4장: 6502 마이크로프로세서 어셈블리 언어 튜토리얼
4.1 소개
6502 마이크로프로세서는 1975년에 출시되었습니다. 당시 Apple II, Commodore 64, BBC Micro 등 일부 개인용 컴퓨터의 마이크로프로세서로 사용되었습니다.
6502 마이크로프로세서는 오늘날에도 여전히 대량으로 생산되고 있습니다. 오늘날에는 더 이상 개인용 컴퓨터(노트북)에 사용되는 중앙처리장치가 아니지만, 오늘날에도 여전히 대량으로 생산되어 전자, 전기제품에 사용됩니다. 보다 현대적인 컴퓨터 아키텍처를 이해하려면 6502와 같이 오래되었지만 꽤 성공적인 마이크로프로세서를 검토하는 것이 매우 도움이 됩니다.
이해하고 프로그래밍하기가 간단하기 때문에 어셈블리 언어 교육에 사용할 수 있는 최고의(최고는 아닐지라도) 마이크로프로세서 중 하나입니다. 어셈블리 언어는 컴퓨터 프로그래밍에 사용할 수 있는 저수준 언어입니다. 한 마이크로프로세서의 어셈블리 언어는 다른 마이크로프로세서의 어셈블리 언어와 다릅니다. 이 장에서는 6502 마이크로프로세서 어셈블리 언어를 배웁니다. 보다 정확하게는 65C02를 학습하지만 간단히 6502라고 합니다.
과거에 유명한 컴퓨터는 commodore_64라고 불렸습니다. 6502는 6500 제품군의 마이크로프로세서입니다. commodore_64 컴퓨터는 6510 마이크로프로세서를 사용합니다. 6510 마이크로프로세서는 6500 µP입니다. 6502 µP의 명령 세트는 6510 µP의 거의 모든 명령입니다. 이 장과 다음 장의 지식은 commodore_64 컴퓨터를 기반으로 합니다. 이 지식은 온라인 진로 과정의 이 부분에서 최신 컴퓨터 아키텍처와 최신 운영 체제를 설명하기 위한 기반으로 사용됩니다.
컴퓨터 아키텍처는 컴퓨터 마더보드의 구성 요소와 각 구성 요소, 특히 마이크로프로세서 내에서 데이터가 흐르는 방식, 구성 요소 간에 데이터가 흐르는 방식 및 데이터가 상호 작용하는 방식에 대한 설명을 나타냅니다. 데이터의 단수형은 데이텀(Datum)입니다. 컴퓨터의 컴퓨터 아키텍처를 연구하는 효과적인 방법은 마더보드의 어셈블리 언어를 연구하는 것입니다.
commodore_64 컴퓨터는 8비트 컴퓨터 워드의 컴퓨터라고 합니다. 이는 정보가 8비트 바이너리 코드 형태로 저장, 전송 및 조작된다는 것을 의미합니다.
Commodore 64 마더보드의 블록 다이어그램
Commodore 64 마더보드의 블록 다이어그램은 다음과 같습니다.
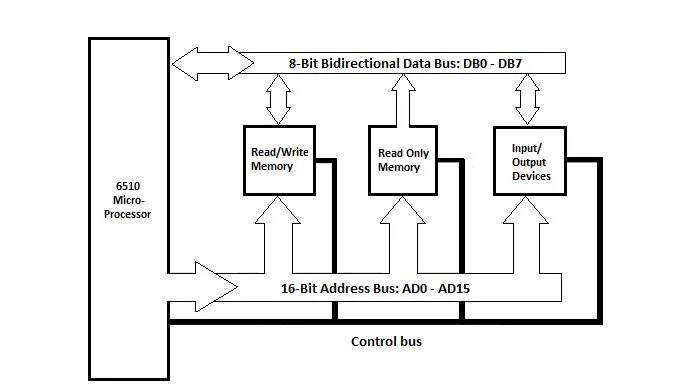
그림 4.1 Commodore_64 시스템 유닛의 블록 다이어그램
6510 마이크로프로세서를 6502 마이크로프로세서로 상상해 보십시오. 총 메모리는 일련의 바이트(바이트당 8비트)입니다. 바이트를 쓰거나 지울 수 있는 랜덤 액세스(읽기/쓰기) 메모리가 있습니다. 컴퓨터의 전원이 꺼지면 RAM(Random Access Memory)의 모든 정보가 삭제됩니다. ROM(읽기 전용 메모리)도 있습니다. 컴퓨터의 전원이 꺼지면 ROM의 정보는 그대로 유지됩니다(삭제되지 않음).
다이어그램에는 입출력 장치라고 불리는 입출력 포트(회로)가 있습니다. 이 포트를 컴퓨터 시스템 장치의 왼쪽과 오른쪽 또는 앞뒤 수직 표면에 보이는 포트와 혼동하지 마십시오. 그것은 두 가지 다른 것입니다. 이 내부 포트에서 하드 디스크(또는 플로피 디스크), 키보드 및 모니터와 같은 주변 장치까지의 연결은 다이어그램에 표시되지 않습니다.
다이어그램에는 세 개의 버스(매우 작은 전기 도체 그룹)가 있습니다. 각 와이어는 비트 1 또는 비트 0을 전송할 수 있습니다. 한 번에 8비트 바이트(1 클럭 펄스)를 RAM 및 입/출력 포트(입/출력 장치)로 전송하기 위한 데이터 버스는 양방향입니다. 데이터 버스의 폭은 8비트입니다.
모든 구성 요소는 주소 버스에 연결됩니다. 주소 버스는 마이크로프로세서에서 단방향입니다. 주소 버스에는 16개의 컨덕터가 있으며 각 컨덕터는 1비트(1 또는 0)를 전달합니다. 16비트가 하나의 클럭 펄스로 전송됩니다.
제어 버스가 있습니다. 제어 버스의 일부 전도체는 마이크로프로세서에서 다른 구성 요소로 각각 1비트를 전송합니다. 몇 개의 제어 라인은 입출력(IO) 포트에서 마이크로프로세서로 비트를 전달합니다.
컴퓨터 메모리
RAM과 ROM은 하나의 메모리 어셈블리로 간주됩니다. 이 어셈블리는 16진수에 '$' 접두사가 있는 다음과 같이 다이어그램으로 표시됩니다.
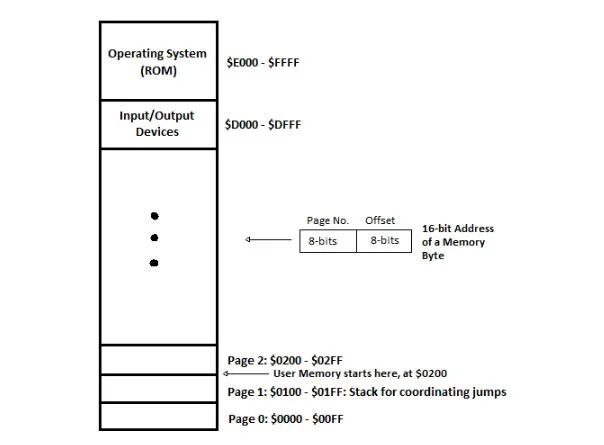
그림 4.11 Commodore 64 컴퓨터의 메모리 레이아웃
RAM은 0000부터입니다. 16 DFFF로 16 이는 $0000부터 $DFFF까지로 작성됩니다. 6502 µP 어셈블리 언어를 사용하면 16진수 앞에 '$'가 붙고 16, H 또는 16진수 접미사가 붙지 않습니다. RAM에 있는 모든 정보는 컴퓨터를 끄면 사라집니다. ROM은 $E000부터 $FFFF까지 시작됩니다. 컴퓨터가 꺼져도 꺼지지 않는 서브루틴이 있습니다. 이 서브루틴은 프로그래밍을 보조하는 일반적으로 사용되는 루틴입니다. 사용자 프로그램이 이를 호출합니다(다음 장 참조).
$0200부터 $D000까지의 공간(바이트)은 사용자 프로그램을 위한 공간입니다. $D000부터 $DFFF까지의 공간은 주변기기(입/출력 장치)와 직접 관련된 정보를 위한 공간입니다. 이것은 운영 체제의 일부입니다. 따라서 commodore-64 컴퓨터의 운영 체제는 두 가지 주요 부분으로 구성됩니다. 즉 절대 꺼지지 않는 ROM의 부분과 전원이 꺼질 때 꺼지는 $D000에서 $DFFF까지의 부분입니다. 이 IO(입력/출력) 데이터는 컴퓨터를 켤 때마다 디스크에서 로드되어야 합니다. 오늘날 이러한 데이터를 주변 장치 드라이버라고 합니다. 주변 장치는 마더보드의 연결을 통해 입/출력 장치 포트에서 시작하여 모니터, 키보드 등이 주변 장치 자체(모니터, 키보드 등)에 연결된 컴퓨터 수직 표면의 식별 가능한 포트까지 연결됩니다. .).
메모리는 2개로 구성됩니다. 16 = 65,536바이트 위치. 16진수 형식에서는 10000입니다. 16 = 10000 시간 = 10000 마녀 = $10000 위치. 컴퓨팅에서 2진수, 10진수, 16진수 등의 계산은 1이 아닌 0부터 시작합니다. 따라서 첫 번째 위치는 실제로 위치 번호 0000000000000000입니다. 2 = 0 10 = 0000 16 = $0000. 6502 µP 어셈블리 언어에서는 주소 위치 식별 앞에 $가 붙고 접미사나 아래 첨자가 없습니다. 마지막 위치는 위치번호 1111111111111111 입니다. 2 = 65,535 10 = FFFF 16 = $FFFF(10000000000000000 아님) 2 또는 65,536 10 또는 10000 16 또는 $10000. 10000000000000000 2 , 65,536 10 , 10000 16 또는 $10000은 총 바이트 위치 수를 제공합니다.
여기, 2 16 = 65,536 = 64 x 1024 = 64 x 2 10 = 64KB(킬로바이트). Commodore-64 이름의 접미사 64는 총 메모리(RAM 및 ROM)가 64KB임을 의미합니다. 1바이트는 8비트이며, 8비트는 메모리의 한 바이트 위치에 저장됩니다.
64KB의 메모리는 페이지로 나누어집니다. 각 페이지에는 0100이 있습니다. 16 = 256 10 바이트 위치. 첫 번째 256 10 = 첫 번째 0100 16 위치는 0페이지입니다. 두 번째는 1페이지, 세 번째는 2페이지 등입니다.
65,536개의 위치를 주소 지정하기 위해서는 각 위치(주소)마다 16비트가 필요합니다. 따라서 마이크로프로세서에서 메모리까지의 주소 버스는 16개 라인으로 구성됩니다. 1비트에 한 줄. 비트는 1 또는 0입니다.
6502 µP 레지스터
레지스터는 바이트 메모리 위치에 대한 바이트 셀과 같습니다. 6502 µP에는 6개의 레지스터(8비트 레지스터 5개와 16비트 레지스터 1개)가 있습니다. 16비트 레지스터를 프로그램 카운터(Program Counter)라고 하며 줄여서 PC라고 합니다. 다음 명령어를 위한 메모리 주소를 보유합니다. 어셈블리 언어 프로그램은 메모리에 저장되는 명령어로 구성됩니다. 메모리의 특정 바이트 위치를 지정하려면 16개의 서로 다른 비트가 필요합니다. 특정 클럭 펄스에서 이 비트는 명령어 읽기를 위해 주소 버스의 16비트 주소 라인으로 전송됩니다. 6502 µP의 모든 레지스터는 다음과 같이 표시됩니다.
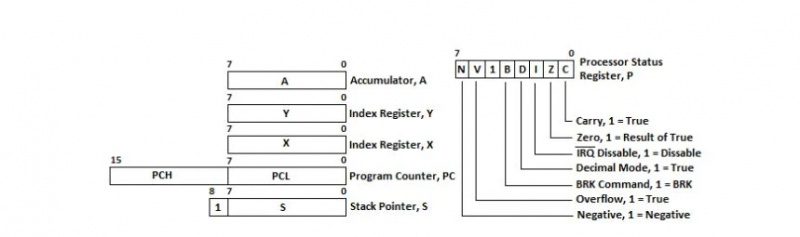
그림 4.12 6502 µP 레지스터
프로그램 카운터 또는 PC는 다이어그램에서 16비트 레지스터로 볼 수 있습니다. 하위 8비트는 프로그램 카운터 로우(Program Counter Low)에 대한 PCL로 표시됩니다. 상위 8비트는 프로그램 카운터 높음(Program Counter High)을 의미하는 PCH로 표시됩니다. Commodore-64의 메모리 명령어는 1바이트, 2바이트 또는 3바이트로 구성될 수 있습니다. PC의 16비트는 메모리에서 실행될 다음 명령을 가리킵니다. 마이크로프로세서의 회로 중 두 가지는 산술논리장치(Arithmetic Logic Unit)와 명령어 디코더(Instruction Decoder)라고 불린다. µP(마이크로프로세서)에서 처리 중인 현재 명령어의 길이가 1바이트인 경우 이 두 회로는 다음 명령어에 대한 PC를 1단위만큼 증가시킵니다. µP에서 처리 중인 현재 명령어의 길이가 2바이트인 경우(즉, 메모리에서 연속된 2바이트를 차지함을 의미), 이 두 회로는 다음 명령어에 대한 PC를 2단위만큼 증가시킵니다. µP에서 처리 중인 현재 명령어의 길이가 3바이트인 경우(즉, 메모리에서 연속적인 3바이트를 차지함을 의미), 이 두 회로는 다음 명령어에 대한 PC를 3단위만큼 증가시킵니다.
