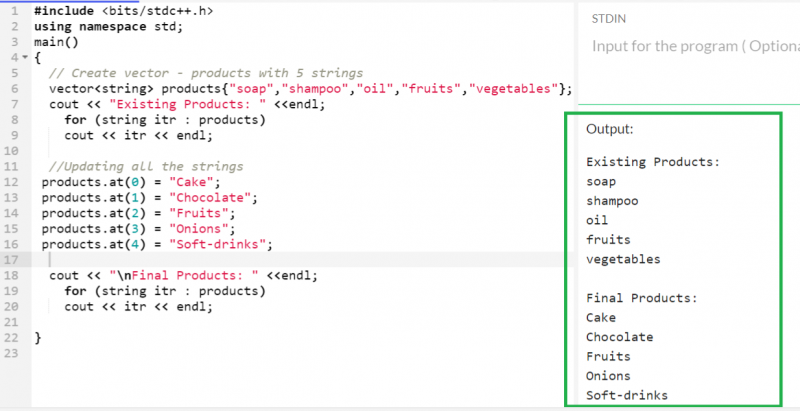
벡터. ~에 ( index_position ) = 요소5개의 항목이 있는 '제품' 벡터를 생각해 보세요. 벡터에 있는 모든 요소를 다른 요소로 업데이트합니다.
#include사용하여 네임스페이스 성병 ;
기본 ( )
{
// 벡터 생성 - 문자열이 5개인 제품
벡터 < 끈 > 제품 { '비누' , '샴푸' , '기름' , '과일' , '채소' } ;
시합 << '기존 제품: ' << 끝 ;
~을 위한 ( 문자열 itr : 제품 )
시합 << 그것 << 끝 ;
//모든 문자열 업데이트
제품. ~에 ( 0 ) = '케이크' ;
제품. ~에 ( 1 ) = '초콜릿' ;
제품. ~에 ( 2 ) = '과일' ;
제품. ~에 ( 삼 ) = '양파' ;
제품. ~에 ( 4 ) = '청량 음료' ;
시합 << ' \N 최종 제품: ' << 끝 ;
~을 위한 ( 문자열 itr : 제품 )
시합 << 그것 << 끝 ;
}
산출:
벡터에서 특정 요소 제거
C++에서는 표준::벡터::지우기() 함수는 벡터에서 특정 요소/요소 범위를 제거하는 데 사용됩니다. 반복자 위치에 따라 요소가 제거됩니다.
통사론:
벡터. 삭제 ( 반복자 위치 )벡터에서 특정 요소를 제거하는 구문을 살펴보겠습니다. 제거할 벡터에 있는 요소의 위치를 가져오기 위해 Begin() 또는 end() 함수를 활용할 수 있습니다.
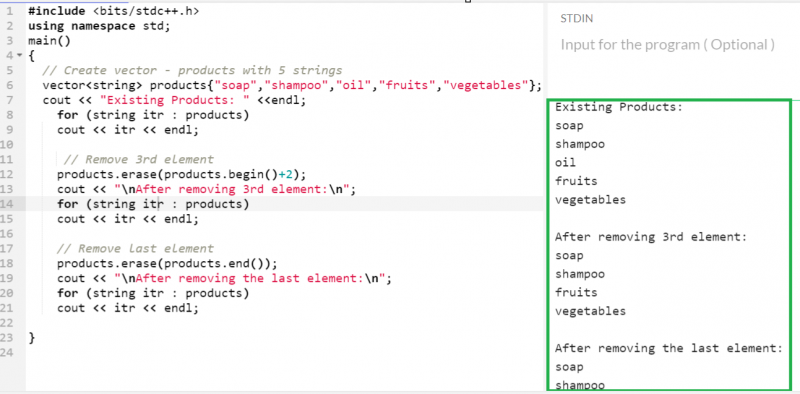
5개의 항목이 있는 '제품' 벡터를 생각해 보세요.
- Begin() 반복자를 지정하여 세 번째 요소를 제거합니다. Begin()은 벡터의 첫 번째 요소를 가리킵니다. 이 함수에 2개를 추가하면 세 번째 요소를 가리킵니다.
- end() 반복자를 지정하여 마지막 요소를 제거합니다. End()는 벡터의 마지막 요소를 가리킵니다.
사용하여 네임스페이스 성병 ;
기본 ( )
{
// 벡터 생성 - 문자열이 5개인 제품
벡터 < 끈 > 제품 { '비누' , '샴푸' , '기름' , '과일' , '채소' } ;
시합 << '기존 제품: ' << 끝 ;
~을 위한 ( 문자열 itr : 제품 )
시합 << 그것 << 끝 ;
// 세 번째 요소 제거
제품. 삭제 ( 제품. 시작하다 ( ) + 2 ) ;
시합 << ' \N 세 번째 요소를 제거한 후: \N ' ;
~을 위한 ( 문자열 itr : 제품 )
시합 << 그것 << 끝 ;
// 마지막 요소 제거
제품. 삭제 ( 제품. 끝 ( ) ) ;
시합 << ' \N 마지막 요소를 제거한 후: \N ' ;
~을 위한 ( 문자열 itr : 제품 )
시합 << 그것 << 끝 ;
}
산출:
이제 “products” 벡터에는 세 가지 요소(“soap”, “shampoo”, “fruits”)만 존재합니다.
벡터에서 모든 요소 제거
시나리오 1: 벡터에서 요소 범위 제거
std::벡터::erase() 함수를 사용하여 범위의 여러 요소를 제거해 보겠습니다.
통사론:
벡터. 삭제 ( 반복자 먼저, 반복자 마지막 )두 개의 반복자(begin()은 첫 번째 요소를 가리키고 end()는 마지막 요소 함수를 가리킴)는 범위를 지정하는 데 사용됩니다.
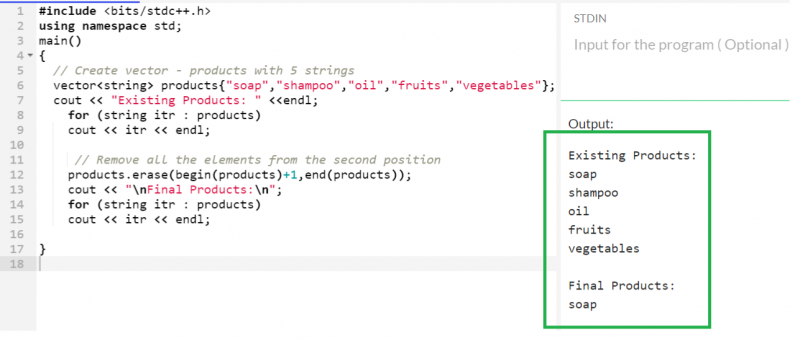
5개 항목이 있는 '제품' 벡터를 고려하고 두 번째 위치에서 모든 요소를 제거합니다. 이를 달성하기 위해 첫 번째 반복자는 두 번째 요소를 가리키는 시작(제품)+1이고 두 번째 반복자는 끝(제품)입니다.
#include사용하여 네임스페이스 성병 ;
기본 ( )
{
// 벡터 생성 - 문자열이 5개인 제품
벡터 < 끈 > 제품 { '비누' , '샴푸' , '기름' , '과일' , '채소' } ;
시합 << '기존 제품: ' << 끝 ;
~을 위한 ( 문자열 itr : 제품 )
시합 << 그것 << 끝 ;
// 두 번째 위치의 모든 요소를 제거합니다.
제품. 삭제 ( 시작하다 ( 제품 ) + 1 ,끝 ( 제품 ) ) ;
시합 << ' \N 최종 제품: \N ' ;
~을 위한 ( 문자열 itr : 제품 )
시합 << 그것 << 끝 ;
}
산출:
이제 'products' 벡터에는 단 하나의 요소('soap')만 있습니다.
시나리오 2: 벡터에서 모든 요소 제거
다음을 사용해보자 표준::벡터::클리어() 벡터에서 모든 요소를 제거하는 함수입니다.
통사론:
벡터. 분명한 ( )이 함수에는 매개변수가 전달되지 않습니다.
첫 번째 시나리오에서 활용된 동일한 벡터를 고려하고 Clear() 함수를 사용하여 모든 요소를 제거합니다.
#include사용하여 네임스페이스 성병 ;
기본 ( )
{
// 벡터 생성 - 문자열이 5개인 제품
벡터 < 끈 > 제품 { '비누' , '샴푸' , '기름' , '과일' , '채소' } ;
시합 << '기존 제품: ' << 끝 ;
~을 위한 ( 문자열 itr : 제품 )
시합 << 그것 << 끝 ;
// 제품에서 모든 요소를 제거합니다.
제품. 분명한 ( ) ;
시합 << ' \N 최종 제품: \N ' ;
~을 위한 ( 문자열 itr : 제품 )
시합 << 그것 << 끝 ;
}
산출:
'products' 벡터에는 요소가 없음을 알 수 있습니다.
