Ubuntu 20.04의 AWK NF:
'NF' AWK 변수는 제공된 파일의 모든 행에 있는 필드 수를 인쇄하는 데 사용됩니다. 이 내장 변수는 파일의 모든 줄을 하나씩 반복하고 각 줄에 대해 개별적으로 필드 수를 인쇄합니다. 이 기능을 제대로 이해하려면 아래에 설명된 예제를 읽어야 합니다.
Ubuntu 20.04에서 AWK NF 사용 시연의 예:
다음 네 가지 예제는 매우 이해하기 쉬운 방식으로 AWK NF의 사용법을 가르치는 방식으로 설계되었습니다. 이러한 모든 예제는 Ubuntu 20.04 운영 체제를 사용하여 구현되었습니다.
예 # 1: 텍스트 파일의 각 줄에서 필드 수를 인쇄합니다.
이 예에서는 Ubuntu 20.04에서 텍스트 파일의 각 줄이나 행 또는 레코드의 필드 또는 열 수를 인쇄하려고 했습니다. 그렇게 하는 방법을 보여주기 위해 아래 이미지에 표시된 텍스트 파일을 만들었습니다. 이 텍스트 파일에는 파키스탄의 5개 도시에서 킬로그램당 사과 비율이 포함되어 있습니다.

이 샘플 텍스트 파일을 만든 후 다음 명령을 실행하여 터미널에서 이 텍스트 파일의 각 줄에서 필드 수를 인쇄했습니다.
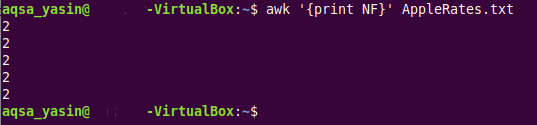
$ 으악 ' { 인쇄 NF } ' AppleRates.txt
이 명령에는 AWK 명령을 실행하고 있음을 나타내는 'awk' 키워드와 대상 텍스트 파일의 각 줄을 반복하고 각각에 대해 개별적으로 필드 수를 인쇄하는 'print NF' 문이 있습니다. 텍스트 파일의 줄. 마지막으로 해당 텍스트 파일의 이름(필드를 계산해야 함)이 있으며 이 경우 'AppleRatest.txt'입니다.

텍스트 파일의 다섯 줄 모두에 대해 정확히 동일한 수의 필드(즉, 2)가 있으므로 이 명령을 실행하면 모든 텍스트 파일 줄에 대한 필드 수와 동일한 숫자가 인쇄됩니다. 이는 아래 이미지에서 확인할 수 있습니다.
예 # 2: 표현 가능한 방식으로 텍스트 파일의 각 줄에서 필드 수를 인쇄합니다.
위에서 설명한 예제에 표시되는 출력은 텍스트 파일의 각 줄에 대한 줄 번호와 필드 수를 표시하여 멋지게 나타낼 수도 있습니다. 또한 선택한 특수 문자를 사용하여 행 번호를 필드 수와 구분할 수도 있습니다. 이를 보여주기 위해 첫 번째 예제에서 사용한 것과 동일한 텍스트 파일을 사용할 것입니다. 그러나 이 경우에 실행될 명령은 약간 다를 것이며 다음과 같습니다.
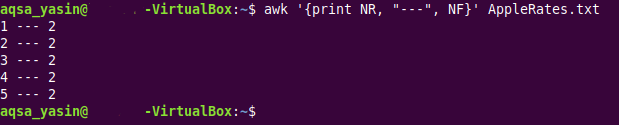
$ 으악 ' { 인쇄 NR, '---', NF } ' AppleRates.txt이 명령에서는 대상 텍스트 파일의 모든 행의 행 번호를 단순히 인쇄하는 내장 AWK 변수 'NR'을 도입했습니다. 또한 제공된 텍스트 파일의 필드 수와 줄 번호를 구분하기 위해 특수 문자로 세 개의 대시(“—”)를 사용했습니다.