누산기 'A'는 대부분의 산술 및 논리 연산 결과를 저장하는 8비트 범용 레지스터입니다.
'X' 및 'Y' 레지스터는 각각 프로그램 단계를 계산하는 데 사용됩니다. 프로그래밍에서 카운팅은 0부터 시작합니다. 그래서 인덱스 레지스터라고 부릅니다. 그들은 몇 가지 다른 목적을 가지고 있습니다.
스택 포인터 레지스터이지만 'S'에는 9비트가 있으므로 8비트 레지스터로 간주됩니다. 그 내용은 RAM(Random Access Memory)의 페이지 1에 있는 바이트 위치를 가리킵니다. 페이지 1은 바이트 $0100(256)에서 시작됩니다. 10 )를 바이트 $01FF(511)로 10 ). 프로그램이 실행 중일 때 메모리의 한 명령어에서 다음 연속 명령어로 이동합니다. 그러나 항상 그런 것은 아닙니다. 한 메모리 영역에서 다른 메모리 영역으로 점프하여 그곳의 명령을 연속적으로 계속 실행하는 경우가 있습니다. RAM의 페이지 1이 스택으로 사용됩니다. 스택은 점프가 있는 곳에서 코드를 계속하기 위한 다음 주소가 있는 대규모 RAM 메모리 영역입니다. 점프 명령이 포함된 코드는 스택에 없습니다. 그들은 기억의 다른 곳에 있습니다. 그러나 점프 명령이 실행된 후에는 연속 주소(코드 세그먼트 아님)가 스택에 있습니다. 점프 또는 분기 명령의 결과로 그곳으로 밀려났습니다.
P의 8비트 프로세서 상태 레지스터는 특별한 종류의 레지스터입니다. 개별 비트는 서로 관련되거나 연결되지 않습니다. 각 비트는 플래그라고 불리며 다른 비트와 독립적으로 평가됩니다. 필요에 따라 플래그의 의미는 다음과 같습니다.
각 레지스터의 첫 번째 및 마지막 비트 인덱스는 이전 다이어그램의 각 레지스터 위에 표시됩니다. 레지스터의 비트 인덱스(위치) 계산은 오른쪽 0부터 시작됩니다.
2진수, 16진수, 10진수의 메모리 페이지
다음 표는 2진수, 16진수, 10진수로 된 메모리 페이지의 시작을 보여줍니다.

각 페이지에는 1,0000,0000이 있습니다. 2 100과 동일한 바이트 수 시간 256과 동일한 바이트 수 10 바이트 수. 이전 메모리 다이어그램에서는 표와 같이 페이지가 0페이지에서 위로 올라가고 아래로 내려가지 않는 것으로 표시되었습니다.
이 테이블의 2진수, 16진수 및 10진수 열은 서로 다른 기준으로 메모리 바이트 위치 주소를 제공합니다. 페이지 0의 경우 코딩 시 입력하려면 하위 바이트의 비트만 필요합니다. 상위 바이트의 비트는 항상 0(페이지 0의 경우)이므로 생략할 수 있습니다. 나머지 페이지에서는 상위 바이트의 비트를 사용해야 합니다.
이 장의 나머지 부분에서는 이전 정보를 모두 사용하여 6502 µP 어셈블리 언어를 설명합니다. 언어를 빠르게 이해하려면 독자는 10진수 대신 16진수를 더하고 빼야 합니다. 실제로는 2진수로 가정하지만 2진수로 계산하는 것은 번거롭습니다. 2진수에 두 숫자를 더할 때 캐리는 10진수에서와 마찬가지로 여전히 1이라는 점을 기억하십시오. 그러나 2진수에서 두 숫자를 뺄 때 빌림은 2가 되고 10진수에서처럼 10이 아닙니다. 16진수에 두 숫자를 더할 때 캐리는 10진수에서처럼 여전히 1입니다. 그러나 16진수에서 두 숫자를 뺄 때 빌림은 16진수이고 10진수에서와 같이 10진수는 아닙니다.
4.2 데이터 전송 지침
6502 µP에 대한 어셈블리 언어 데이터 전송 지침에 대한 다음 표를 고려하십시오.
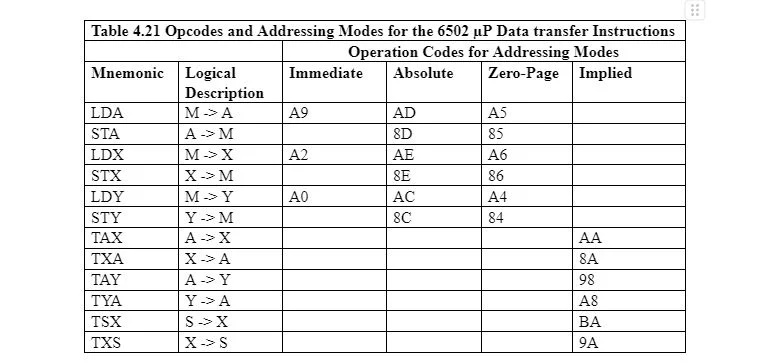
바이트(8비트)가 메모리 바이트 위치에서 누산기 레지스터, X 레지스터 또는 Y 레지스터로 복사되면 로드됩니다. 바이트가 이러한 레지스터 중 하나에서 메모리 바이트 위치로 복사되면 전송됩니다. 바이트가 한 레지스터에서 다른 레지스터로 복사되면 여전히 전송 중입니다. 테이블의 두 번째 열에서 화살표는 바이트 복사 방향을 표시합니다. 나머지 4개 열에는 서로 다른 주소 지정 모드가 표시됩니다.
주소 지정 모드 열의 항목은 16진수 명령어의 해당 니모닉 부분에 대한 실제 바이트 코드입니다. 예를 들어 AE는 AE와 같은 절대 주소 지정 모드에서 메모리에서 X 레지스터로 바이트를 로드하는 LDX의 실제 바이트 코드입니다. 16 = 10101110 2 . 따라서 메모리 바이트 위치의 LDX 비트는 10101110입니다.
명령어의 LDX 니모닉 부분에는 A2, AE 및 A6의 세 가지 가능한 바이트가 있으며 각각은 특정 주소 지정 모드에 대한 것입니다. X 레지스터에 로드되는 바이트가 메모리 바이트 위치에서 복사되지 않는 경우 값은 16진수 또는 10진수로 명령어의 LDX 니모닉(바로 뒤)으로 입력되어야 합니다. 이 장에서는 이러한 값을 16진수로 입력합니다. 이는 즉각적인 주소 지정이므로 LDX를 나타내는 메모리의 실제 바이트는 A2입니다. 16 = 10100010 2 그리고 AE는 아니고 16 이는 10101110과 같습니다. 2 .
표에서 주소 지정 모드 제목 아래의 모든 바이트는 연산 코드(Opcode)로 축약됩니다. 주소 지정 모드에 따라 하나의 니모닉에 대해 둘 이상의 opcode가 있을 수 있습니다.
메모: 컴퓨터 시스템 장치에서 '로드'라는 단어는 두 가지 의미를 가질 수 있습니다. 디스크에서 컴퓨터 메모리로 파일을 로드하는 것을 의미하거나 메모리 바이트 위치에서 마이크로프로세서 레지스터로 바이트를 전송하는 것을 의미할 수 있습니다. .
6502 µP에는 표에 있는 4가지보다 더 많은 주소 지정 모드가 있습니다.
달리 명시하지 않는 한, 이 장의 모든 사용자 프로그래밍 코드는 주소 0200에서 시작됩니다. 16 이는 메모리에 있는 사용자 영역의 시작입니다.
메모리 M과 누산기 A
누산기에 대한 메모리
즉각적인 주소 지정
다음 명령어는 숫자 FF를 저장합니다. 16 = 255 10 누산기에:
LDA #$FF
'$'는 메모리 주소를 식별하는 데에만 사용되는 것이 아닙니다. 일반적으로 뒤에 오는 숫자가 16진수임을 나타내는 데 사용됩니다. 이 경우 $FF는 메모리 바이트 위치의 주소가 아닙니다. 255번이에요 10 16진수로. 기본 16 또는 기타 이에 상응하는 첨자는 어셈블리 언어 명령어로 작성되어서는 안 됩니다. '#'은 다음에 오는 것이 누산기 레지스터에 들어갈 값임을 나타냅니다. 값은 10진법으로 쓸 수도 있지만 이 장에서는 그렇게 하지 않습니다. '#'은 즉시 주소 지정을 의미합니다.
니모닉은 해당 영어 문구와 일부 유사합니다. 'LDA #$FF'는 숫자 255를 로드한다는 의미입니다. 10 누산기 A로. 이는 이전 테이블의 즉각적인 주소 지정이므로 LDA는 AD 또는 A5가 아닌 A9입니다. 바이너리의 A9는 101010001입니다. 따라서 LDA의 A9가 메모리의 $0200 주소에 있으면 $FF는 $0301 = 0300 + 1 주소에 있습니다. #$FF는 정확하게 LDA 니모닉의 피연산자입니다.
절대 주소 지정
$FF 값이 메모리의 $0333 위치에 있는 경우 이전 명령은 다음과 같습니다.
LDA$0333
#이 없다는 점에 유의하세요. 이 경우 #이 없다는 것은 뒤에 오는 것이 메모리 주소이고 관심 있는 값(누산기에 넣을 값이 아님)이 아님을 의미합니다. 따라서 이번에는 LDA의 opcode는 A9나 A5가 아닌 AD입니다. 여기서 LDA의 피연산자는 $FF 값이 아닌 $0333 주소입니다. $FF는 꽤 멀리 있는 $0333 위치에 있습니다. 'LDA $0333' 명령은 이전 그림처럼 메모리에서 두 개가 아닌 세 개의 연속 위치를 차지합니다. LDA의 'AD'는 $0200 위치에 있습니다. 0333의 하위 바이트인 33은 $0301 위치에 있습니다. $0333의 상위 바이트인 03은 $0302 위치에 있습니다. 이는 6502 어셈블리 언어에서 사용되는 리틀 엔디안입니다. 서로 다른 마이크로프로세서의 어셈블리 언어는 다릅니다.
이는 절대 주소 지정의 예입니다. $0333은 $FF가 있는 위치의 주소입니다. 명령어는 3개의 연속 바이트로 구성되며 $FF 또는 실제 바이트 위치를 포함하지 않습니다.
제로 페이지 주소 지정
$FF 값이 페이지 0의 $0050 메모리 위치에 있다고 가정합니다. 제로 페이지의 바이트 위치는 $0000에서 시작하여 $00FF에서 끝납니다. 이들은 256 10 총 위치. Commodore-64 메모리의 각 페이지는 256입니다. 10 긴. 메모리의 제로 페이지 공간에서 가능한 모든 위치에 대해 상위 바이트는 0입니다. 제로 페이지 주소 지정 모드는 절대 주소 지정 모드와 동일하지만 상위 바이트인 00이 명령어에 입력되지 않습니다. 따라서 $0050 위치의 $FF를 누산기로 로드하려면 제로 페이지 주소 지정 모드 명령은 다음과 같습니다.
LDA$50
LDA가 A5이고 A9 또는 AD가 아닌 경우 A5 16 = 10100101 2 . 메모리의 각 바이트는 8개의 셀로 구성되며 각 셀에는 비트가 저장됩니다. 여기의 명령어는 두 개의 연속된 바이트로 구성됩니다. LDA의 A5는 $0200 메모리 위치에 있고 상위 바이트 00이 없는 $50 주소는 $0301 위치에 있습니다. 총 64K 메모리 중 1바이트를 소모하게 되는 00이 없기 때문에 메모리 공간이 절약됩니다.
메모리에 대한 누산기
절대 주소 지정
다음 명령어는 누산기에서 $1444의 메모리 위치로 바이트 값을 복사합니다.
가격은 $1444입니다
이는 누산기에서 메모리로 전송된다고 합니다. 로딩이 되지 않습니다. 로딩은 반대입니다. STA의 opcode 바이트는 8D입니다. 16 = 10001101 2 . 이 명령어는 메모리의 연속된 3바이트로 구성됩니다. 8D 16 $0200 위치에 있습니다. 44 16 $1444 주소 중 $0201 위치에 있습니다. 그리고 14 16 $0202 위치에 있습니다. 리틀 엔디안입니다. 복사되는 실제 바이트는 명령어의 일부가 아닙니다. 여기서는 STA에 대해 제로 페이지 주소 지정(표의)에 대해 85가 아닌 8D가 사용됩니다.