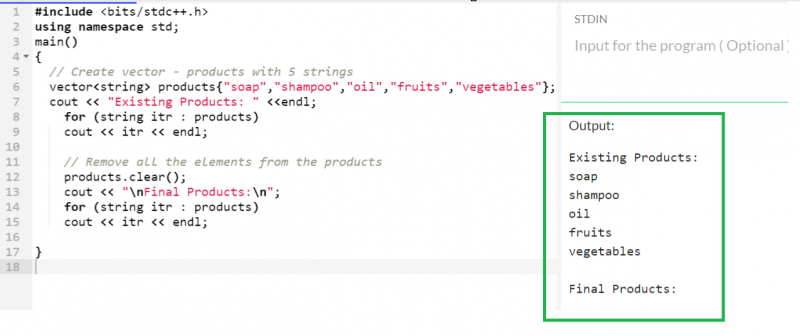
벡터의 합집합
std::set_union() 함수를 사용하여 벡터에 UNION 연산을 수행하는 것이 가능합니다. Union은 중복 요소를 무시하여 벡터에서 고유한 요소를 반환합니다. 이 함수에 두 반복자를 모두 전달해야 합니다. 이와 함께 두 반복기에서 반환된 결과를 저장하는 출력 반복기를 전달해야 합니다.
통사론:
세트_유니온 ( InputIterator1 first1, InputIterator1 last1, InputIterator2 first2, InputIterator2 last2, OutputIterator res ) ;여기:
- 'first1'은 첫 번째 반복기(벡터)의 첫 번째 요소를 가리킵니다.
- 'last1'은 첫 번째 반복기(벡터)의 마지막 요소를 가리킵니다.
- 'first2'는 두 번째 반복기(벡터)의 첫 번째 요소를 가리킵니다.
- 'last2'는 두 번째 반복기(벡터)의 마지막 요소를 가리킵니다.
정수 유형의 두 벡터('subjects1' 및 'subjects2')를 만듭니다.
- 반복자를 전달하여 sort() 함수를 사용하여 두 벡터를 정렬합니다.
- 출력 벡터(반복자)를 만듭니다.
- std::set_union() 함수를 사용하여 이 두 벡터의 합집합을 찾습니다. start()를 첫 번째 반복자로 사용하고 end()를 마지막 반복자로 사용합니다.
- 출력 벡터를 반복하여 함수에서 반환된 요소를 표시합니다.
#include
#include <벡터>
사용하여 네임스페이스 성병 ;
기본 ( )
{
// 벡터 생성 - mark1
벡터 < 정수 > 마크1 = { 100 , 90 , 80 , 70 , 60 } ;
// 벡터 생성 - mark2
벡터 < 정수 > 마크2 = { 80 , 90 , 60 , 70 , 100 } ;
// 두 벡터를 모두 정렬합니다.
종류 ( 마크1. 시작하다 ( ) , 마크1. 끝 ( ) ) ;
종류 ( 마크2. 시작하다 ( ) , 마크2. 끝 ( ) ) ;
벡터 < 정수 > 출력벡터 ( 마크1. 크기 ( ) + 마크2. 크기 ( ) ) ;
벡터 < 정수 > :: 반복자 이다 ;
나 = 세트_유니온 ( 마크1. 시작하다 ( ) , 마크1. 끝 ( ) ,
마크2. 시작하다 ( ) ,마크2. 끝 ( ) ,
출력벡터. 시작하다 ( ) ) ;
시합 << ' \N 마크1 U 마크2: \N ' ;
~을 위한 ( 에스 = 출력벡터. 시작하다 ( ) ; 에스 ! = 나 ; ++ 에스 )
시합 << * 에스 << ' ' << ' \N ' ;
}
산출:
두 벡터(subjects1 및 subjects2)에는 5개의 고유 요소만 있습니다.
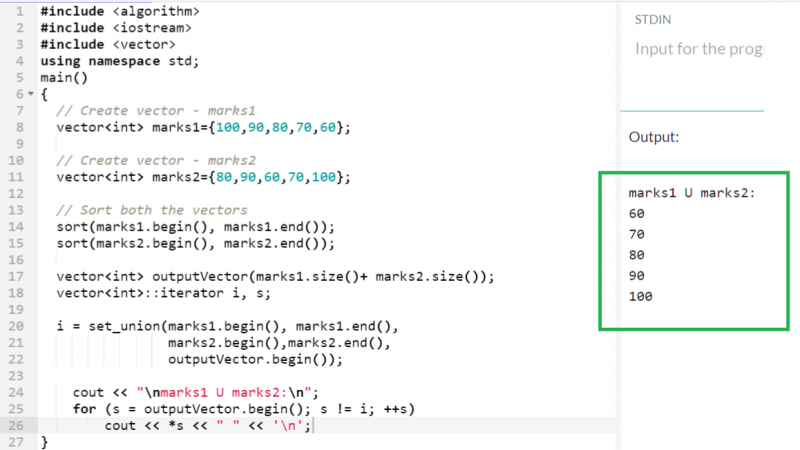
벡터의 교차점
std::set_intersection() 함수를 사용하면 두 벡터의 교차점을 찾는 것이 가능합니다. Intersection은 두 벡터에 모두 존재하는 요소를 반환합니다.
통사론:
set_intersection ( InputIterator1 first1, InputIterator1 last1, InputIterator2 first2, InputIterator2 last2, OutputIterator res ) ;set_union() 함수에 전달된 매개변수는 이 set_intersection() 함수에도 전달될 수 있습니다.
정수 유형의 두 벡터('subjects1' 및 'subjects2')를 만듭니다.
- 반복자를 전달하여 sort() 함수를 사용하여 두 벡터를 정렬합니다.
- 출력 벡터(반복자)를 만듭니다.
- std::set_intersection() 함수를 사용하여 이 두 벡터의 교차점을 찾으십시오. start()를 첫 번째 반복자로 사용하고 end()를 마지막 반복자로 사용합니다.
- 출력 벡터를 반복하여 함수에서 반환된 요소를 표시합니다.
#include
#include <벡터>
사용하여 네임스페이스 성병 ;
기본 ( )
{
// 벡터 생성 - mark1
벡터 < 정수 > 마크1 = { 100 , 10 , 80 , 40 , 60 } ;
// 벡터 생성 - mark2
벡터 < 정수 > 마크2 = { 오십 , 90 , 60 , 10 , 100 } ;
// 두 벡터를 모두 정렬합니다.
종류 ( 마크1. 시작하다 ( ) , 마크1. 끝 ( ) ) ;
종류 ( 마크2. 시작하다 ( ) , 마크2. 끝 ( ) ) ;
벡터 < 정수 > 출력벡터 ( 마크1. 크기 ( ) + 마크2. 크기 ( ) ) ;
벡터 < 정수 > :: 반복자 이다 ;
나 = set_intersection ( 마크1. 시작하다 ( ) , 마크1. 끝 ( ) ,
마크2. 시작하다 ( ) ,마크2. 끝 ( ) ,
출력벡터. 시작하다 ( ) ) ;
시합 << ' \N 마크1 ∩ 마크2: \N ' ;
~을 위한 ( 에스 = 출력벡터. 시작하다 ( ) ; 에스 ! = 나 ; ++ 에스 )
시합 << * 에스 << ' ' << ' \N ' ;
}
산출:
두 벡터(subjects1 및 subjects2)에는 세 가지 요소만 있습니다.
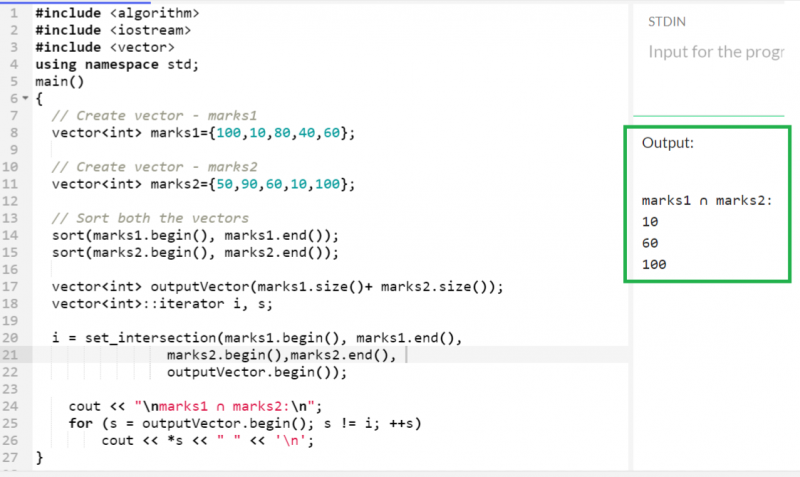
벡터가 비어 있는지 확인
벡터 작업을 하기 전에 벡터가 비어 있는지 확인하는 것이 중요합니다. CRUD 작업 등과 같은 작업을 수행하기 전에 벡터가 비어 있는지 여부를 확인하는 것도 소프트웨어 프로젝트에서 좋은 습관입니다.