동일한 텍스트 파일의 이 약간 수정된 출력은 아래 이미지에 표시됩니다.
예 # 3: 텍스트 파일의 각 줄에서 첫 번째 및 마지막 필드 인쇄:
제공된 텍스트 파일의 모든 행의 필드 수를 세는 것 외에도 AWK의 'NF' 특수 변수를 사용하여 제공된 텍스트 파일에서 마지막 필드의 실제 값을 추출할 수도 있습니다. 이번에도 처음 두 예제에 사용한 것과 동일한 텍스트 파일을 사용했습니다. 그러나 이 예제에서는 텍스트 파일의 첫 번째 필드와 마지막 필드의 실제 값을 인쇄하려고 합니다. 이를 위해 다음 명령을 실행했습니다.
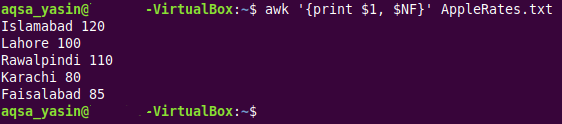
$ 으악 ' { 인쇄 $1 , $NF } ' AppleRates.txt이 명령에서 'awk' 키워드 뒤에는 'print $1, $NF' 문이 옵니다. '$1' 특수 변수는 제공된 텍스트 파일의 첫 번째 필드 또는 첫 번째 열의 값을 인쇄하는 데 사용되었으며 '$NF' AWK 변수는 마지막 필드 또는 마지막 열의 값을 인쇄하는 데 사용되었습니다. 대상 텍스트 파일의. 여기에서 'NF' AWK 변수를 그대로 사용할 때 각 줄의 필드 수를 계산하는 데 사용된다는 점에 유의해야 합니다. 그러나 달러 '$' 기호와 함께 사용하면 제공된 텍스트 파일의 마지막 필드에서 실제 값을 추출합니다. 명령의 나머지 부분은 처음 두 예제에 사용된 명령과 거의 동일합니다.

아래 표시된 출력에서 제공된 텍스트 파일의 첫 번째 필드와 마지막 필드의 실제 값이 터미널에 인쇄된 것을 볼 수 있습니다. 제공된 텍스트 파일에 두 개의 필드만 있기 때문에 이 출력이 'cat' 명령의 출력과 매우 유사하다는 것을 알 수 있습니다. 따라서 위에서 언급한 명령을 실행한 결과 전체 텍스트 파일의 내용이 터미널에 인쇄되었습니다.
예 # 4: 텍스트 파일에서 필드가 누락된 레코드 분리:
때때로 특정 필드가 누락된 일부 레코드가 텍스트 파일에 있으며 이러한 레코드를 모든 측면에서 완전한 레코드와 분리하고자 할 수 있습니다. 이는 'NF' AWK 변수를 사용하여 수행할 수도 있습니다. 이를 위해 우리는 이름과 함께 세 가지 다른 시험에서 다섯 명의 다른 학생의 시험 점수를 포함하는 'ExamMarks.txt'라는 텍스트 파일을 만들었습니다. 그러나 세 번째 시험에서는 일부 학생들이 점수가 누락되어 결석했습니다. 이 텍스트 파일은 다음과 같습니다.

전체 필드가 있는 레코드에서 누락된 필드가 있는 레코드를 구별하기 위해 아래 표시된 명령을 실행합니다.
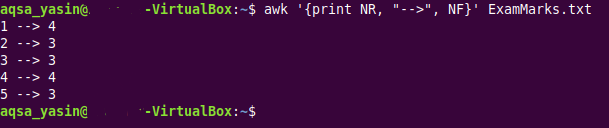
$ 으악 ' { 인쇄 NR, “--- > ', NF } ’ ExamMarks.txt 
이 명령은 두 번째 예에서 사용한 것과 동일합니다. 그러나 다음 이미지에 표시된 이 명령의 출력에서 첫 번째와 네 번째 레코드가 완전한 반면 두 번째, 세 번째 및 다섯 번째 레코드에는 누락된 필드가 있음을 알 수 있습니다.
결론:
이 기사의 목적은 'NF' AWK 특수 변수의 사용법을 설명하는 것이었습니다. 먼저 이 변수가 어떻게 작동하는지 간략하게 논의한 다음 네 가지 예를 통해 이 개념을 잘 설명했습니다. 공유된 모든 예제를 잘 이해하면 'NF' AWK 변수를 사용하여 총 필드 수를 세고 제공된 파일의 마지막 필드의 실제 값을 인쇄할 수 있습니다.