제로 페이지 주소 지정
다음 명령어는 바이트 값이 무엇이든 누산기에서 페이지 0의 $0050 메모리 위치로 복사합니다.
STA $0050
여기서 STA의 opcode 바이트는 85입니다. 16 = 10000101 2 . 이 명령어는 메모리에 있는 두 개의 연속 바이트로 구성됩니다. 85 16 $0200 위치에 있습니다. 50 16 $0050 주소 중 $0201 위치에 있습니다. 여기서는 주소에 하위 바이트인 1바이트만 있기 때문에 엔디안 문제가 발생하지 않습니다. 복사되는 실제 바이트는 명령어의 일부가 아닙니다. 여기서는 STA에 대해 제로 페이지 주소 지정을 위한 8D가 아닌 85가 사용됩니다.
누산기에서 메모리 위치로 바이트를 전송하기 위해 즉시 주소 지정을 사용하는 것은 의미가 없습니다. 이는 즉시 주소 지정 명령에서 $FF와 같은 실제 값을 인용해야 하기 때문입니다. 따라서 µP의 레지스터에서 임의의 메모리 위치로 바이트 값을 전송하는 경우 즉각적인 주소 지정이 불가능합니다.
LDX, STX, LDY 및 STY 니모닉
LDX 및 STX는 각각 LDA 및 STA와 유사합니다. 그러나 여기서는 A(누산기) 레지스터가 아닌 X 레지스터가 사용됩니다. LDY 및 STY는 각각 LDA 및 STA와 유사합니다. 하지만 여기서는 A 레지스터가 아닌 Y 레지스터가 사용됩니다. 특정 니모닉 및 특정 주소 지정 모드에 해당하는 16진수로 된 각 opcode에 대해서는 표 4.21을 참조하십시오.
등록 간 전송
표 4.21의 이전 두 명령어 세트는 메모리/마이크로프로세서 레지스터 복사(전송) 및 레지스터/레지스터 복사(전송)를 다룹니다. TAX, TXA, TAY, TYA, TSX 및 TXS 명령어는 마이크로프로세서의 레지스터에서 동일한 마이크로프로세서의 다른 레지스터로 복사(전송)를 수행합니다.
A에서 X로 바이트를 복사하는 명령은 다음과 같습니다.
세
X에서 A로 바이트를 복사하는 명령은 다음과 같습니다.
텍사스
A에서 Y로 바이트를 복사하는 명령은 다음과 같습니다.
손
Y에서 A로 바이트를 복사하는 명령은 다음과 같습니다.
TYA
Commodore 64 컴퓨터의 경우 스택은 메모리의 0페이지 바로 뒤에 있는 1페이지입니다. 다른 모든 페이지와 마찬가지로 25610으로 구성됩니다. 10 바이트 위치는 $0100부터 $01FF까지입니다. 일반적으로 프로그램은 메모리의 한 명령어부터 다음 연속 명령어까지 실행됩니다. 때때로 다른 메모리 코드(명령어 세트) 세그먼트로 점프하는 경우가 있습니다. 메모리 내(RAM)의 스택 영역에는 프로그램 연속을 위해 점프(또는 분기)가 중단된 다음 명령 주소가 있습니다.
스택 포인터 'S'는 6502 µP의 9비트 레지스터입니다. 첫 번째 비트(가장 왼쪽)는 항상 1입니다. 첫 번째 페이지의 모든 바이트 위치 주소는 1로 시작하고 그 뒤에 256에 대한 8개의 다른 비트가 옵니다. 10 위치. 스택 포인터에는 현재(점프된) 코드 세그먼트를 실행한 후 프로그램이 반환하고 계속해야 하는 다음 명령어의 주소가 있는 페이지 1의 위치 주소가 있습니다. 스택의 모든 주소(페이지 1) 중 첫 번째 비트가 1로 시작하므로 스택 포인터 레지스터는 나머지 8비트만 보유하면 됩니다. 결국 가장 왼쪽 비트(오른쪽에서 세어 9번째 비트)인 첫 번째 비트는 항상 1입니다.
S에서 X로 바이트를 복사하는 명령은 다음과 같습니다.
TSX
X에서 S로 바이트를 복사하는 명령은 다음과 같습니다.
TXT
레지스터-레지스터 명령어는 피연산자를 사용하지 않습니다. 그것들은 단지 니모닉으로만 구성됩니다. 각 니모닉에는 16진수로 된 opcode가 있습니다. 피연산자(메모리 주소, 값 없음)가 없기 때문에 이는 암시적 주소 지정 모드에 있습니다.
메모: X에서 Y로 또는 Y에서 X로의 전송(복사)은 없습니다.
4.3 산술 연산
6502 µP의 산술 논리 장치 회로는 한 번에 2개의 8비트 숫자만 추가할 수 있습니다. 빼지도, 곱하지도, 나누지도 않습니다. 다음 표는 산술 연산을 위한 opcode 및 주소 지정 모드를 보여줍니다.
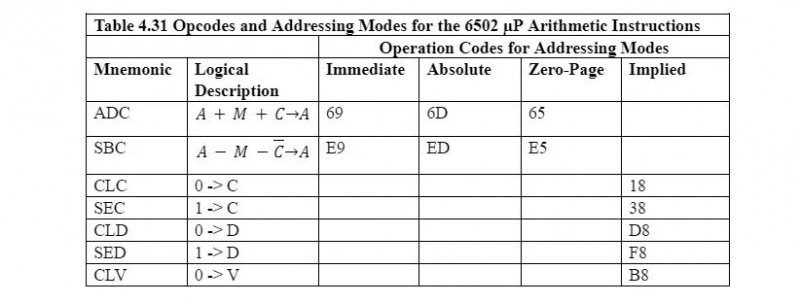
메모: 산술 연산 및 기타 유형의 연산(예: 모든 6502 니모닉)에 대한 모든 니모닉은 1바이트의 연산(op) 코드를 사용합니다. 니모닉에 대한 주소 지정 모드가 두 개 이상인 경우 동일한 니모닉에 대해 주소 지정 모드당 하나씩 서로 다른 opcode가 있습니다. 표의 C, D, V는 상태 레지스터의 플래그입니다. 그 의미는 나중에 필요에 따라 설명될 것입니다.
부호 없는 숫자 추가
6502 µP의 경우 부호 있는 숫자는 2의 보수입니다. 부호 없는 숫자는 0부터 시작하는 일반적인 양수입니다. 따라서 8비트 바이트의 경우 부호 없는 가장 작은 숫자는 00000000입니다. 2 = 0 10 = 00 16 부호가 없는 가장 큰 숫자는 11111111입니다. 2 = 255 10 = FF 16 . 두 개의 부호 없는 숫자에 대한 추가는 다음과 같습니다.
A+M+C→A
이는 누산기의 8비트 내용이 산술 논리 장치에 의해 메모리의 바이트(8비트)에 추가된다는 의미입니다. A와 M을 추가한 후 9번째 비트까지의 캐리는 상태 레지스터의 캐리 플래그 셀로 이동합니다. 상태 레지스터의 캐리 플래그 셀에 여전히 있는 이전 추가의 이전 캐리 비트도 A와 M의 합에 추가되어 A+M+C→A가 됩니다. 결과는 다시 누산기에 저장됩니다.
이자 추가가 다음과 같은 경우:
에이 + 엠
그리고 이전 캐리를 추가할 필요가 없습니다. 캐리 플래그를 지워서 0으로 만들어야 하므로 추가는 다음과 같습니다.
A+M+0→A는 A+M→A와 동일
메모: A에 M을 더하면 결과가 255보다 크기 때문에 캐리 1이 발생합니다. 10 = 11111111 2 = FF 16 , 이것은 새로운 캐리입니다. 이 새로운 1 캐리는 합산될 다음 8비트 쌍(다른 A + M)에 의해 필요한 경우 자동으로 캐리 플래그 셀로 전송됩니다.
두 개의 부호 없는 8비트를 추가하는 코드
00111111 2 +00010101 2 3F와 동일해요 16 + 15 16 63과 똑같습니다 10 +21 10 . 결과는 010101002 입니다 2 54와 똑같습니다 16 그리고 84 10 . 결과는 8비트의 최대값인 255를 초과하지 않습니다. 10 = 11111111 2 = FF 16 . 즉, 1의 결과 캐리가 없습니다. 다시 말하면 결과 캐리는 0입니다. 덧셈 이전에는 이전 캐리 1이 없습니다. 즉, 이전 캐리는 0입니다. 이 덧셈을 수행하는 코드는 다음과 같습니다. 다음과 같을 수 있습니다:
씨엘씨
LDA #$3F
ADC #$15
메모: 어셈블리 언어를 입력하는 동안 각 명령어가 끝날 때마다 키보드의 'Enter' 키를 누릅니다. 이 코드에는 세 가지 지침이 있습니다. 첫 번째 명령어(CLC)는 이전 추가에 1이 있는 경우 캐리 플래그를 지웁니다. CLC는 암시적 주소 지정 모드에서만 수행될 수 있습니다. 묵시적 주소 지정 모드에 대한 니모닉은 피연산자를 사용하지 않습니다. 이는 P의 상태 레지스터의 캐리 셀을 클리어합니다. 클리어는 캐리 플래그 셀에 비트 0을 주는 것을 의미합니다. 코드의 다음 두 명령어는 즉시 주소 지정 모드를 사용합니다. 즉시 주소 지정을 사용하면 니모닉에 대한 피연산자는 숫자(메모리도 레지스터 주소도 아님) 하나만 있습니다. 따라서 숫자 앞에는 '#'이 와야 합니다. '$'는 뒤에 오는 숫자가 16진수임을 의미합니다.
두 번째 명령어는 숫자 3F를 로드합니다. 16 어큐뮬레이터에. 세 번째 명령어의 경우 µP의 산술 논리 장치 회로는 상태 레지스터의 캐리 플래그 셀의 이전(클리어된) 캐리 0(0으로 강제됨)을 가져와서 15에 추가합니다. 16 뿐만 아니라 이미 3F에 있는 값까지 16 누산기에 저장하고 전체 결과를 다시 누산기에 넣습니다. 이 경우 캐리는 0이 됩니다. ALU(산술 논리 장치)는 상태 레지스터의 캐리 플래그 셀에 0을 보냅니다. 프로세서 상태 레지스터와 상태 레지스터는 같은 의미입니다. 캐리가 1이면 ALU는 상태 레지스터의 캐리 플래그에 1을 보냅니다.
이전 코드의 세 줄은 실행되기 전에 메모리에 있어야 합니다. CLC(암시적 주소 지정)에 대한 opcode 1816은 $0200 바이트 위치에 있습니다. 연산코드 A9 16 LDA(즉시 주소 지정)의 경우 $0201 바이트 위치에 있습니다. 더 넘버 3F 10 $0202 바이트 위치에 있습니다. 연산코드 69 16 LDA(즉시 주소 지정)의 경우 $0203 바이트 위치에 있습니다. 숫자 15 10 $0204 바이트 위치에 있습니다.
메모: LDA는 산술 명령어(니모닉)가 아닌 전송(로드) 명령어입니다.
부호 없는 16비트 두 개를 추가하는 코드
6502 µP의 모든 레지스터는 16비트인 PC(프로그램 카운터)를 제외하고 기본적으로 8비트 레지스터입니다. 상태 레지스터도 8비트 폭이지만 8비트가 함께 작동하지는 않습니다. 이 섹션에서는 8비트의 첫 번째 쌍에서 8비트의 두 번째 쌍으로 캐리를 사용하여 부호 없는 16비트 2개를 추가하는 방법을 고려합니다. 여기서 관심 있는 캐리는 8번째 비트 위치에서 9번째 비트 위치로의 캐리입니다.
숫자를 0010101010111111로 둡니다. 2 = 2ABF16 16 = 10,943 10 그리고 0010101010010101 2 = 2A95 16 = 10,901 10 . 합계는 0101010101010100입니다. 2 = 5554 16 = 21,844 10 .
이 두 개의 부호 없는 숫자를 2진법으로 더하는 것은 다음과 같습니다:

다음 표는 오른쪽부터 시작하여 8번째 비트에서 9번째 비트 위치까지 1을 캐리하는 동일한 추가를 보여줍니다.
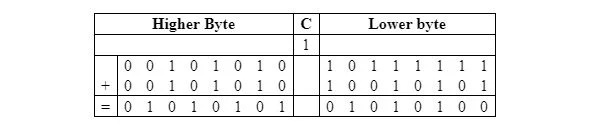
이를 코딩할 때 두 개의 하위 바이트가 먼저 추가됩니다. 그러면 ALU(산술 논리 장치)는 8번째 비트 위치에서 9번째 비트 위치로 1의 캐리를 상태 레지스터의 캐리 플래그 셀로 보냅니다. 캐리가 없는 0 1 0 1 0 1 0 0의 결과는 누산기로 이동됩니다. 그런 다음 두 번째 바이트 쌍이 캐리와 함께 추가됩니다. ADC 니모닉은 이전 캐리와 자동으로 추가되는 것을 의미합니다. 이 경우, 이전 캐리(1)는 두 번째 덧셈 이전에 변경되어서는 안 된다. 첫 번째 덧셈의 경우, 이전 캐리는 이 완전한 덧셈의 일부가 아니기 때문에 지워야 합니다(0으로 만들어야 함).