1. Std::벡터::empty() 사용
이 함수는 벡터가 비어 있으면(어떤 요소도 포함하지 않음) 1을 반환합니다. 그렇지 않으면 0이 반환됩니다. 이 함수에는 매개변수가 전달되지 않습니다.
2. 사용하기 표준::벡터::크기()
std::벡터::size() 함수는 벡터에 존재하는 요소의 총 개수를 나타내는 정수를 반환합니다.
'college1'과 'college2'라는 두 개의 벡터를 만듭니다. 'College1'에는 5개의 요소가 있고 'college2'는 비어 있습니다. 두 벡터에 두 함수를 모두 적용하고 출력을 확인합니다.
#include <알고리즘>#include
#include <벡터>
사용하여 네임스페이스 성병 ;
기본 ( )
{
// 벡터 생성 - College1
벡터 < 끈 > 대학1 = { '대학-A' , '대학-B' , '대학-C' , '대학-D' , '대학-E' } ;
// 벡터 생성 - College2
벡터 < 끈 > 대학2 ;
// 비어 있는()
시합 << 대학1. 비어 있는 ( ) << 끝 ;
시합 << 대학2. 비어 있는 ( ) << 끝 ;
// 크기()
시합 << 대학1. 크기 ( ) << 끝 ;
시합 << 대학2. 크기 ( ) << 끝 ;
}
산출:
empty() 함수는 'college1'에 대해 0을 반환하고 'college2'에 대해 1을 반환합니다. size() 함수는 'college1'에 대해 5를 반환하고 'college2'에 대해 0을 반환합니다.

Const_Iterator를 사용하여 벡터 탐색
세트, 벡터 등과 같은 C++ 컨테이너에서 작업할 때 컨테이너에 있는 모든 요소를 수정하지 않고 반복할 수 있습니다. 그만큼 const_iterator 이 시나리오를 달성하는 반복자 중 하나입니다. cbegin()(벡터의 첫 번째 요소를 가리킴) 및 cend()(벡터의 마지막 요소를 가리킴)는 상수 반복자를 벡터의 시작과 끝으로 반환하는 데 사용되는 각 컨테이너에서 제공하는 두 가지 함수입니다. 컨테이너. 벡터를 반복하는 동안 이 두 가지 기능을 활용할 수 있습니다.
- 5개의 문자열을 사용하여 'departments'라는 벡터를 만들어 보겠습니다.
- const_iterator(
유형의 ctr)를 선언합니다. - 'for' 루프를 사용하여 이전 반복자를 사용하여 부서를 반복하고 표시합니다.
#include <벡터>
사용하여 네임스페이스 성병 ;
기본 ( )
{
// 벡터 생성 - 부서
벡터 < 끈 > 부서 = { '매상' , '서비스' ,
'인사' , '그것' , '기타' } ;
벡터 < 끈 > :: const_iterator 클릭률 ;
// const_iterator - ctr을 사용하여 부서를 반복합니다.
~을 위한 ( 클릭률 = 부서. cbegin ( ) ; 클릭률 ! = 부서. 몇 가지 ( ) ; 클릭률 ++ ) {
시합 << * 클릭률 << 끝 ;
}
}
산출:

Reverse_Iterator를 사용하여 벡터 탐색
그만큼 역방향_반복자 const_iterator와 유사한 반복자이지만 요소를 역으로 반환합니다. rbegin()(벡터의 마지막 요소를 가리킴)과 rend()(벡터의 첫 번째 요소를 가리킴)는 각 컨테이너에서 제공하는 두 가지 함수로, 상수 반복자를 벡터의 끝과 시작 부분으로 반환하는 데 사용됩니다. 컨테이너.
- 5개의 문자열을 사용하여 'departments'라는 벡터를 만들어 보겠습니다.
-
유형의 reverse_iterator – rtr을 선언합니다. - 'for' 루프를 사용하여 이전 반복자를 사용하여 부서를 반복하고 표시합니다.
#include <벡터>
사용하여 네임스페이스 성병 ;
기본 ( )
{
// 벡터 생성 - 부서
벡터 < 끈 > 부서 = { '매상' , '서비스' ,
'인사' , '그것' , '기타' } ;
벡터 < 끈 > :: 역방향_반복자 rtr ;
// reverse_iterator - rtr을 사용하여 부서를 반복합니다.
~을 위한 ( rtr = 부서. rbegin ( ) ; rtr ! = 부서. 만든다 ( ) ; rtr ++ ) {
시합 << * rtr << 끝 ;
}
}
산출:

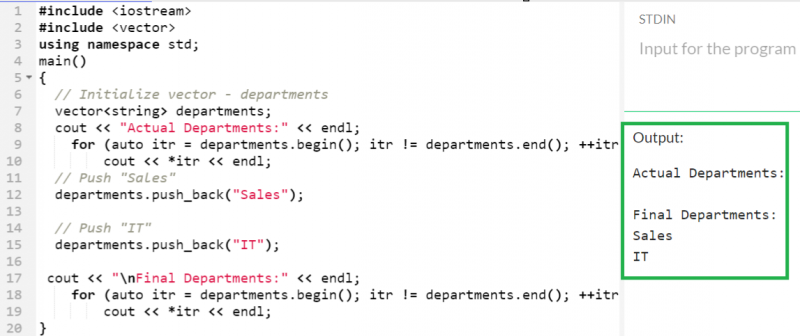
요소를 벡터에 밀어 넣기
요소를 벡터에 밀어넣거나 추가하는 것은 다음을 사용하여 수행할 수 있는 단방향 삽입입니다. 벡터::push_back() 기능.
통사론:
벡터. push_back ( 요소 )벡터에 매개변수로 푸시할 요소가 필요합니다.
5개의 문자열이 포함된 'departments'라는 빈 벡터를 만들고 push_back() 함수를 사용하여 두 문자열을 차례로 푸시해 보겠습니다.
#include#include <벡터>
사용하여 네임스페이스 성병 ;
기본 ( )
{
// 벡터 초기화 - 부서
벡터 < 끈 > 부서 ;
시합 << '실제 부서:' << 끝 ;
~을 위한 ( 자동 그것 = 부서. 시작하다 ( ) ; 그것 ! = 부서. 끝 ( ) ; ++ 그것 )
시합 << * 그것 << 끝 ;
// '판매'를 누릅니다.
부서. push_back ( '매상' ) ;
// 밀어'
부서. push_back ( '그것' ) ;
시합 << ' \N 최종 부서:' << 끝 ;
~을 위한 ( 자동 그것 = 부서. 시작하다 ( ) ; 그것 ! = 부서. 끝 ( ) ; ++ 그것 )
시합 << * 그것 << 끝 ;
}
산출:
먼저 '판매'를 푸시합니다. 그 후 'IT'가 벡터에 푸시됩니다. 이제 'departments' 벡터에는 두 개의 요소가 있습니다.
벡터에서 요소 팝
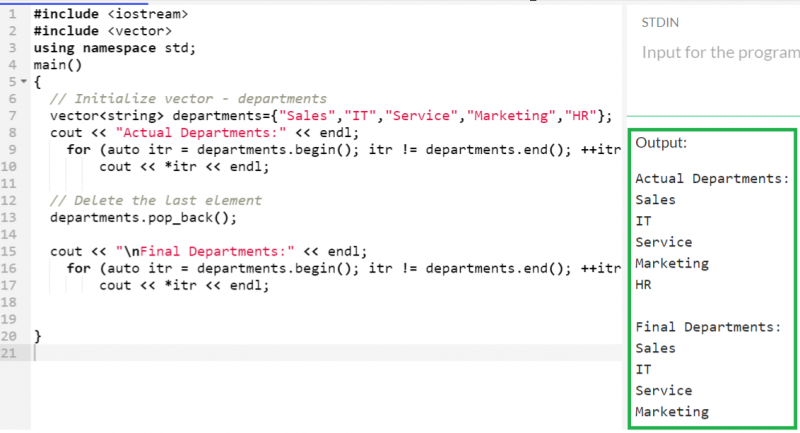
벡터에 있는 마지막 항목을 삭제하려면 벡터::pop_back() 기능이 가장 좋은 접근 방식입니다. 벡터에 있는 마지막 요소를 삭제합니다.
통사론:
벡터. 팝백 ( )이 기능에는 매개변수가 필요하지 않습니다. 빈 벡터에서 마지막 요소를 삭제하려고 하면 정의되지 않은 동작이 표시됩니다.