두 쌍의 바이트를 완전히 추가하는 경우 첫 번째 추가는 다음과 같습니다.
A + M + 0 -> A
두 번째 추가 사항은 다음과 같습니다.
A + M + 1 -> A
따라서 캐리 플래그는 첫 번째 추가 직전에 지워져야 합니다(값이 0으로 지정됨). 독자가 다음 설명을 읽어야 하는 다음 프로그램은 이 합산에 절대 주소 지정 모드를 사용합니다.
씨엘씨
LDA$0213
ADC $0215
; 캐리 플래그 값이 필요하기 때문에 클리어링이 없습니다.
STA $0217
LDA$0214
ADC $0216
STA $0218
6502 어셈블리 언어에서는 세미콜론이 주석을 시작합니다. 이는 프로그램 실행 시 세미콜론과 그 오른쪽에 있는 모든 항목이 무시됨을 의미합니다. 이전에 작성된 프로그램은 프로그래머가 선택한 이름과 '.asm' 확장자로 저장되는 텍스트 파일입니다. 이전 프로그램은 실행을 위해 메모리로 이동하는 정확한 프로그램이 아닙니다. 메모리에 있는 해당 프로그램을 변환된 프로그램이라고 하며 니모닉이 opcode(바이트)로 대체됩니다. 모든 주석은 어셈블리 언어 텍스트 파일에 남아 있으며 번역된 프로그램이 메모리에 도달하기 전에 제거됩니다. 실제로 현재 디스크에 저장되는 파일은 '.asm' 파일과 '.exe' 파일 두 개입니다. '.asm' 파일은 이전 그림의 파일입니다. '.exe' 파일은 모든 주석이 제거되고 모든 니모닉이 해당 opcode로 대체된 '.asm' 파일입니다. 텍스트 편집기에서 열면 '.exe' 파일을 인식할 수 없습니다. 달리 명시하지 않는 한, 이 장에서는 '.exe' 파일이 $0200 위치부터 메모리에 복사됩니다. 이것은 로드의 또 다른 의미입니다.
추가할 2개의 16비트 숫자는 절대 주소 지정을 위해 메모리에서 4바이트를 차지합니다. 즉, 숫자당 2바이트입니다(메모리는 바이트 시퀀스입니다). 절대 주소 지정을 사용하면 opcode에 대한 피연산자가 메모리에 있습니다. 합산 결과는 2바이트 너비이며 메모리에도 저장되어야 합니다. 이렇게 총 6개가 나오네요 10 = 6 16 입력과 출력을 위한 바이트. 입력은 키보드에서 나오지 않고 출력은 모니터나 프린터에서 나오지 않습니다. 이 상황에서는 입력이 메모리(RAM)에 있고 출력(합계 결과)이 메모리(RAM)로 돌아갑니다.
프로그램이 실행되기 전에 먼저 번역된 버전이 메모리에 있어야 합니다. 이전 프로그램 코드를 보면 주석이 없는 명령어가 19를 이루는 것을 알 수 있다. 10 = 13 16 바이트. 따라서 프로그램은 메모리의 $0200 바이트 위치에서 $0200 + $13 – $1 = $0212 바이트 위치를 가져옵니다($0200에서 시작하고 – $1을 의미하는 $0201이 아님). 입력 및 출력 번호에 6바이트를 추가하면 모든 프로그램이 $0212 + $6 = $0218에서 종료됩니다. 프로그램의 총 길이는 19입니다. 16 = 25 10 .
피가수(Augend)의 하위 바이트는 $0213 주소에 있어야 하고, 동일한 피가수(Augend)의 상위 바이트는 $0214 주소에 있어야 합니다(리틀 엔디안). 마찬가지로, 가수의 하위 바이트는 $0215 주소에 있어야 하고, 동일한 가수의 상위 바이트는 $0216 주소에 있어야 합니다(리틀 엔디안). 결과(합계)의 하위 바이트는 $0217 주소에 있어야 하고, 동일한 결과의 상위 바이트는 $0218 주소에 있어야 합니다(리틀 엔디안).
연산코드 18 16 CLC(암시적 주소 지정)의 경우 바이트 위치 $0200에 있습니다. “LDA $0213”의 opcode, 즉 AD 16 LDA(절대 주소 지정)의 경우 바이트 위치 $0201에 있습니다. 피가수의 하위 바이트인 10111111은 $0213의 메모리 바이트 위치에 있습니다. 각 opcode는 1바이트를 차지한다는 점을 기억하세요. “LDA $0213”의 “$0213” 주소는 $0202와 $0203의 바이트 위치에 있습니다. 'LDA $0213' 명령어는 피가수의 하위 바이트를 누산기에 로드합니다.
'ADC $0215'의 opcode(예: 6D) 16 ADC(절대 주소 지정)의 경우 바이트 위치 $0204에 있습니다. 가수의 하위 바이트인 10010101은 $0215의 바이트 위치에 있습니다. “ADC $0215”의 “$0215” 주소는 $0205와 $0206의 바이트 위치에 있습니다. 'ADC $0215' 명령어는 이미 누산기에 있는 피가수의 하위 바이트에 가수의 하위 바이트를 추가합니다. 결과는 다시 누산기에 저장됩니다. 8번째 비트 이후의 캐리는 상태 레지스터의 캐리 플래그로 전송됩니다. 캐리 플래그 셀은 상위 바이트를 두 번째로 추가하기 전에 지워져서는 안 됩니다. 이 캐리는 상위 바이트의 합계에 자동으로 추가됩니다. 실제로 CLC로 인해 처음에 자동으로 하위 바이트의 합계에 캐리 0이 추가됩니다(캐리가 추가되지 않은 것과 동일).
댓글은 다음 48을 차지합니다. 10 = 30 16 바이트. 그러나 이는 '.asm' 텍스트 파일에만 남아 있습니다. 메모리에 도달하지 않습니다. 어셈블러(프로그램)에 의해 수행되는 번역에 의해 제거됩니다.
다음 명령어인 'STA $0217'의 경우 STA의 opcode는 8D입니다. 16 (절대 주소 지정)은 $0207의 바이트 위치에 있습니다. “STA $0217”의 “$0217” 주소는 $0208과 $0209의 메모리 위치에 있습니다. 'STA $0217' 명령어는 누산기의 8비트 내용을 메모리 위치 $0217에 복사합니다.
피가수의 상위 바이트인 00101010은 $0214의 메모리 위치에 있고, 가수의 상위 바이트인 00101010은 $02의 바이트 위치에 있습니다. 16 . LDA(절대 주소 지정)에 대한 AD16인 'LDA $0214'의 opcode는 $020A의 바이트 위치에 있습니다. “LDA $0214”의 “$0214” 주소는 $020B와 $020C 위치에 있습니다. 'LDA $0214' 명령어는 피가수의 상위 바이트를 누산기에 로드하여 누산기에 있는 모든 내용을 지웁니다.
6D인 “ADC $0216”의 opcode 16 ADC(절대 주소 지정)의 경우 $020D의 바이트 위치에 있습니다. 'ADC 0216'의 '$0216' 주소는 $020E 및 $020F의 바이트 위치에 있습니다. 'ADC $0216' 명령어는 이미 누산기에 있는 피가수의 상위 바이트에 가수의 상위 바이트를 추가합니다. 결과는 다시 누산기에 저장됩니다. 캐리가 1인 경우 두 번째 추가를 위해 자동으로 상태 레지스터의 캐리 셀에 배치됩니다. 이 문제에서는 16번째 비트(왼쪽) 이후의 캐리가 필요하지 않지만 캐리 플래그가 1이 되었는지 확인하여 캐리가 1이 발생했는지 확인하는 것이 좋습니다.
다음이자 마지막 명령어인 'STA $0218'의 경우 8D16(절대 주소 지정)인 STA의 opcode는 $0210의 바이트 위치에 있습니다. “STA $0218”의 “$0218” 주소는 $0211과 $0212의 메모리 위치에 있습니다. 'STA $0218' 명령어는 누산기의 8비트 내용을 메모리 위치 $0218에 복사합니다. 두 개의 16비트 숫자를 더한 결과는 0101010101010100이며, $0217의 메모리 위치에 있는 하위 바이트 01010100과 $0218의 메모리 위치에 있는 상위 바이트 01010101(리틀 엔디안)입니다.
빼기
6502 µP의 경우 부호 있는 숫자는 2의 보수입니다. 2의 보수는 8비트, 16비트 또는 8비트의 배수일 수 있습니다. 2의 보수에서는 왼쪽에서 첫 번째 비트가 부호 비트입니다. 양수의 경우 이 첫 번째 비트는 부호를 나타내는 0입니다. 나머지 비트는 일반적인 방식으로 숫자를 형성합니다. 음수의 2의 보수를 얻으려면 해당 양수의 비트를 모두 반전시킨 후 오른쪽 끝부터 결과에 1을 더합니다.
하나의 양수를 다른 양수에서 빼기 위해 빼기는 2의 보수 음수로 변환됩니다. 그런 다음 피감수와 새 음수가 일반적인 방법으로 추가됩니다. 따라서 8비트 빼기는 다음과 같습니다.
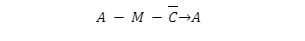
캐리가 1로 가정되는 경우. 누산기의 결과는 2의 보수의 차이입니다. 따라서 두 숫자를 빼려면 캐리 플래그를 1로 설정해야 합니다.
두 개의 16비트 숫자를 뺄 때 두 개의 16비트 숫자를 더할 때처럼 빼기가 두 번 수행됩니다. 뺄셈은 6502 µP의 덧셈 형태이므로 두 개의 16비트 숫자를 뺄 때 캐리 플래그는 첫 번째 뺄셈에 대해 한 번만 설정됩니다. 두 번째 빼기의 경우 캐리 플래그 설정이 자동으로 수행됩니다.
8비트 숫자 또는 16비트 숫자에 대한 빼기 프로그래밍은 덧셈 프로그래밍과 유사하게 수행됩니다. 단, 캐리 플래그는 맨 처음에 설정해야 합니다. 이를 수행하는 니모닉은 다음과 같습니다. 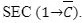
16비트 양수를 사용한 뺄셈
다음 숫자로 빼기를 고려하십시오.

이 뺄셈에는 2의 보수가 포함되지 않습니다. 6502 µP의 뺄셈은 2의 보수로 수행되므로 2진수의 뺄셈은 다음과 같이 수행됩니다.
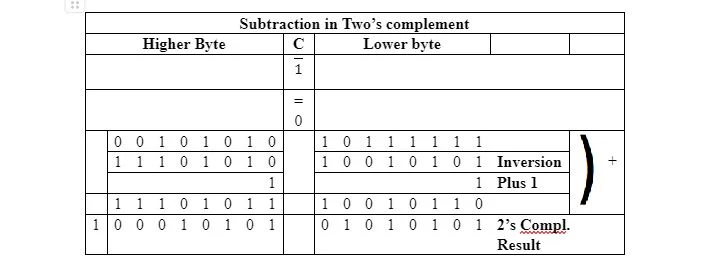
2의 보수 결과는 일반적인 뺄셈에서 얻은 결과와 동일합니다. 단, 오른쪽에서 17번째 비트 위치로 가는 1은 무시된다는 점에 유의하세요. 피감수와 감수는 각각 두 개의 8비트로 분할됩니다. 감수 하위 바이트의 10010110에 대한 2의 보수는 상위 바이트 및 캐리와 관계없이 결정됩니다. 하위 바이트의 상위 바이트에 대한 11101011의 2의 보수는 하위 바이트 및 캐리와 관계없이 결정됩니다.
피감수의 16비트는 이미 왼쪽에서 0부터 시작하는 2의 보수입니다. 따라서 비트 단위로 조정할 필요가 없습니다. 6502 µP에서는 피감수의 하위 바이트가 감산의 2의 보수 하위 바이트에 아무런 수정 없이 추가됩니다. 전체 피감수의 16비트가 이미 2의 보수(왼쪽 첫 번째 비트가 0임)에 있어야 하기 때문에 피감수의 하위 바이트는 2의 보수로 변환되지 않습니다. 이 첫 번째 추가에서는 1=0 SEC 명령으로 인해 강제 캐리 1이 추가됩니다.
현재 유효 감산에서는 8번째 비트에서 9번째 비트(오른쪽부터)까지 1(덧셈)의 캐리가 있습니다. 이는 사실상 뺄셈이기 때문에 상태 레지스터의 캐리 플래그에 있어야 하는 비트는 모두 보수(반전)됩니다. 따라서 C 플래그에서는 1의 캐리가 0이 됩니다. 두 번째 연산에서는 피감수의 상위 바이트가 감수의 상위 2의 보수 바이트에 추가됩니다. 상태 레지스터의 자동으로 보완된 캐리 플래그 비트(이 경우 0)도 (상위 바이트에) 추가됩니다. 오른쪽에서 16번째 비트를 넘어서는 1은 무시됩니다.
다음은 다음과 같이 모든 구성표를 코딩하는 것입니다.
비서
LDA$0213
SBC $0215
; 반전된 캐리 플래그 값이 필요하기 때문에 클리어링이 필요하지 않습니다.
STA $0217
LDA$0214
SBC $0216
STA $0218
6502 어셈블리 언어에서는 세미콜론이 메모리의 번역된 프로그램 버전에 포함되지 않은 주석을 시작한다는 점을 기억하십시오. 뺄셈을 위한 두 개의 16비트 숫자는 절대 주소 지정으로 4바이트의 메모리를 차지합니다. 숫자당 2개(메모리는 일련의 바이트임) 이러한 입력은 키보드에서 발생하지 않습니다. 합산 결과는 2바이트이며 메모리의 다른 위치에 배치되어야 합니다. 이 출력은 모니터나 프린터로 전달되지 않습니다. 기억 속으로 갑니다. 이렇게 총 6개가 나오네요 10 = 6 16 입력 및 출력을 위한 바이트가 메모리(RAM)에 저장됩니다.
프로그램이 실행되기 전에 먼저 메모리에 있어야 합니다. 프로그램 코드를 보면 주석이 없는 명령어가 19를 이루는 것을 알 수 있다. 10 = 13 16 바이트. 이 장의 모든 프로그램은 $0200의 메모리 위치에서 시작하므로 프로그램은 메모리의 $0200 바이트 위치에서 $0200 + $13 – $1 = $0212 바이트 위치($0201이 아닌 $0200에서 시작)까지 이동합니다. 이 범위에는 입력 및 출력 바이트 영역이 포함되지 않습니다. 두 개의 입력 번호는 4바이트를 사용하고 하나의 출력 번호는 2바이트를 사용합니다. 입력 및 출력 번호에 6바이트를 추가하면 $0212 + $6 = $0218로 끝나는 프로그램 범위가 만들어집니다. 프로그램의 총 길이는 19입니다. 16 = 25 10 .
피감수의 하위 바이트는 $0213 주소에 있어야 하고, 동일한 피감수의 상위 바이트는 $0214 주소에 있어야 합니다(리틀 엔디안). 마찬가지로 하위 바이트는 $0215 주소에 있어야 하고, 동일한 하위 바이트는 $0216 주소에 있어야 합니다(리틀 엔디안). 결과(차이)의 하위 바이트는 $0217 주소에 있어야 하고, 동일한 결과의 상위 바이트는 $0218 주소에 있어야 합니다(리틀 엔디안).
38의 opcode 16 SEC(암시적 주소 지정)의 경우 $0200 주소에 있습니다. 이 장의 모든 프로그램은 $0200의 메모리 위치에서 시작하여 그곳에 있었던 모든 프로그램을 무효화한다고 가정합니다. 달리 명시되지 않는 한. “LDA $0213”의 opcode, 즉 AD 16 , LDA(절대 주소 지정)의 경우 $0201 바이트 위치에 있습니다. 피감수의 하위 바이트인 10111111은 $0213의 메모리 바이트 위치에 있습니다. 각 opcode는 1바이트를 차지한다는 점을 기억하세요. “LDA $0213”의 “$0213” 주소는 $0202와 $0203의 바이트 위치에 있습니다. 'LDA $0213' 명령어는 피감수의 하위 바이트를 누산기에 로드합니다.
“SBC $0215”의 opcode(예: ED) 16 , SBC(절대 주소 지정)의 경우 $0204 바이트 위치에 있습니다. 01101010인 감수의 하위 바이트는 $0215 바이트 위치에 있습니다. “ADC $0215”의 “$0215” 주소는 $0205와 $0206의 바이트 위치에 있습니다. 'SBC $0215' 명령어는 누산기에 이미 있는 피감수의 하위 바이트에서 감산의 하위 바이트를 뺍니다. 이것은 2의 보수 뺄셈입니다. 결과는 다시 누산기에 저장됩니다. 8번째 비트 이후 캐리의 보수(반전)는 상태 레지스터의 캐리 플래그로 전송됩니다. 이 캐리 플래그는 더 높은 바이트를 사용하여 두 번째 빼기 전에 지워서는 안 됩니다. 이 캐리는 더 높은 바이트의 빼기에 자동으로 추가됩니다.
댓글은 다음 57을 차지합니다. 10 = 3916 16 바이트. 그러나 이는 '.asm' 텍스트 파일에만 남아 있습니다. 메모리에 도달하지 않습니다. 어셈블러(프로그램)에 의해 수행되는 번역에 의해 제거됩니다.
'STA $0217'인 다음 명령의 경우 STA의 opcode, 즉 8D 16 (절대 주소 지정)은 $0207 바이트 위치에 있습니다. “STA $0217”의 “$0217” 주소는 $0208과 $0209의 메모리 위치에 있습니다. 'STA $0217' 명령어는 누산기의 8비트 내용을 메모리 위치 $0217에 복사합니다.
피감수의 상위 바이트인 00101010은 메모리 위치 $0214에 있고 감수의 상위 바이트인 00010101은 바이트 위치 $0216에 있습니다. “LDA $0214”의 opcode, 즉 AD 16 LDA(절대 주소 지정)의 경우 $020A 바이트 위치에 있습니다. “LDA $0214”의 “$0214” 주소는 $020B와 $020C 위치에 있습니다. 'LDA $0214' 명령어는 피감수의 상위 바이트를 누산기에 로드하여 누산기에 있는 모든 내용을 지웁니다.
'SBC $0216'의 opcode(예: ED) 16 SBC(절대 주소 지정)의 경우 $020D 바이트 위치에 있습니다. “SBC $0216”의 “$0216” 주소는 $020E 및 $020F의 바이트 위치에 있습니다. 'SBC $0216' 명령어는 누산기에 이미 있는 피감수(2의 보수)의 상위 바이트에서 감산의 상위 바이트를 뺍니다. 결과는 다시 누산기에 저장됩니다. 이 두 번째 뺄셈에 대해 1의 캐리가 있는 경우 해당 보수가 상태 레지스터의 캐리 셀에 자동으로 배치됩니다. 이 문제에서는 16번째 비트(왼쪽) 이후의 캐리가 필요하지 않지만 캐리 플래그를 확인하여 보수 캐리가 발생하는지 확인하는 것이 좋습니다.
'STA $0218'인 다음이자 마지막 명령어의 경우 STA의 opcode, 즉 8D 16 (절대 주소 지정)은 $0210 바이트 위치에 있습니다. “STA $0218”의 “$0218” 주소는 $0211과 $0212의 메모리 위치에 있습니다. 'STA $0218' 명령어는 누산기의 8비트 내용을 메모리 위치 $0218에 복사합니다. 두 개의 16비트 숫자를 뺄셈한 결과는 0001010101010101이며, 메모리 위치 $0217의 하위 바이트 01010101과 메모리 위치 $0218의 상위 바이트 00010101(리틀 엔디안)입니다.
6502 µP에는 덧셈만을 위한 회로와 간접적인 2의 보수 뺄셈을 위한 회로가 있습니다. 곱셈과 나눗셈을 위한 회로가 없습니다. 곱셈과 나눗셈을 수행하려면 부분 곱의 이동과 부분 배당을 포함한 세부 사항이 포함된 어셈블리 언어 프로그램을 작성해야 합니다.
4.4 논리 연산
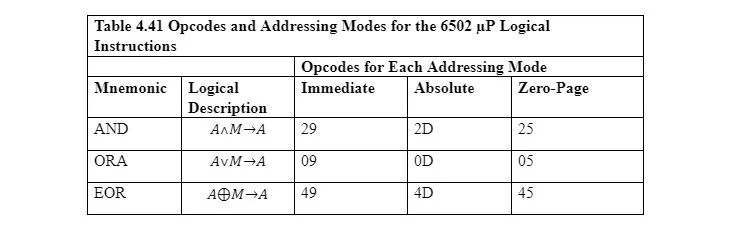
6502 µP에서 OR에 대한 니모닉은 ORA이고 배타적 OR에 대한 니모닉은 EOR입니다. 논리 연산에는 묵시적인 주소 지정이 없습니다. 묵시적 주소 지정에는 피연산자가 사용되지 않습니다. 각 논리 연산자는 두 개의 피연산자를 사용해야 합니다. 첫 번째는 누산기에 있고 두 번째는 메모리 또는 명령어에 있습니다. 결과(8비트)는 다시 누산기로 돌아갑니다. 누산기의 첫 번째 항목은 즉각적인 명령에 의해 거기에 배치되거나 절대 주소 지정을 통해 메모리에서 복사됩니다. 이 섹션에서는 설명을 위해 0페이지 주소 지정만 사용됩니다. 이러한 논리 연산자는 모두 비트 연산자입니다.
그리고
다음 표에서는 2진수, 16진수, 10진수의 비트별 AND를 보여줍니다.
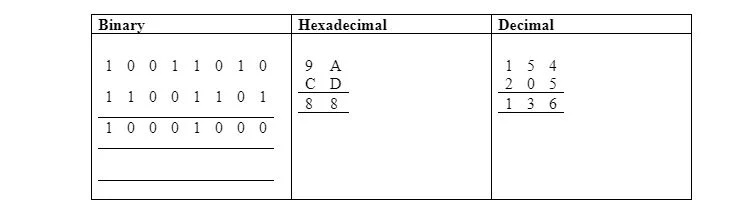
이 장의 모든 프로그램은 $0200의 메모리 바이트 위치에서 시작해야 합니다. 그러나 이 섹션의 프로그램은 상위 바이트 00000000 없이 페이지 0을 사용하는 방법을 설명하기 위해 페이지 0에 있습니다. 2 . 이전 ANDing은 다음과 같이 코딩될 수 있습니다.
LDA #$9A ; 메모리가 아닌 – 즉각적인 주소 지정
그리고 #$CD ; 메모리가 아닌 – 즉각적인 주소 지정
STA $30 ; 0 기반 $0030에 $88 저장
또는
다음 표에서는 2진수, 16진수, 10진수의 비트별 OR을 보여줍니다.
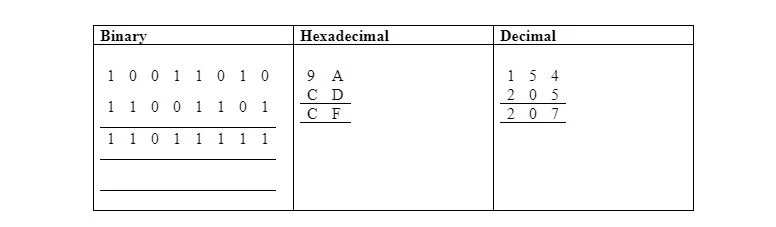
LDA #$9A ; 메모리가 아닌 – 즉각적인 주소 지정
ORA #$CD ; 메모리가 아닌 – 즉각적인 주소 지정
STA $30 ; $CF를 0부터 시작하는 $0030에 저장합니다.
무료
다음 표에서는 2진수, 16진수, 10진수의 비트별 XOR을 보여줍니다.

LDA #$9A ; 메모리가 아닌 – 즉각적인 주소 지정
EOR #$CD ; 메모리가 아닌 – 즉각적인 주소 지정
STA $30 ; 0 기반 $0030에 $57를 저장합니다.
4.5 이동 및 회전 작업
이동 및 회전 연산자에 대한 니모닉 및 연산 코드는 다음과 같습니다.
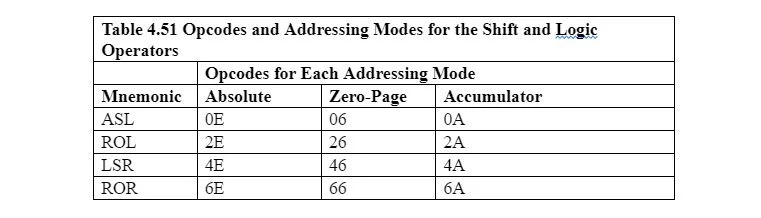
ASL: 누산기 또는 메모리 위치의 한 비트를 왼쪽으로 이동하여 비어 있는 가장 오른쪽 셀에 0을 삽입합니다.
LSR: 누산기 또는 메모리 위치의 한 비트를 오른쪽으로 이동하여 비어 있는 가장 왼쪽 셀에 0을 삽입합니다.
ROL: 누산기 또는 메모리 위치의 왼쪽으로 1비트를 회전하여 왼쪽에서 삭제된 비트를 비어 있는 가장 오른쪽 셀에 삽입합니다.
ROR: 누산기 또는 메모리 위치의 한 비트 오른쪽으로 회전하여 오른쪽에서 삭제된 비트를 비어 있는 가장 왼쪽 셀에 삽입합니다.
누산기를 사용하여 이동 또는 회전을 수행하려면 명령은 다음과 같습니다.
LSR A
이는 누산기 주소 지정 모드라는 또 다른 주소 지정 모드를 사용합니다.
바이트 메모리 위치로 이동 또는 회전을 수행하려면 명령은 다음과 같습니다.
ROR $2BCD
여기서 2BCD는 메모리 위치입니다.