5개의 문자열이 포함된 'departments'라는 빈 벡터를 만들고 이전 함수를 사용하여 마지막 요소를 삭제해 보겠습니다. 두 경우 모두 벡터를 표시합니다.
#include#include <벡터>
사용하여 네임스페이스 성병 ;
기본 ( )
{
// 벡터 초기화 - 부서
벡터 < 끈 > 부서 = { '매상' , '그것' , '서비스' , '마케팅' , '인사' } ;
시합 << '실제 부서:' << 끝 ;
~을 위한 ( 자동 그것 = 부서. 시작하다 ( ) ; 그것 ! = 부서. 끝 ( ) ; ++ 그것 )
시합 << * 그것 << 끝 ;
// 마지막 요소 삭제
부서. 팝백 ( ) ;
시합 << ' \N 최종 부서:' << 끝 ;
~을 위한 ( 자동 그것 = 부서. 시작하다 ( ) ; 그것 ! = 부서. 끝 ( ) ; ++ 그것 )
시합 << * 그것 << 끝 ;
}
산출:
'HR'은 'departments' 벡터에 있는 마지막 요소입니다. 따라서 벡터에서 제거되고 최종 벡터에는 '판매', 'IT', '서비스' 및 '마케팅'이 포함됩니다.
벡터 교환
그만큼 벡터::스왑() C++ STL의 함수는 두 벡터에 존재하는 모든 요소를 교환하는 데 사용됩니다.
통사론:
첫 번째_벡터. 교환 ( 두 번째_벡터 )벡터의 크기는 고려하지 않지만 벡터는 동일한 유형이어야 합니다(벡터 유형이 다르면 오류가 발생합니다).
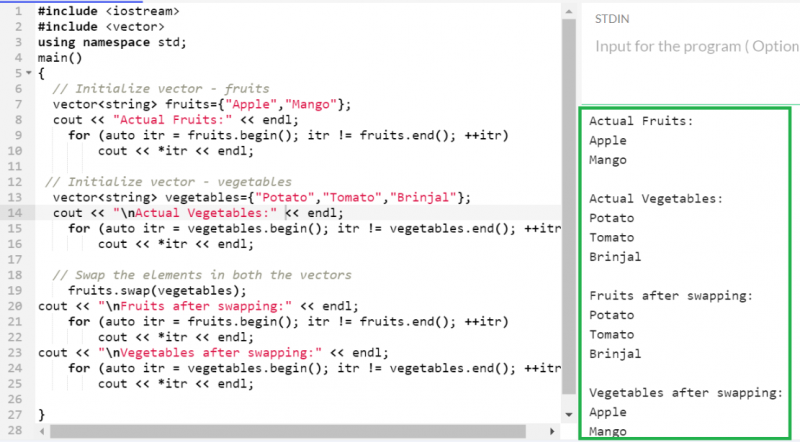
크기가 다른 문자열 유형의 두 벡터('과일'과 '야채')를 만들어 보겠습니다. 두 경우 모두 각각을 바꾸고 벡터를 표시합니다.
#include#include <벡터>
사용하여 네임스페이스 성병 ;
기본 ( )
{
// 벡터 초기화 - 과일
벡터 < 끈 > 과일 = { '사과' , '망고' } ;
시합 << '실제 과일:' << 끝 ;
~을 위한 ( 자동 그것 = 과일. 시작하다 ( ) ; 그것 ! = 과일. 끝 ( ) ; ++ 그것 )
시합 << * 그것 << 끝 ;
// 벡터 초기화 - 야채
벡터 < 끈 > 채소 = { '감자' , '토마토' , '브린잘' } ;
시합 << ' \N 실제 야채:' << 끝 ;
~을 위한 ( 자동 그것 = 채소. 시작하다 ( ) ; 그것 ! = 채소. 끝 ( ) ; ++ 그것 )
시합 << * 그것 << 끝 ;
// 두 벡터의 요소를 교환합니다.
과일. 교환 ( 채소 ) ;
시합 << ' \N 교환 후 과일:' << 끝 ;
~을 위한 ( 자동 그것 = 과일. 시작하다 ( ) ; 그것 ! = 과일. 끝 ( ) ; ++ 그것 )
시합 << * 그것 << 끝 ;
시합 << ' \N 교체 후 야채:' << 끝 ;
~을 위한 ( 자동 그것 = 채소. 시작하다 ( ) ; 그것 ! = 채소. 끝 ( ) ; ++ 그것 )
시합 << * 그것 << 끝 ;
}
산출:
이전에는 '과일' 벡터에 두 개의 요소가 있었고 '야채' 벡터에는 세 개의 요소가 있었습니다. 교체 후 '과일' 벡터는 세 개의 요소를 보유하고 '야채' 벡터는 두 개의 요소를 보유합니다.
벡터에서 첫 번째 요소를 가져옵니다.
어떤 경우에는 벡터의 첫 번째 요소만 반환해야 하는 경우도 있습니다. C++ STL의 vector::front() 함수는 벡터에서 첫 번째 요소만 가져옵니다.
통사론:
벡터. 앞쪽 ( )이 함수는 매개변수를 사용하지 않습니다. 벡터가 비어 있으면 오류가 발생합니다.
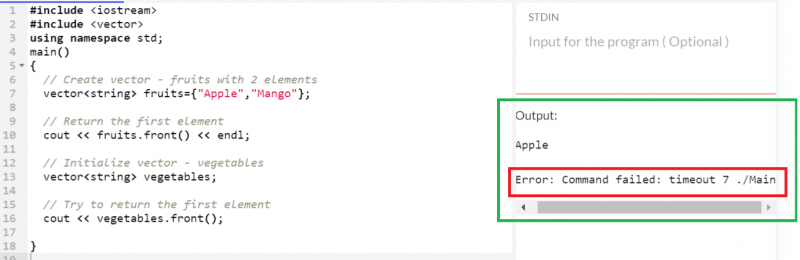
문자열 유형의 '과일'과 '야채'라는 두 개의 벡터를 만들고 두 벡터와 별도로 첫 번째 요소를 가져옵니다.
#include#include <벡터>
사용하여 네임스페이스 성병 ;
기본 ( )
{
// 벡터 생성 - 요소가 2개인 과일
벡터 < 끈 > 과일 = { '사과' , '망고' } ;
// 첫 번째 요소를 반환합니다.
시합 << 과일. 앞쪽 ( ) << 끝 ;
// 벡터 초기화 - 야채
벡터 < 끈 > 채소 ;
// 첫 번째 요소를 반환하려고 시도합니다.
시합 << 채소. 앞쪽 ( ) ;
}
산출:
'사과'는 '과일' 벡터에 존재하는 첫 번째 요소입니다. 따라서 반환됩니다. 그러나 'vegetables' 벡터가 비어 있기 때문에 첫 번째 요소를 가져오려고 하면 오류가 발생합니다.
벡터에서 마지막 요소를 가져옵니다.
C++ STL의 vector::end() 함수는 벡터에서 마지막 요소만 가져옵니다.
통사론:
벡터. 뒤쪽에 ( )이 함수는 매개변수를 사용하지 않습니다. 벡터가 비어 있으면 오류가 발생합니다.
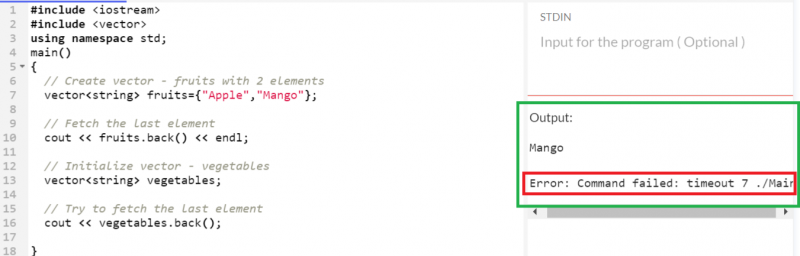
문자열 유형의 '과일'과 '야채'라는 두 개의 벡터를 만들고 두 벡터와 별도로 마지막 요소를 가져오도록 하겠습니다.
#include#include <벡터>
사용하여 네임스페이스 성병 ;
기본 ( )
{
// 벡터 생성 - 요소가 2개인 과일
벡터 < 끈 > 과일 = { '사과' , '망고' } ;
// 마지막 요소를 가져옵니다.
시합 << 과일. 뒤쪽에 ( ) << 끝 ;
// 벡터 초기화 - 야채
벡터 < 끈 > 채소 ;
// 마지막 요소를 가져오려고 시도합니다.
시합 << 채소. 뒤쪽에 ( ) ;
}
산출:
'망고'는 '과일' 벡터에 존재하는 마지막 요소입니다. 따라서 반환됩니다. 그러나 'vegetables' 벡터가 비어 있기 때문에 'vegetables' 벡터에서 마지막 요소를 가져오려고 하면 오류가 발생합니다.