이동이나 회전을 위한 즉각적 또는 암시적 주소 지정 모드는 없습니다. 명령어에만 남아 있는 숫자를 이동하거나 회전할 필요가 없기 때문에 즉시 주소 지정 모드가 없습니다. 6502 µP 설계자는 누산기(A 레지스터)의 내용이나 메모리 바이트 위치만 이동하거나 회전하기를 원하기 때문에 묵시적인 주소 지정 모드가 없습니다.
4.6 상대 주소 지정 모드
마이크로프로세서는 실행될 다음 명령을 가리키기 위해 항상 프로그램 카운터(PC)를 1, 2 또는 3 단위씩 증가시킵니다. 6502 µP에는 BVS라는 니모닉이 있는 명령어가 있습니다. 이는 Branch on Overflow Set을 의미합니다. PC는 2바이트로 구성된다. 이 명령어로 인해 PC는 정상적인 증가로 인해 발생하지 않고 다음 명령어가 실행될 때 다른 메모리 주소를 갖게 됩니다. 이는 PC의 콘텐츠에 오프셋이라는 값을 더하거나 빼는 방식으로 이루어집니다. 그러면 PC는 컴퓨터가 그곳에서 계속 실행할 수 있도록 다른(분기된) 메모리 위치를 가리킵니다. 오프셋은 -128의 정수입니다. 10 +127까지 10 (2의 보수). 따라서 오프셋을 사용하면 메모리에서 점프가 진행될 수 있습니다. 기억에 남는 것이 긍정적인 것인지 뒤쳐지는 것인지, 아니면 부정적인 것인지.
BVS 명령어는 오프셋인 피연산자를 하나만 사용합니다. BVS는 상대 주소 지정을 사용합니다. 다음 지침을 고려하십시오.
BVS $7F
2루수 7층 시간 01111111입니다 2 = 127 10 . 다음 명령을 위해 PC에 있는 콘텐츠가 $0300라고 가정합니다. BVS 명령어는 $7F(이미 2의 보수에 있는 양수)를 $0300에 추가하여 $037F를 제공합니다. 따라서 $0300의 메모리 위치에서 실행될 다음 명령어 대신 $037F(대략 페이지의 절반 차이)의 메모리 위치에 있습니다.
다른 분기 명령어도 있지만 BVS는 상대 주소 지정을 설명하는 데 사용하기에 매우 좋은 명령어입니다. 상대 주소 지정은 분기 명령어를 처리합니다.
4.7 인덱스 주소 지정과 간접 주소 지정을 별도로
이러한 주소 지정 모드를 통해 6502 µP는 적은 수의 명령으로 짧은 시간 내에 엄청난 양의 데이터를 처리할 수 있습니다. 전체 Comodore-64 메모리에는 64KB 위치가 있습니다. 따라서 16비트의 임의의 바이트 위치에 액세스하려면 2바이트를 만드는 것이 필요합니다. 2바이트가 필요한 유일한 예외는 메모리의 명령이 차지하는 공간을 절약하기 위해 상위 바이트 $00가 생략되는 페이지 0의 경우입니다. 페이지 0이 아닌 주소 지정 모드를 사용하면 16비트 메모리 주소의 상위 바이트와 하위 바이트가 모두 어떻게든 대부분 표시됩니다.
기본 인덱스 주소 지정
절대 인덱스 주소 지정
X 또는 Y 레지스터를 인덱스 레지스터라고 합니다. 다음 지침을 고려하십시오.
LDA $C453,X
값이 6이라고 가정합니다. 시간 X 레지스터에 있습니다. 6은 명령어 어디에도 입력되지 않습니다. 이 명령어는 6H 값을 C453에 추가합니다. 시간 이는 아직 조립될 텍스트 파일에 입력된 명령의 일부입니다 – C453 시간 + 6 시간 = C459 시간 . LDA는 누산기에 바이트를 로드하는 것을 의미합니다. 누산기에 로드될 바이트는 $C459 주소에서 나옵니다. 명령어와 함께 입력된 $C453과 6의 합인 $C459 시간 X 레지스터에서 발견된 주소는 누산기에 로드될 바이트가 나오는 유효 주소가 됩니다. 6이면 시간 Y 레지스터에 있으면 명령어에서 X 대신 Y가 입력됩니다.
입력된 명령문에서 $C453은 기본 주소로 알려져 있으며 6 시간 X 또는 Y 레지스터의 유효 주소에 대한 계산 또는 인덱스 부분으로 알려져 있습니다. 기본 주소는 메모리의 모든 바이트 주소를 참조할 수 있으며 다음 256 10 X 또는 Y 레지스터의 시작 인덱스(또는 개수)가 0이라고 가정하면 주소에 액세스할 수 있습니다. 1바이트는 최대 256개의 연속 범위를 제공할 수 있다는 점을 기억하세요. 10 숫자(예: 00000000 2 11111111로 2 ).
따라서 절대 주소 지정은 유효 주소를 얻기 위해 명령어로 입력한 16개 주소에 X 또는 Y 레지스터에 이미 입력된(다른 명령어에 의해 입력된) 내용을 추가합니다. 입력된 명령어에서 두 개의 인덱스 레지스터는 쉼표 뒤에 입력된 X 또는 Y로 구분됩니다. X 또는 Y가 입력됩니다. 둘 다는 아닙니다.
모든 프로그램을 텍스트 편집기에 입력하고 '.asm' 확장자 파일 이름으로 저장한 후 다른 프로그램인 어셈블러는 입력된 프로그램을 메모리에 로드된 프로그램으로 변환해야 합니다. 이전 명령인 'LDA $C453,X'는 메모리에서 5바이트가 아닌 3바이트 위치를 차지합니다.
LDA와 같은 니모닉은 둘 이상의 opcode(다른 바이트)를 가질 수 있다는 점을 기억하십시오. X 레지스터를 사용하는 명령어의 opcode는 Y 레지스터를 사용하는 opcode와 다릅니다. 어셈블러는 입력된 명령어를 기반으로 사용할 opcode를 알고 있습니다. 'LDA $C453,X'에 대한 1바이트 opcode는 'LDA $C453,Y'에 대한 1바이트 opcode와 다릅니다. 실제로 'LDA $C453,X'의 LDA에 대한 opcode는 BD이고 'LDA $C453,9'의 LDA에 대한 opcode는 BD입니다.
LDA의 opcode가 $0200 바이트 위치에 있는 경우. 그런 다음 $C453의 16비트 주소는 $0201 및 $0202인 메모리의 바이트 위치 다음을 차지합니다. 특정 opcode 바이트는 관련된 것이 X 레지스터인지 Y 레지스터인지를 나타냅니다. 따라서 'LDA $C453,X' 또는 'LDA $C453,Y'인 어셈블된 언어 명령어는 메모리에서 4바이트 또는 5바이트가 아닌 3개의 연속 바이트를 차지합니다.
제로 페이지 인덱스 주소 지정
0 페이지 인덱스 주소 지정은 이전에 설명한 절대 인덱스 주소 지정과 유사하지만 대상 바이트는 페이지 0($0000에서 $00FF까지)에만 있어야 합니다. 이제 제로 페이지를 처리할 때 상위 바이트는 항상 00입니다. 시간 일반적으로 메모리 위치는 피합니다. 따라서 일반적으로 페이지 0은 $00부터 FF까지 시작한다고 언급됩니다. 따라서 'LDA $C453,X'의 이전 명령은 다음과 같습니다.
LDA $53.X
페이지 0 위의 페이지를 참조하는 상위 바이트인 $C4는 로드될 예상 대상 바이트를 페이지 0 외부 및 위의 누적 바이트에 넣기 때문에 이 명령어에 사용할 수 없습니다.
명령어에 입력된 값이 인덱스 레지스터의 값에 추가될 때 그 합은 페이지 0(FF) 이상의 결과를 제공해서는 안 됩니다. 시간 ). 따라서 'LDA $FF, X'와 같은 명령과 FF와 같은 값을 갖는 것은 불가능합니다. 시간 FF 때문에 인덱스 레지스터에 시간 +FF 시간 = 200 시간 메모리에서 페이지 2(세 번째 페이지)의 첫 번째 바이트($0200) 위치는 페이지 0에서 멀리 떨어져 있습니다. 따라서 제로 페이지 인덱스 주소 지정을 사용하면 유효 주소는 페이지 0에 있어야 합니다.
간접 주소 지정
점프 절대 주소 지정
절대 간접 주소 지정을 논의하기 전에 먼저 JMP 절대 주소 지정을 살펴보는 것이 좋습니다. 관심 있는 값(대상 바이트)이 있는 주소가 $8765라고 가정합니다. 이는 2바이트로 구성된 16비트입니다. 상위 바이트는 87입니다. 시간 하위 바이트는 65입니다. 시간 . 따라서 $8765에 해당하는 2바이트가 다음 명령어를 위해 PC(프로그램 카운터)에 저장됩니다. 어셈블리 언어 프로그램(파일)에 입력되는 내용은 다음과 같습니다.
JMP $8765
메모리의 실행 프로그램은 $8765에 액세스한 주소에서 점프합니다. JMP 니모닉에는 4C, 6C, 7C의 세 가지 opcode가 있습니다. 이 절대 주소 지정을 위한 opcode는 4C입니다. JMP 절대 간접 주소 지정을 위한 opcode는 6C입니다(다음 그림 참조).
절대 간접 주소 지정
점프(JMP) 명령에만 사용됩니다. 관심 있는 바이트(대상 바이트)가 있는 주소가 $8765라고 가정합니다. 이는 2바이트로 구성된 16비트입니다. 상위 바이트는 87입니다. 시간 하위 바이트는 65입니다. 시간 . 절대 간접 주소 지정을 사용하면 이 두 바이트는 실제로 메모리의 다른 위치에 있는 두 개의 연속 바이트 위치에 위치합니다.
$0210 및 $0211의 메모리 위치에 있다고 가정합니다. 그러면 관심 주소의 하위 바이트인 65가 나옵니다. 시간 $0210 주소에 있고 상위 바이트는 87입니다. 시간 $0211 주소에 있습니다. 이는 관심 있는 하위 메모리 바이트가 하위 연속 주소로 이동하고 관심 있는 상위 메모리 바이트가 상위 연속 주소(리틀 엔디안)로 이동함을 의미합니다.
16비트 주소는 메모리에서 두 개의 연속된 주소를 참조할 수 있습니다. 그런 의미에서 $0210 주소는 $0210과 $0211의 주소를 의미합니다. $0210과 $0211의 주소 쌍은 대상 바이트의 최종 주소(2바이트의 16비트)를 보유하며 하위 바이트는 65입니다. 시간 $0210 및 상위 바이트 87 시간 $0211에 있습니다. 따라서 입력된 점프 명령은 다음과 같습니다.
JMP ($0210)
JMP 니모닉에는 4C, 6C, 7C의 세 가지 opcode가 있습니다. 절대 간접 주소 지정을 위한 opcode는 6C입니다. 텍스트 파일에 입력된 내용은 'JMP ($0210)'입니다. 괄호 때문에 어셈블러(번역기)는 JMP에 4C나 7C가 아닌 opcode 6C를 사용합니다.
절대 간접 주소 지정에는 실제로 세 개의 메모리 영역이 있습니다. 첫 번째 영역은 $0200, $0201, $0202의 바이트 위치로 구성될 수 있습니다. 여기에는 'JMP ($0210)' 명령어에 대한 3바이트가 있습니다. 첫 번째 영역 바로 옆에 있을 필요는 없는 두 번째 영역은 $0210과 $0211의 두 연속 바이트 위치로 구성됩니다. 어셈블리 언어 프로그램 명령에 입력되는 것은 여기서 하위 바이트($0210)입니다. 관심주소가 $8765일 경우 하위바이트 65 시간 $0210 바이트 위치에 있고 상위 바이트인 87에 있습니다. 시간 $0211 바이트 위치에 있습니다. 세 번째 영역은 단 하나의 바이트 위치로 구성됩니다. 대상 바이트(관심 있는 최종 바이트)의 $8765 주소입니다. 연속된 주소 쌍인 $0210과 $0211에는 관심 있는 주소인 $8765 포인터가 있습니다. 컴퓨팅 해석 후 대상 바이트에 액세스하기 위해 PC(프로그램 카운터)에 들어가는 것은 $8765입니다.
제로 페이지 간접 주소 지정
이 주소 지정은 절대 간접 주소 지정과 동일하지만 포인터가 페이지 0에 있어야 합니다. 포인터 영역의 하위 바이트 주소는 다음과 같이 입력된 명령어에 포함됩니다.
JMP ($50)
포인터의 상위 바이트는 $51 바이트 위치에 있습니다. (지정된) 유효 주소가 페이지 0에 있을 필요는 없습니다.
따라서 인덱스 주소 지정을 사용하면 인덱스 레지스터의 값이 유효 주소를 갖기 위해 명령어에 제공된 기본 주소에 추가됩니다. 간접 주소 지정은 포인터를 사용합니다.
4.8 인덱스 간접 주소 지정
절대 인덱스 간접 주소 지정
이 주소 지정 모드는 JMP 명령어에만 사용됩니다.