벡터에 새 값 할당
일부 시나리오에서는 모든 값을 새 값으로 업데이트하거나 동일한 값으로 벡터를 생성하려는 경우 vector::ass() 함수를 사용하는 것이 가장 좋은 방법입니다. 이 기능을 사용하면 다음을 수행할 수 있습니다.
- 모든 유사한 요소로 벡터를 만듭니다.
- 동일한 요소로 기존 벡터를 수정합니다.
통사론:
벡터. 양수인 ( 크기, 가치 )이 기능에는 두 개의 매개변수가 필요합니다.
여기:
- 크기는 할당할 요소의 수를 지정합니다.
- 값은 할당할 요소를 지정합니다.
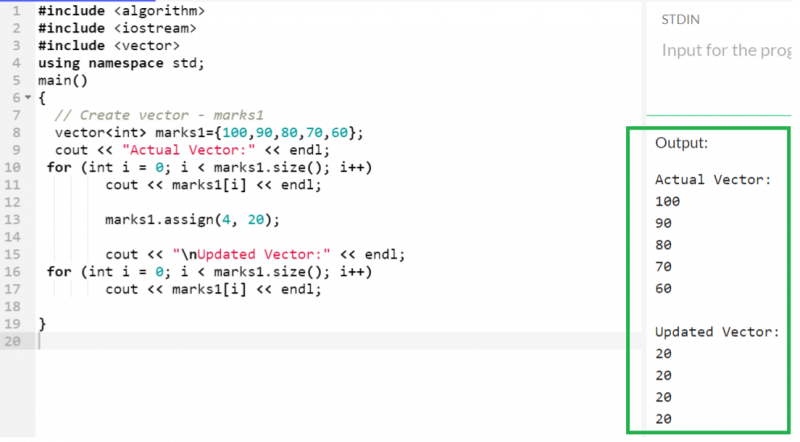
5개의 값을 가진 'marks1'이라는 벡터를 만들고 업데이트된 벡터의 모든 요소가 20이 되도록 이 벡터를 4개의 요소로 업데이트하겠습니다.
#include <알고리즘>#include
#include <벡터>
사용하여 네임스페이스 성병 ;
기본 ( )
{
// 벡터 생성 - mark1
벡터 < 정수 > 마크1 = { 100 , 90 , 80 , 70 , 60 } ;
시합 << '실제 벡터:' << 끝 ;
~을 위한 ( 정수 나 = 0 ; 나 < 마크1. 크기 ( ) ; 나 ++ )
시합 << 마크1 [ 나 ] << 끝 ;
마크1. 양수인 ( 4 , 이십 ) ;
시합 << ' \N 업데이트된 벡터:' << 끝 ;
~을 위한 ( 정수 나 = 0 ; 나 < 마크1. 크기 ( ) ; 나 ++ )
시합 << 마크1 [ 나 ] << 끝 ;
}
산출:
이전에는 벡터에 5개의 서로 다른 요소가 포함되었습니다. 이제 4개의 요소만 보유하고 있으며 모두 20과 같습니다.
Emplace()를 사용하여 벡터 확장
우리는 새 요소가 벡터의 어느 위치에나 동적으로 삽입된다는 것을 이미 알고 있습니다. vector::emplace() 함수를 사용하면 가능합니다. 이 함수에서 허용하는 구문과 매개변수를 빠르게 살펴보겠습니다.
통사론:
벡터. 위치 ( const_iterator 위치, 요소 )두 개의 필수 매개변수가 이 함수에 전달됩니다.
여기:
- 첫 번째 매개변수는 위치를 취하므로 어느 위치에나 요소를 삽입할 수 있습니다. Begin() 또는 end() 반복 함수를 사용하여 위치를 얻을 수 있습니다.
- 두 번째 매개변수는 벡터에 삽입할 요소입니다.
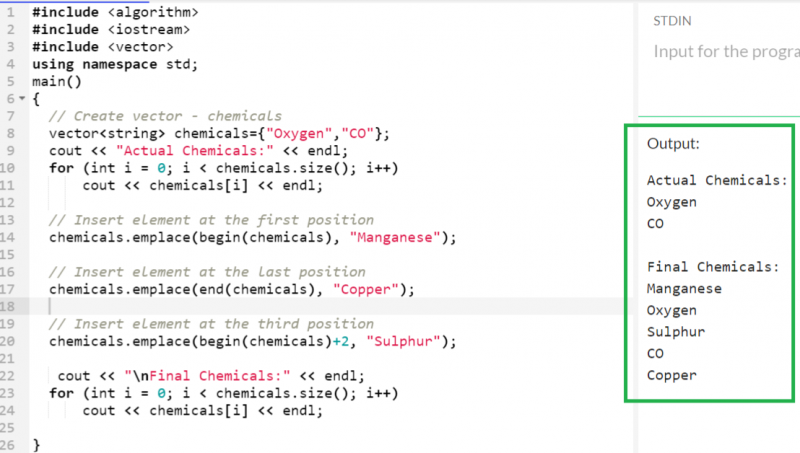
두 가지 요소가 있는 '화학물질' 벡터를 생각해 보세요.
- 첫 번째 위치에 “망간” 삽입 - 시작(화학물질)
- 마지막 위치(약품)에 'Copper'를 삽입합니다.
- 세 번째 위치에 'Sulphur' 삽입 - 시작(화학물질)+2
#include
#include <벡터>
사용하여 네임스페이스 성병 ;
기본 ( )
{
// 벡터 생성 - 화학물질
벡터 < 끈 > 화학 = { '산소' , '코' } ;
시합 << '실제 화학물질:' << 끝 ;
~을 위한 ( 정수 나 = 0 ; 나 < 화학. 크기 ( ) ; 나 ++ )
시합 << 화학 [ 나 ] << 끝 ;
// 첫 번째 위치에 요소 삽입
화학. 위치 ( 시작하다 ( 화학 ) , '망간' ) ;
// 마지막 위치에 요소 삽입
화학. 위치 ( 끝 ( 화학 ) , '구리' ) ;
// 세 번째 위치에 요소 삽입
화학. 위치 ( 시작하다 ( 화학 ) + 2 , '황' ) ;
시합 << ' \N 최종 화학물질:' << 끝 ;
~을 위한 ( 정수 나 = 0 ; 나 < 화학. 크기 ( ) ; 나 ++ )
시합 << 화학 [ 나 ] << 끝 ;
}
산출:
이제 최종 벡터에는 5개의 요소가 포함됩니다(다음 스크린샷 참조).
Emplace_Back()을 사용하여 벡터 확장
다음을 사용하여 요소를 추가할 수 있습니다(벡터 끝에 추가). 벡터::emplace_back() 기능.
통사론:
벡터. emplace_back ( 요소 )벡터에 추가할 요소를 매개변수로 필수로 전달해야 합니다.
emplace_back() 함수를 사용하여 두 요소를 차례로 추가해 보겠습니다.
#include <알고리즘>#include
#include <벡터>
사용하여 네임스페이스 성병 ;
기본 ( )
{
// 벡터 생성 - 화학물질
벡터 < 끈 > 화학 = { '산소' , '코' } ;
시합 << '실제 화학물질:' << 끝 ;
~을 위한 ( 정수 나 = 0 ; 나 < 화학. 크기 ( ) ; 나 ++ )
시합 << 화학 [ 나 ] << 끝 ;
// 벡터 끝에 망간을 삽입합니다.
화학. emplace_back ( '망간' ) ;
// 벡터 끝에 망간을 삽입합니다.
화학. emplace_back ( '구리' ) ;
시합 << ' \N 최종 화학물질:' << 끝 ;
~을 위한 ( 정수 나 = 0 ; 나 < 화학. 크기 ( ) ; 나 ++ )
시합 << 화학 [ 나 ] << 끝 ;
}
산출:
이제 최종 벡터에는 '망간'과 '구리'를 추가한 후 4개의 요소가 포함됩니다.

벡터의 최대 요소
- 일부 요소로 벡터를 만듭니다.
- 벡터에 존재하는 최대 요소를 찾으려면 두 개의 반복자를 인수로 받아들이는 *max_element() 함수를 사용하십시오. 이 두 매개변수는 범위 역할을 하며, 제공된 범위 내에서 최대 요소가 반환됩니다. 시작 위치는 Begin()이고 마지막 위치는 end()입니다.
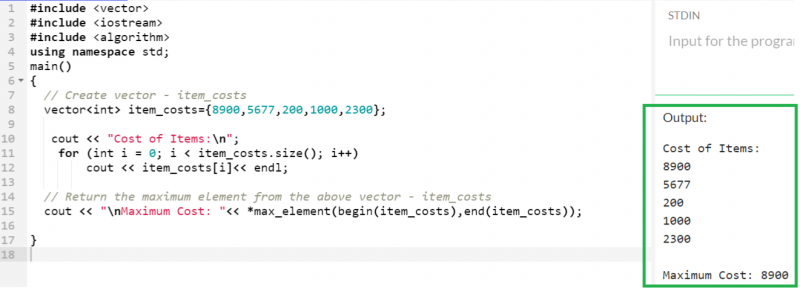
5개의 정수 유형 값을 보유하고 최대 요소를 반환하는 'item_costs'라는 벡터를 고려해 보겠습니다.
#include <벡터>#include
#include <알고리즘>
사용하여 네임스페이스 성병 ;
기본 ( )
{
// 벡터 생성 - item_costs
벡터 < 정수 > 품목_비용 = { 8900 , 5677 , 200 , 1000 , 2300 } ;
시합 << '아이템 비용: \N ' ;
~을 위한 ( 정수 나 = 0 ; 나 < item_costs. 크기 ( ) ; 나 ++ )
시합 << 품목_비용 [ 나 ] << 끝 ;
// 위 벡터에서 최대 요소를 반환합니다 - item_costs
시합 << ' \N 최대 비용: ' << * 최대_요소 ( 시작하다 ( 품목_비용 ) ,끝 ( 품목_비용 ) ) ;
}
산출:
여기서 8900은 'item_costs' 벡터에 존재하는 모든 요소 중 최대 요소입니다.
벡터의 최소 요소
- 일부 요소로 벡터를 만듭니다.
- 벡터에 존재하는 최소 요소를 찾으려면 두 개의 반복자를 인수로 받아들이는 *min_element() 함수를 사용하십시오. 이 두 매개변수는 범위 역할을 하며 제공된 범위 내에서 최소 요소(다른 모든 요소보다 작은)가 반환됩니다. 시작 위치는 Begin()이고 마지막 위치는 end()입니다.
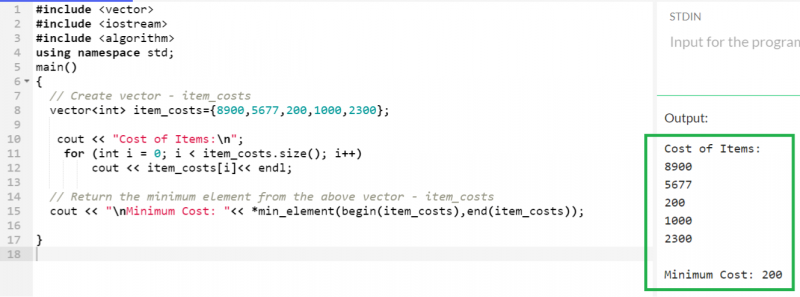
최대 요소를 찾기 위해 생성된 벡터와 동일한 벡터를 활용하고 *min_element() 함수를 사용하여 최소 요소를 찾습니다.
#include <벡터>#include
#include <알고리즘>
사용하여 네임스페이스 성병 ;
기본 ( )
{
// 벡터 생성 - item_costs
벡터 < 정수 > 품목_비용 = { 8900 , 5677 , 200 , 1000 , 2300 } ;
시합 << '아이템 비용: \N ' ;
~을 위한 ( 정수 나 = 0 ; 나 < item_costs. 크기 ( ) ; 나 ++ )
시합 << 품목_비용 [ 나 ] << 끝 ;
// 위 벡터에서 최소 요소를 반환합니다 - item_costs
시합 << ' \N 최소 비용: ' << * min_element ( 시작하다 ( 품목_비용 ) ,끝 ( 품목_비용 ) ) ;
}
산출:
여기서 200은 'item_costs' 벡터에 존재하는 모든 요소 중 최소 요소입니다.
벡터 요소의 합
벡터에 존재하는 모든 요소의 합을 반환하려면 축적하다() C++ STL의 함수가 사용됩니다. 세 가지 매개변수를 허용합니다. 첫 번째 매개변수는 범위의 시작 요소를 나타내는 첫 번째 인덱스(begin() 반복자 지정)를 취하고 두 번째 매개변수는 범위의 끝 요소(end() 반복자 지정)를 나타내는 마지막 인덱스를 가져옵니다. 마지막으로 합계의 초기 값(이 경우 0)을 전달해야 합니다.
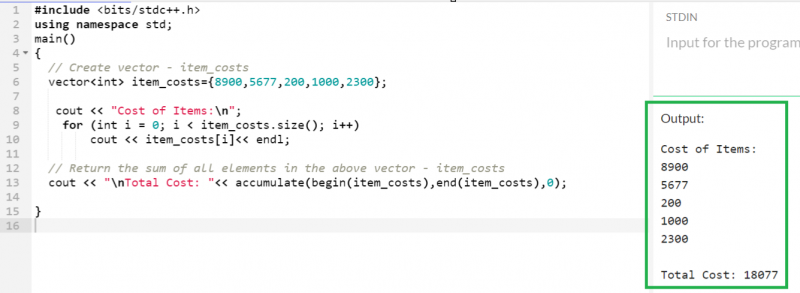
축적하다 ( first_index, last_index, 초기_값 ) ;5개의 정수형 요소로 'item_costs'라는 벡터를 만들고 합계를 계산합니다.
#include사용하여 네임스페이스 성병 ;
기본 ( )
{
// 벡터 생성 - item_costs
벡터 < 정수 > 품목_비용 = { 8900 , 5677 , 200 , 1000 , 2300 } ;
시합 << '아이템 비용: \N ' ;
~을 위한 ( 정수 나 = 0 ; 나 < item_costs. 크기 ( ) ; 나 ++ )
시합 << 품목_비용 [ 나 ] << 끝 ;
// 위 벡터의 모든 요소의 합계를 반환합니다 - item_costs
시합 << ' \N 총 비용: ' << 축적하다 ( 시작하다 ( 품목_비용 ) ,끝 ( 품목_비용 ) , 0 ) ;
}
산출:
8900, 5677, 200, 1000, 2300의 합은 18077입니다.
두 벡터의 요소별 곱셈
- 숫자 유형으로 두 개의 벡터를 생성하고 두 벡터는 크기가 동일해야 합니다(첫 번째 벡터에 있는 총 요소 수 = 두 번째 벡터에 있는 총 요소 수).
- 새로운 벡터를 선언하고 for 루프 , 각 반복에서 두 요소에 대해 곱셈 연산을 수행하고 push_back() 함수를 사용하여 생성된 벡터에 값을 저장합니다. ~을 위한 ( 정수 그것 = 0 ; 나 < first_vec. 크기 ( ) ; 그것 ++ )
- 결과 벡터를 반복하여 결과 벡터에 존재하는 요소를 표시합니다.
{
결과_벡터. push_back ( first_vec [ 그것 ] * 초_것 [ 그것 ] ) ;
}
5개의 정수형 요소로 'item_costs'라는 벡터를 만들고 합계를 계산합니다.
#include사용하여 네임스페이스 성병 ;
기본 ( )
{
// 각각 5개의 요소가 있는 두 개의 벡터(product1 및 products2)를 만듭니다.
벡터 < 정수 > 제품1 = { 10 , 이십 , 30 , 40 , 오십 } ;
벡터 < 정수 > 제품2 = { 오십 , 40 , 30 , 70 , 60 } ;
벡터 < 정수 > 결과_제품 ;
// 요소별 곱셈을 수행합니다.
~을 위한 ( 정수 나 = 0 ; 나 < 제품1. 크기 ( ) ; 나 ++ ) {
결과_제품. push_back ( 제품1 [ 나 ] * 제품2 [ 나 ] ) ;
}
// 결과 벡터를 표시합니다.
시합 << '벡터 곱셈: \N ' ;
~을 위한 ( 정수 입술 : 결과_제품 )
시합 << 입술 << 끝 ;
}
산출:
반복 - 1 : 10 * 오십 => 500반복 - 2 : 이십 * 40 => 800
반복 - 삼 : 30 * 30 => 900
반복 - 4 : 40 * 70 => 2800
반복 - 5 : 오십 * 60 => 3000

두 벡터의 내적
C++ 벡터의 경우 내적은 '두 벡터 시퀀스의 해당 항목의 곱의 합'으로 정의됩니다.
통사론:
내부 제품 ( 벡터1 먼저, 벡터1 마지막, 벡터2 먼저, 초기값 )내적을 반환하려면 inner_product() 함수를 사용하세요. 이 함수는 4개의 필수 매개변수를 사용합니다.
여기:
- 첫 번째 매개변수는 첫 번째 벡터의 시작을 가리키는 반복자를 나타냅니다(begin() 함수를 사용하여 지정).
- 두 번째 매개변수는 첫 번째 벡터의 끝을 가리키는 반복자를 나타냅니다(end() 함수를 사용하여 지정).