절대 간접 주소 지정에는 두 개의 연속 바이트 주소가 있는 지정된 값(바이트)이 있습니다. 이들 두 개의 연속된 주소는 메모리의 연속된 두 바이트의 포인터 영역에 있는 포인터를 형성합니다. 포인터 영역의 하위 바이트는 괄호 안의 명령어에 입력되는 내용입니다. 포인터는 가리키는 값의 주소입니다. 이전 상황에서는 $8765가 포인트 값의 주소입니다. $0210(뒤에 $0211)은 내용이 포인터인 $8765인 주소입니다. 절대 간접 주소 지정 모드에서는 괄호를 포함하여 프로그램(텍스트 파일)에 ($0210)을 입력합니다.
반면, 절대 인덱스 간접 주소 지정 모드에서는 X 레지스터의 값을 입력된 주소에 추가하여 포인터 영역의 하위 주소 바이트가 형성됩니다. 예를 들어, 포인터가 $0210의 주소 위치에 있는 경우 입력된 명령어는 다음과 같을 수 있습니다.
JMP ($020A,X)
X 레지스터의 값이 6인 경우 시간 . 020A 시간 + 6 시간 = 0210 시간 . Y 레지스터는 이 주소 지정 모드에서 사용되지 않습니다.
제로 페이지 인덱스 간접 주소 지정
이 주소 지정 모드는 Y 레지스터가 아닌 X 레지스터를 사용합니다. 이 주소 지정 모드를 사용하면 2바이트 주소 포인터 영역에 여전히 가리키는 값과 포인터가 있습니다. 포인터에 대한 페이지 0에는 두 개의 연속 바이트가 있어야 합니다. 명령어에 입력된 주소는 1바이트 주소입니다. 이 값은 X 레지스터의 값에 추가되고 모든 캐리는 버려집니다. 결과는 페이지 0의 포인터 영역을 가리킵니다. 예를 들어 관심 있는 주소(지정된)가 $8765이고 페이지 0의 바이트 위치 $50 및 $51에 있고 X 레지스터의 값이 $30인 경우 입력된 명령은 다음과 같습니다.
LDA ($20.X)
20달러 + 30달러 = 50달러이기 때문입니다.
간접 인덱스 주소 지정
이 주소 지정 모드는 X 레지스터가 아닌 Y 레지스터를 사용합니다. 이 주소 지정 모드를 사용하면 여전히 가리키는 값과 포인터 영역이 있지만 포인터 영역의 내용은 다르게 작동합니다. 포인터 영역의 페이지 0에는 두 개의 연속 바이트가 있어야 합니다. 포인터 영역의 하위 주소가 명령어에 입력됩니다. 포인터 영역에 포함된 이 숫자(바이트 쌍)는 Y 레지스터의 값에 추가되어 실제 포인터를 갖습니다. 예를 들어, 관심 있는 주소(지정된)가 $8765이고 값 6H가 Y 레지스터에 있고 숫자(2바이트)가 주소 50에 있다고 가정합니다. 시간 그리고 51 시간 . $875F + $6 = $8765이므로 2바이트를 합하면 $875F입니다. 입력된 명령은 다음과 같습니다.
LDA ($50),Y
4.9 증가, 감소 및 테스트 BIT 명령어
다음 표는 증가 및 감소 명령어의 작동을 보여줍니다.
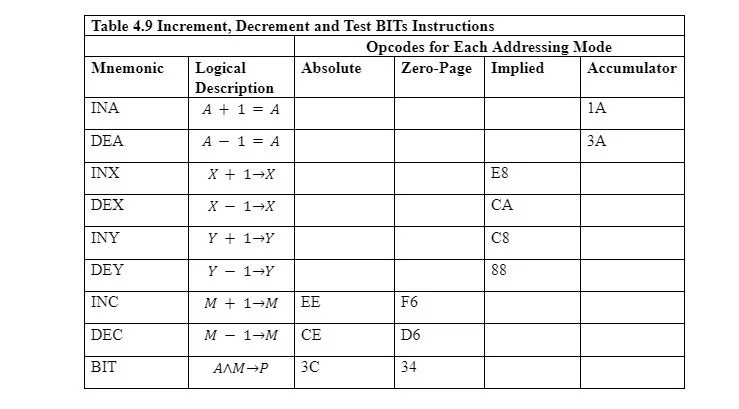
INA와 DEA는 각각 누산기를 증가시키고 감소시킵니다. 이를 누산기 주소 지정이라고 합니다. INX, DEX, INY 및 DEY는 각각 X 및 Y 레지스터용입니다. 피연산자를 사용하지 않습니다. 따라서 묵시적 주소 지정 모드를 사용합니다. 증분은 레지스터 또는 메모리 바이트에 1을 추가하는 것을 의미합니다. 감소는 레지스터나 메모리 바이트에서 1을 빼는 것을 의미합니다.
INC와 DEC는 각각 메모리 바이트를 증가 및 감소시킵니다(레지스터는 아님). 절대 주소 지정 대신 제로 페이지 주소 지정을 사용하는 것은 명령어에 대한 메모리를 절약하는 것입니다. 제로 페이지 주소 지정은 메모리의 명령어에 대한 절대 주소 지정보다 1바이트 적습니다. 그러나 제로 페이지 주소 지정 모드는 페이지 0에만 영향을 미칩니다.
BIT 명령어는 누산기의 8비트를 사용하여 메모리의 바이트 비트를 테스트하지만 둘 다 변경하지 않습니다. 프로세서 상태 레지스터 'P'의 일부 플래그만 설정됩니다. 지정된 메모리 위치의 비트는 누산기의 비트와 논리적으로 AND됩니다. 그런 다음 다음 상태 비트가 설정됩니다.
- 비트 7이자 상태 레지스터의 마지막 비트(왼쪽)인 N은 ANDing 이전에 메모리 위치의 비트 7을 수신합니다.
- 상태 레지스터의 비트 6인 V는 ANDing 이전에 메모리 위치의 비트 6을 수신합니다.
- AND의 결과가 0(00000000)이면 상태 레지스터의 Z 플래그가 설정됩니다(1로 설정됨). 2 ). 그렇지 않으면 클리어됩니다(0이 됩니다).
4.10 비교 명령어
6502 µP의 비교 명령 니모닉은 CMP, CPX 및 CPY입니다. 각 비교 후에 프로세서 상태 레지스터 'P'의 N, Z 및 C 플래그가 영향을 받습니다. 결과가 음수일 때 N 플래그가 설정됩니다(1로 만들어짐). 결과가 0(000000002)일 때 Z 플래그가 설정됩니다(1로 만들어짐). C 플래그는 8번째 비트에서 9번째 비트로 캐리가 있을 때 설정됩니다(1로 만들어짐). 다음 표는 자세한 설명을 제공합니다.
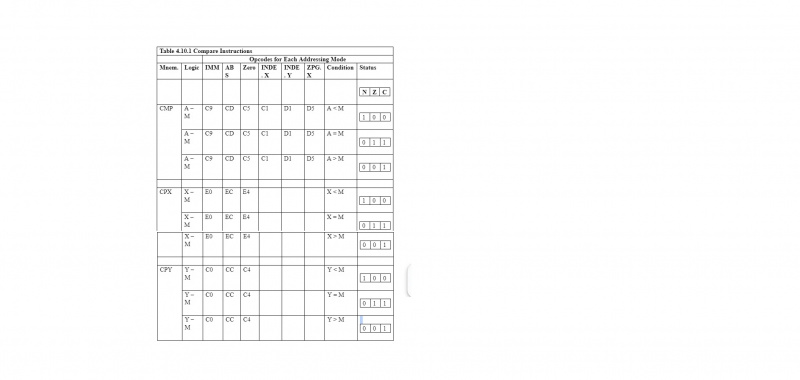
'보다 크다'는 뜻이다. 이를 통해 비교 테이블은 설명이 필요합니다.
4.11 점프 및 분기 명령어
다음 표에는 점프 및 분기 명령이 요약되어 있습니다.
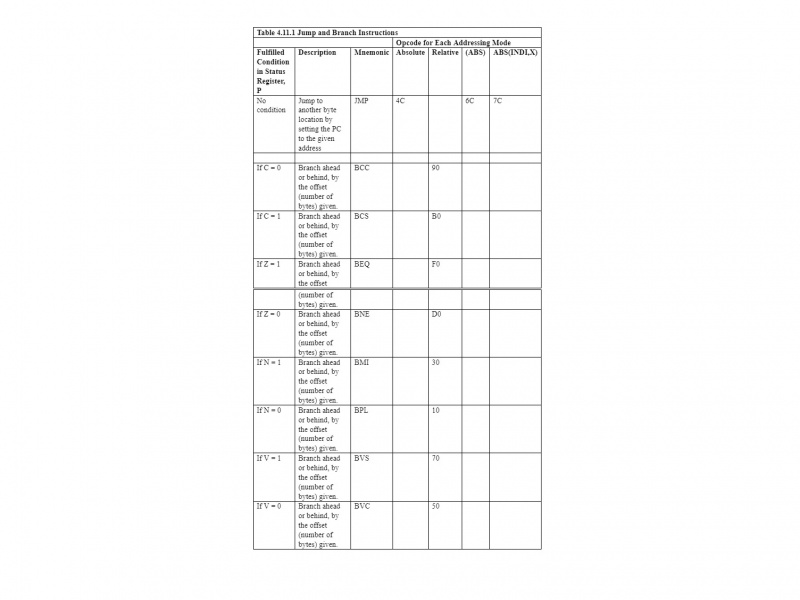
JMP 명령어는 절대 주소 지정과 간접 주소 지정을 사용합니다. 표의 나머지 지침은 분기 지침입니다. 6502 µP에서는 상대 주소 지정만 사용합니다. 따라서 테이블을 왼쪽에서 오른쪽으로, 위에서 아래로 읽으면 설명이 필요 없게 됩니다.
분기는 지정된 주소에서 -128~+127바이트 내의 주소에만 적용할 수 있습니다. 이것은 상대 주소 지정입니다. JMP 및 분기 명령어 모두 프로그램 카운터(PC)에 직접적인 영향을 미칩니다. 6502 µP는 절대 주소로의 분기를 허용하지 않지만 점프는 절대 주소 지정을 수행할 수 있습니다. JMP 명령어는 분기 명령어가 아닙니다.
메모: 상대 주소 지정은 분기 명령어에만 사용됩니다.
4.12 스택 영역
서브루틴은 두 숫자를 더하거나 두 숫자를 빼는 이전의 짧은 프로그램 중 하나와 같습니다. 메모리의 스택 영역은 $0100부터 $01FF까지 시작합니다. 이 영역을 간단히 스택이라고 합니다. 마이크로프로세서가 서브루틴 명령어(JSR – 다음 설명 참조)로 점프를 실행할 때 완료되면 어디로 돌아갈지 알아야 합니다. 6502 µP는 이 정보(반환 주소)를 $0100부터 $01FF(스택 영역)까지의 낮은 메모리에 보관하고 마이크로프로세서에서 'S'인 스택 포인터 레지스터 콘텐츠를 마지막 반환 주소에 대한 포인터(9비트)로 사용합니다. 메모리의 1페이지($0100~$01FF)에 저장됩니다. 스택은 $01FF부터 작아지며 최대 128레벨 깊이까지 서브루틴을 중첩할 수 있습니다.
스택 포인터의 또 다른 용도는 인터럽트를 처리하는 것입니다. 6502 µP에는 IRQ 및 NMI라는 라벨이 붙은 핀이 있습니다. 일부 작은 전기 신호가 이러한 핀에 적용되어 6502 µP가 한 프로그램 실행을 중단하고 다른 프로그램 실행을 시작하게 할 수 있습니다. 이 경우 첫 번째 프로그램이 중단됩니다. 서브루틴과 마찬가지로 인터럽트 코드 세그먼트도 중첩될 수 있습니다. 인터럽트 처리는 다음 장에서 논의됩니다.
메모 : 스택 포인터는 $0100부터 $01FF까지의 위치를 지정할 때 하위 바이트 주소로 8비트를 갖습니다. 00000001의 상위 바이트 2 가정된다.
다음 표는 스택 포인터 'S'를 A, X, Y 및 P 레지스터와 메모리의 스택 영역과 연결하는 지침을 제공합니다.
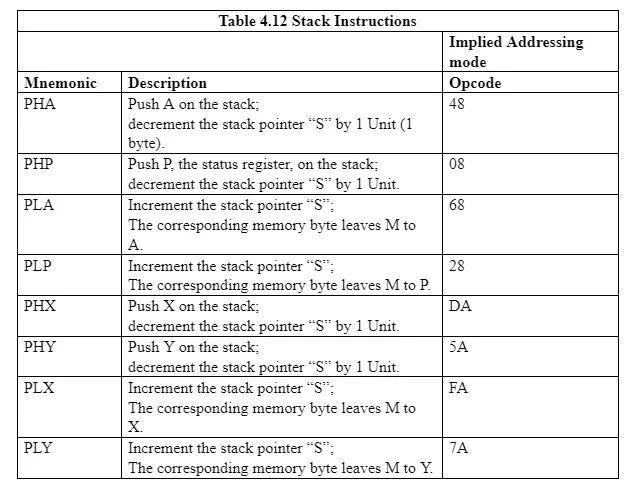
4.13 서브루틴 호출 및 복귀
서브루틴은 특정 목적을 달성하기 위한 일련의 명령입니다. 이전 덧셈이나 뺄셈 프로그램은 매우 짧은 서브루틴입니다. 서브루틴은 때때로 루틴이라고 불리기도 합니다. 서브루틴을 호출하는 명령은 다음과 같습니다.