- 세 번째 매개변수는 두 번째 벡터의 시작 부분을 가리키는 반복자를 나타냅니다(begin() 함수를 사용하여 지정).
- 초기값은 내적 누적을 위한 정수인 마지막 매개변수로 전달되어야 합니다.
두 벡터의 곱셈을 위해 생성된 동일한 프로그램을 활용하고 innsr_product() 함수를 사용하여 두 벡터의 내적을 찾습니다.
#include사용하여 네임스페이스 성병 ;
기본 ( )
{
// 각각 5개의 요소가 있는 두 개의 벡터(product1 및 products2)를 만듭니다.
벡터 < 정수 > 제품1 = { 10 , 이십 , 30 , 40 , 오십 } ;
벡터 < 정수 > 제품2 = { 오십 , 40 , 30 , 70 , 60 } ;
// 결과 벡터를 표시합니다.
시합 << '제품1과 제품2의 내적: ' ;
시합 << 내부 제품 ( 시작하다 ( 제품1 ) ,끝 ( 제품1 ) ,시작하다 ( 제품2 ) , 0 ) ;
}
산출:
( 10 * 오십 ) + ( 이십 * 40 ) + ( 30 * 30 ) + ( 40 * 70 ) + ( 오십 * 60 )=> 500 + 800 + 900 + 2800 + 3000
=> 8000

세트를 벡터로 변환
집합에서 발생한 모든 요소를 벡터로 전달하여 집합을 벡터로 변환하는 방법에는 여러 가지가 있습니다. 가장 좋고 간단한 방법은 std::copy() 함수를 사용하는 것입니다.
통사론
성병 :: 복사 ( sourceIterator 먼저, sourceIterator 마지막, DestinationIterator 먼저 )사용 표준::복사() 집합의 요소를 벡터에 삽입하는 함수입니다. 세 가지 매개변수를 사용합니다.
여기:
- 첫 번째 매개변수는 반복기의 첫 번째 요소를 가리키는 소스 반복기를 나타냅니다. 여기서 set은 Begin() 함수를 사용하여 지정된 소스 반복자입니다.
- 마찬가지로 두 번째 매개변수는 마지막 요소(end() 함수)를 가리킵니다.
- 세 번째 매개변수는 반복기의 첫 번째 요소(begin() 함수를 사용하여 지정됨)를 가리키는 대상 반복기를 나타냅니다.
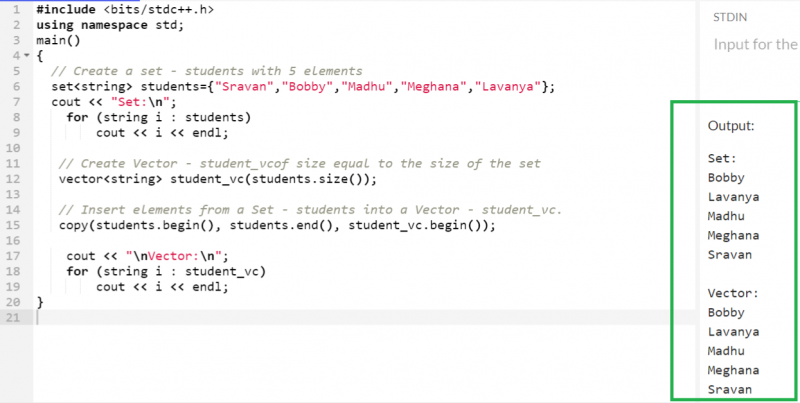
5명의 학생으로 구성된 세트를 만들고 이전 함수를 사용하여 모든 요소를 벡터에 복사해 보겠습니다.
#include사용하여 네임스페이스 성병 ;
기본 ( )
{
// 세트 만들기 - 5개 요소를 가진 학생
세트 < 끈 > 재학생 = { '스라반' , '순경' , '마두' , '메가나' , '라반야' } ;
시합 << '세트: \N ' ;
~을 위한 ( 문자열 i : 재학생 )
시합 << 나 << 끝 ;
// 벡터 생성 - Student_vcof 크기는 집합의 크기와 같습니다.
벡터 < 끈 > Student_vc ( 재학생. 크기 ( ) ) ;
// Set(학생)의 요소를 Vector(학생_vc)에 삽입합니다.
복사 ( 재학생. 시작하다 ( ) , 학생. 끝 ( ) , 학생_vc. 시작하다 ( ) ) ;
시합 << ' \N 벡터: \N ' ;
~을 위한 ( 문자열 i : Student_vc )
시합 << 나 << 끝 ;
}
산출:
이제 'Students' 세트에 있는 모든 요소가 'students_vc' 벡터에 복사됩니다.
중복 요소 제거
- 먼저, 모든 중복 요소가 서로 인접하도록 벡터의 요소를 정렬해야 합니다. 표준::정렬() 기능. 성병 :: 종류 ( 벡터가 먼저, 벡터가 마지막에 ) ;
- 중복 요소가 선택되도록 std::unique() 함수를 사용하십시오. 동시에, erasure() 함수를 사용하여 std::unique() 함수에서 반환된 중복 항목을 제거합니다. 최종 벡터에서는 요소의 순서가 변경될 수 있습니다. 벡터. 삭제 ( 성병 :: 고유한 ( 벡터가 먼저, 벡터가 마지막에 ) , 벡터 마지막 ) )
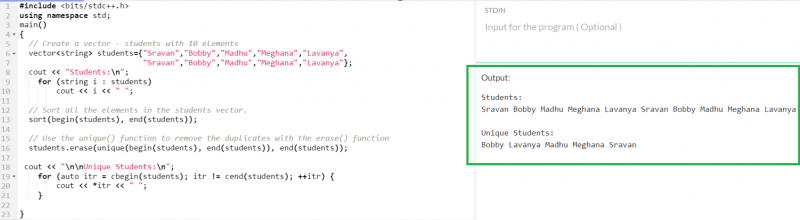
10개의 요소로 'students' 벡터를 만들고 중복된 요소를 제거하여 벡터를 반환합니다.
#include사용하여 네임스페이스 성병 ;
기본 ( )
{
// 벡터 생성 - 10개의 요소를 가진 학생
벡터 < 끈 > 재학생 = { '스라반' , '순경' , '마두' , '메가나' , '라반야' ,
'스라반' , '순경' , '마두' , '메가나' , '라반야' } ;
시합 << '재학생: \N ' ;
~을 위한 ( 문자열 i : 재학생 )
시합 << 나 << ' ' ;
// 학생 벡터의 모든 요소를 정렬합니다.
종류 ( 시작하다 ( 재학생 ) , 끝 ( 재학생 ) ) ;
//unique() 함수를 사용하여 erasure() 함수로 중복된 항목을 제거합니다.
재학생. 삭제 ( 고유한 ( 시작하다 ( 재학생 ) , 끝 ( 재학생 ) ) , 끝 ( 재학생 ) ) ;
시합 << ' \N \N 독특한 학생: \N ' ;
~을 위한 ( 자동 그것 = cbegin ( 재학생 ) ; 그것 ! = 몇 가지 ( 재학생 ) ; ++ 그것 ) {
시합 << * 그것 << ' ' ;
}
}
산출:
이제 모든 요소는 벡터에서 고유합니다.
벡터를 집합으로 변환
세트는 중복 요소를 허용하지 않습니다. 중복된 집합에 벡터를 삽입하려고 입력하는 경우 해당 벡터는 무시됩니다. 집합을 벡터로 변환하는 이전 시나리오에서 사용된 것과 동일한 std::copy() 함수를 사용합니다.
이 시나리오에서는:
- 첫 번째 매개변수는 벡터를 start() 함수를 사용하여 지정된 소스 반복자로 사용합니다.
- 두 번째 매개변수는 end() 함수를 사용하여 지정된 소스 반복자로 벡터를 사용합니다.
- 집합의 끝을 가리키는 집합과 반복자를 매개 변수로 제공하여 집합의 특정 위치에 요소를 자동으로 덮어쓰거나 복사하는 데 사용되는 std::inserter() 함수를 전달합니다.
10개의 정수로 벡터를 만들고 요소를 세트에 복사해 보겠습니다.
#include사용하여 네임스페이스 성병 ;
기본 ( )
{
// 세트 생성 - 10개의 값으로 표시
벡터 < 정수 > 점수 = { 12 , 3. 4 , 56 , 78 , 65 , 78 , 90 , 90 , 78 , 3. 4 } ;
시합 << '벡터: \N ' ;
~을 위한 ( 정수 나 : 점수 )
시합 << 나 << ' ' ;
// 세트 생성 - 벡터 크기와 동일한 크기의 mark_set
세트 < 정수 > 마크 세트 ;
// Set(학생)의 요소를 Vector(학생_vc)에 삽입합니다.
복사 ( 시작하다 ( 점수 ) ,끝 ( 점수 ) , 삽입기 ( mark_set,끝 ( 마크 세트 ) ) ) ;
시합 << ' \N \N 세트: \N ' ;
~을 위한 ( 정수 나 : 마크 세트 )
시합 << 나 << ' ' ;
}
산출:
'marks'라는 기존 벡터에는 10개의 값이 있습니다. 'marks_set' 세트에 복사한 후에는 다른 4개의 요소가 중복되므로 6개의 요소만 보유합니다.

빈 문자열 제거
벡터에 있는 빈 문자열은 사용되지 않습니다. 벡터에 있는 빈 문자열을 제거하는 것이 좋습니다. C++ 벡터에서 빈 문자열을 제거하는 방법을 살펴보겠습니다.
- 'for' 루프를 사용하여 벡터를 반복합니다.
- 각 반복에서 요소가 비어 있는지('') 또는 at() 멤버 함수와 함께 '==' 연산자를 사용하지 않는지 확인하세요.
- std::erase() 함수를 사용하여 이전 조건을 확인한 후 빈 문자열을 제거합니다.
- 벡터가 끝날 때까지 2단계와 3단계를 반복합니다.
10개의 문자열로 '회사' 벡터를 만들어 보겠습니다. 그중 5개는 비어 있으며 이전 접근 방식을 구현하여 제거합니다.
#include#include <벡터>
사용하여 네임스페이스 성병 ;
기본 ( ) {
벡터 < 끈 > 회사 { 'A사' , '' , 'B사' ,
'' , 'C사' , '' , 'D사' , '' , '' , '' } ;
// 회사 반복
// erasure()를 사용하여 빈 요소를 제거합니다.
~을 위한 ( 정수 그것 = 1 ; 그것 < 회사. 크기 ( ) ; ++ 그것 ) {
만약에 ( 회사. ~에 ( 그것 ) == '' ) {
회사. 삭제 ( 회사. 시작하다 ( ) + 그것 ) ;
-- 그것 ;
}
}
// 벡터 표시
~을 위한 ( 자동 & 나 : 회사 ) {
시합 << 나 << 끝 ;
}
}
산출:
이제 '회사' 벡터는 비어 있지 않은 문자열을 보유합니다.

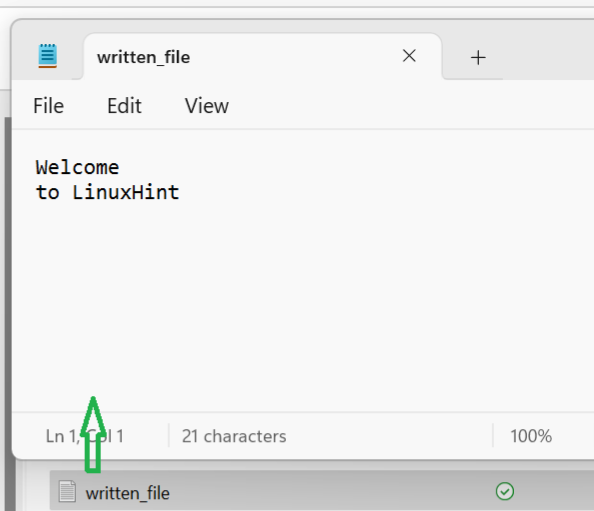
텍스트 파일에 벡터 쓰기
벡터 인덱스를 사용하여 벡터에 존재하는 모든 요소를 파일에 쓰는 방법을 논의해 보겠습니다. fstream .
- 벡터를 초기화한 후 push_back 함수를 사용하여 일부 요소를 여기에 밀어 넣습니다.
- 모드를 out으로 설정하여 'fstream' 라이브러리의 open() 함수를 사용하세요.
- 'for' 루프의 인덱스를 사용하여 벡터에 있는 각 요소를 탐색하고 각 요소를 제공된 파일에 씁니다.
- 마지막으로 파일을 닫습니다.
C++ 코드를 실행하여 이전 접근 방식을 구현해 보겠습니다.
#include <벡터>#include <문자열>
#include
#include
사용하여 네임스페이스 성병 ;
기본 ( )
{
// 벡터 생성 - v_data
// 두 개의 요소를 거기에 밀어 넣습니다.
벡터 < 끈 > v_data ;
v_data. push_back ( '환영' ) ;
v_data. push_back ( 'LinuxHint로' ) ;
스트림 f ;
// 파일 열기
에프. 열려 있는 ( 'write_file.txt' ,ios_base :: 밖으로 ) ;
// 벡터의 각 요소를 반복하고 파일에 하나씩 씁니다.
~을 위한 ( 정수 나 = 0 ; 나 < v_data. 크기 ( ) ; 나 ++ )
{
에프 << v_data [ 나 ] << 끝 ;
}
// 파일을 닫습니다.
에프. 닫다 ( ) ;
}
산출:
'v_data' 벡터에는 두 개의 요소가 포함되어 있으며 벡터에 있는 요소로 프로그램이 실행되는 경로에 파일이 생성됩니다.
텍스트 파일에서 벡터 만들기
벡터에 있는 요소를 텍스트 파일에 쓰는 방법을 배웠습니다. 여기서는 텍스트 파일에 있는 콘텐츠에서 벡터를 만들어 보겠습니다.
- “를 생성하세요 ifstream” 파일에서 벡터를 생성하는 텍스트 파일의 정보를 읽는 데 사용되는 변수입니다.
- 파일 내용을 저장하기 위해 빈 벡터를 만들고, 파일의 끝을 확인하기 위한 플래그로 빈 문자열 변수를 사용합니다.
- 끝에 도달할 때까지 파일에서 다음 줄을 읽습니다(기본적으로 'while' 루프를 사용함). push_back() 함수를 사용하여 다음 줄을 읽고 이를 벡터에 밀어 넣습니다.
- 콘솔에서 벡터에 존재하는 요소를 보려면 선에 존재하는 선을 별도로 표시하십시오.
C++ 코드를 실행하여 이전 접근 방식을 구현해 보겠습니다. 다음 내용이 포함된 'data.txt' 파일을 고려해 보겠습니다. 여기서 벡터의 이름은 'v_data'입니다.
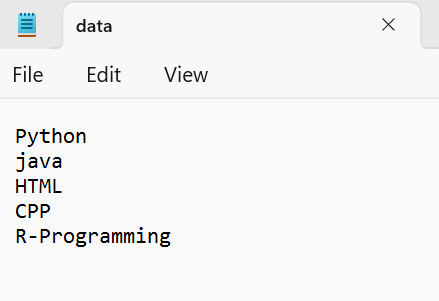
사용하여 네임스페이스 성병 ;
기본 ( )
{
// 텍스트 파일 열기 - 데이터
ifstream 파일 ( '데이터.txt' ) ;
// 벡터 생성 - v_data 유형 - 문자열
벡터 < 끈 > v_data ;
끈 팬티는 ;
// data.txt에서 다음 줄을 읽습니다.
//끝날때까지.
~하는 동안 ( 파일 >> ~였다 ) {
// 다음 줄을 읽고 v_data에 푸시합니다.
v_data. push_back ( ~였다 ) ;
}
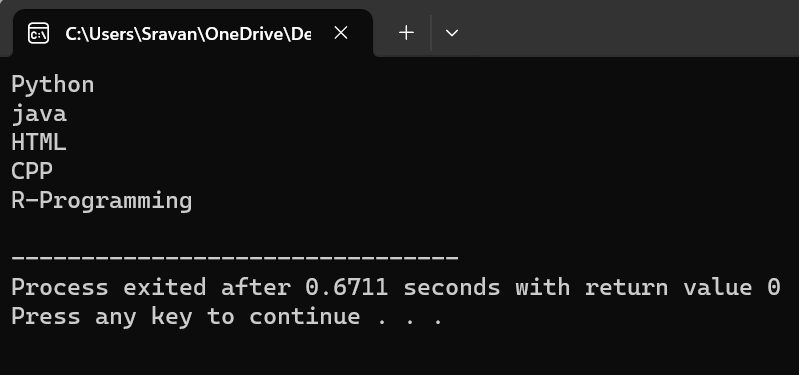
// 라인에 존재하는 라인을 별도로 표시합니다.
복사 ( v_data. 시작하다 ( ) , v_data. 끝 ( ) , ostream_iterator < 끈 > ( 시합 , ' \N ' ) ) ;
}
산출:
'v_data'에는 파일에서 가져온 5개의 요소가 포함되어 있음을 알 수 있습니다.
결론
이 긴 기사에서 우리는 C++ 프로그래밍 언어의 벡터와 관련된 실시간 애플리케이션에 사용되는 가능한 모든 예를 살펴보았습니다. 각 예는 구문, 매개변수 및 출력 예를 통해 설명됩니다. 코드를 명확하게 이해할 수 있도록 각 코드에 주석을 추가했습니다.