JSR : 서브루틴으로 점프
서브루틴에서 복귀하는 명령은 다음과 같습니다.
RTS : 서브루틴에서 복귀
마이크로프로세서는 메모리에 있는 명령을 하나씩 계속해서 실행하는 경향이 있습니다. 마이크로프로세서가 현재 코드 세그먼트를 실행 중이고 이미 실행되었을 수 있는 코드 세그먼트를 실행하기 위해 점프(JMP) 명령을 만났다고 가정합니다. 이는 뒤에 있는 코드 세그먼트를 실행하고 현재 코드 세그먼트를 다시 실행하고 아래에서 계속될 때까지 뒤에 있는 코드 세그먼트 뒤에 있는 모든 코드 세그먼트(명령어)를 계속 실행합니다. JMP는 다음 명령어를 스택에 푸시하지 않습니다.
JMP와 달리 JSR은 PC(프로그램 카운터)에서 스택으로 다음 명령의 주소를 푸시합니다. 이 주소의 스택 위치는 스택 포인터 'S'에 위치합니다. 서브루틴에서 RTS 명령어가 발견(실행)되면 스택에 푸시된 주소가 스택에서 풀려나고 프로그램은 서브루틴 호출 직전의 다음 명령어 주소인 풀오프 주소에서 다시 시작됩니다. 스택에서 제거된 마지막 주소는 프로그램 카운터로 전송됩니다. 다음 표에는 JSR 및 RTS 지침의 기술적인 세부 정보가 나와 있습니다.

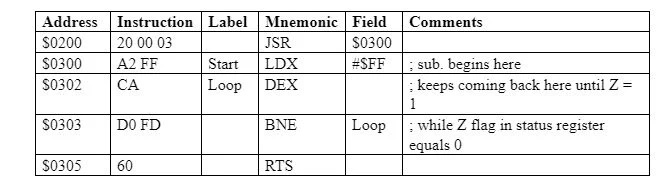
JSR 및 RTS 사용에 대한 다음 그림을 참조하세요.
4.14 카운트다운 루프 예제
다음 서브루틴은 $FF에서 $00까지 카운트다운합니다(총 256개). 10 개수):
LDX 시작 #$FF ; $FF = 255로 X 로드
루프 DEX ; 엑스 = 엑스 - 1
BNE 루프 ; X가 0이 아니면 루프로 이동
RTS ; 반품
각 줄에는 주석이 있습니다. 주석은 실행을 위해 메모리에 저장되지 않습니다. 프로그램을 실행(실행)을 위해 메모리에 있는 상태로 변환하는 어셈블러(번역기)는 항상 주석을 제거합니다. 주석은 ';'으로 시작됩니다. . 이 프로그램의 '시작'과 '루프'를 레이블이라고 합니다. 레이블은 명령어 주소를 식별합니다(이름). 명령어가 단일 바이트 명령어(암시적 주소 지정)인 경우 레이블은 해당 명령어의 주소입니다. 명령어가 멀티바이트 명령어인 경우 레이블은 멀티바이트 명령어의 첫 번째 바이트를 식별합니다. 이 프로그램의 첫 번째 명령어는 2바이트로 구성됩니다. $0300 주소에서 시작한다고 가정하면 $0300 주소는 프로그램에서 'start' 아래로 대체될 수 있습니다. 두 번째 명령어(DEX)는 단일 바이트 명령어이며 $0302 주소에 있어야 합니다. 이는 $0302 주소가 프로그램에서 '루프'로 대체될 수 있음을 의미하며 실제로 'BNE 루프'에서도 마찬가지입니다.
'BNE 루프'는 상태 레지스터의 Z 플래그가 0일 때 주어진 주소로 분기하는 것을 의미합니다. A 또는 X 또는 Y 레지스터의 값이 00000000일 때 2 , 마지막 작업으로 인해 Z 플래그는 1(설정)입니다. 따라서 0(1이 아님)인 동안 프로그램의 두 번째 및 세 번째 명령어가 해당 순서로 반복됩니다. 반복되는 각 시퀀스에서 X 레지스터의 값(정수)은 1씩 감소합니다. DEX는 X = X – 1을 의미합니다. X 레지스터의 값이 $00 = 00000000인 경우 2 , Z는 1이 됩니다. 이 시점에서는 두 명령어가 더 이상 반복되지 않습니다. 프로그램의 마지막 RTS 명령어(단일 바이트 명령어(묵시적 주소 지정))는 서브루틴에서 반환됩니다. 이 명령어의 효과는 서브루틴 호출 전에 실행될 코드에 대한 스택의 프로그램 카운터 주소를 만들고 프로그램 카운터(PC)로 돌아가는 것입니다. 이 주소는 서브루틴이 호출되기 전에 실행될 명령어의 주소입니다.
메모: 6502 µP용 어셈블리 언어 프로그램을 작성할 때 레이블만 줄의 시작 부분에서 시작해야 합니다. 다른 줄 코드는 오른쪽으로 한 칸 이상 이동해야 합니다.
서브루틴 호출
이전 레이블이 차지하는 메모리 공간을 무시하고 프로그램은 $0300에서 $0305까지 메모리(RAM)에서 6바이트의 연속 위치를 사용합니다. 이 경우 프로그램은 다음과 같습니다.
LDX #$FF ; $FF = 255로 X 로드
덱스 ; 엑스 = 엑스 – 1
BNE $0302 ; X가 0이 아니면 루프로 이동
RTS ; 반품
메모리의 $0200 주소부터 시작하여 서브루틴을 호출할 수 있습니다. 호출 지침은 다음과 같습니다.
JSR 시작 ; 시작은 주소 $0300입니다. 즉, JSR $0300입니다.
텍스트 편집기 파일에 올바르게 작성된 서브루틴 및 해당 호출은 다음과 같습니다.
LDX 시작 #$FF; $FF = 255로 X 로드
루프 DEX ; 엑스 = 엑스 - 1
BNE 루프 ; X가 0이 아니면 루프로 이동
RTS ; 반품
JSR 시작: $0300부터 시작하는 루틴으로 점프
이제 하나의 긴 프로그램에는 여러 개의 서브루틴이 있을 수 있습니다. 그들 모두는 'start'라는 이름을 가질 수 없습니다. 이름이 달라야 합니다. 사실, 그들 중 누구도 'start'라는 이름을 갖고 있지 않을 수도 있습니다. 여기서는 교육상의 이유로 '시작'이 사용되었습니다.
4.15 프로그램 번역
프로그램을 번역하거나 조립하는 것은 같은 의미입니다. 다음 프로그램을 고려해보세요:
start LDX #$FF : $FF = 255로 X를 로드합니다.
루프 DEX : X = X – 1
BNE 루프: X가 0이 아니면 루프로 이동
RTS : 반환
JSR 시작: $0300부터 시작하는 루틴으로 점프
이전에 작성한 프로그램입니다. 이는 서브루틴, 시작 및 서브루틴 호출로 구성됩니다. 프로그램은 255부터 카운트다운됩니다. 10 0으로 10 . 프로그램은 사용자 시작 주소 $0200(RAM)에서 시작됩니다. 프로그램은 텍스트 편집기에 입력되어 디스크에 저장됩니다. 여기에는 'sample.asm'과 같은 이름이 있습니다. 여기서 'sample'은 프로그래머가 선택한 이름이지만 어셈블리 언어의 '.asm' 확장자는 파일 이름과 연결되어야 합니다.
어셈블된 프로그램은 어셈블러라고 하는 다른 프로그램에 의해 생성됩니다. 어셈블러는 6502 µP 제조업체 또는 타사에서 제공합니다. 어셈블러는 프로그램이 실행(실행)될 때 메모리(RAM)에 있는 방식으로 프로그램을 재현합니다.
JSR 명령어는 $0200 주소에서 시작하고 서브루틴은 $0300 주소에서 시작한다고 가정합니다. 어셈블러는 모든 주석과 공백을 제거합니다. 주석과 공백은 항상 부족한 메모리를 낭비합니다. 이전 서브루틴 코드 세그먼트와 서브루틴 호출 사이에 있을 수 있는 빈 줄은 공백의 예입니다. 조립된 파일은 여전히 디스크에 저장되며 'sample.exe'와 같은 이름이 지정됩니다. '샘플'은 프로그래머가 선택한 이름이지만 '.exe' 확장자는 실행 파일임을 나타내기 위해 있어야 합니다.
조립된 프로그램은 다음과 같이 문서화할 수 있습니다.
이런 문서를 제작하는 것은 손으로 조립한다고 합니다. 참고로 본 문서의 설명은 메모리(실행용)에 나타나지 않습니다. 표의 주소 열은 메모리에 있는 명령어의 시작 주소를 나타냅니다. '20 03 00'으로 코딩될 것으로 예상되는 'JSR $0300'인 'JSR start'는 실제로는 '20 00 03'으로 코딩되며 하위 메모리 바이트 주소가 메모리의 하위 바이트를 가져오고 더 높은 메모리 바이트 주소는 메모리에서 더 높은 바이트를 취합니다 – 리틀 엔디안. JSR의 opcode는 20입니다. 16 .
BNE와 같은 분기 명령어에 대한 오프셋은 128 범위의 2의 보수입니다. 10 + 127까지 10 . 따라서 'BNE 루프'는 'BNE -1'을 의미합니다. 10 ” 이는 실제로 FF의 코드 형식에서는 “D0 FF”입니다. 16 2진수에서 = 11111111로 쓰여지는 2의 보수에서는 -1입니다. 어셈블러 프로그램은 레이블과 필드를 실제 16진수 숫자로 바꿉니다(16진수는 4비트로 그룹화된 2진수입니다). 각 명령어가 시작되는 실제 주소가 실제로 포함됩니다.
메모: 'JSR 시작' 명령은 프로그램 카운터의 현재 내용(상위 및 하위 바이트)을 두 번(상위 바이트에 대해 한 번, 하위 바이트에 대해 한 번) 감소되는 스택 포인터를 사용하여 스택으로 보내는 더 짧은 명령으로 대체됩니다. 그런 다음 $0300 주소로 PC를 다시 로드합니다. 이제 스택 포인터는 $01FF로 초기화되었다고 가정하여 $00FD를 가리킵니다.
또한 RTS 명령어는 스택 포인터 'S'를 두 번(낮은 바이트에 대해 한 번, 높은 바이트에 대해 한 번) 증가시키고 해당 2바이트의 주소를 스택 포인터에서 PC로 가져오는 더 짧은 명령어로 대체됩니다. 다음 지시.
메모: 라벨 텍스트는 8자를 초과할 수 없습니다.
'BNE 루프'는 상대 주소 지정을 사용합니다. -3을 더한다는 뜻이다. 10 $0305의 다음 프로그램 카운터 내용으로 이동합니다. 'BNE 루프'의 바이트는 'D0 FD'입니다. 여기서 FD는 -3의 2의 보수입니다. 10 .
참고: 이 장에서는 6502 µP에 대한 모든 지침을 제시하지 않습니다. 모든 지침과 세부 정보는 'SY6500 8비트 마이크로프로세서 제품군'이라는 제목의 문서에서 확인할 수 있습니다. 인터넷에서 무료로 사용할 수 있는 이 문서에 대한 '6502.pdf'라는 이름의 PDF 파일이 있습니다. 이 문서에 설명된 6502 µP는 65C02입니다.
4.16 인터럽트
Commodore 64의 외부(수직 표면) 포트에 연결된 모든 장치의 신호는 6502 마이크로프로세서에 도달하기 전에 CIA 1 또는 CIA 2 회로(IC)를 통과해야 합니다. 6502 µP 데이터 버스의 신호는 외부 장치에 도달하기 전에 CIA 1 또는 CIA 2 칩을 통과해야 합니다. CIA는 Complex Interface Adapter의 약자입니다. 그림 4.1 “Commodore_64 마더보드의 블록 다이어그램”에서 블록 입/출력 장치는 CIA 1과 CIA 2를 나타냅니다. 프로그램이 실행 중일 때 계속하기 전에 다른 코드 부분을 실행하기 위해 프로그램이 중단될 수 있습니다. 하드웨어 중단과 소프트웨어 중단이 있습니다. 하드웨어 중단을 위해 6502 µP에는 2개의 입력 신호 핀이 있습니다. 이 핀의 이름은 다음과 같습니다. IRQ 그리고 NMI . 이는 µP 데이터 라인이 아닙니다. µP의 데이터 라인은 D7, D6, D5, D4, D3, D2, D1 및 D0입니다. 최하위 비트는 D0이고 최상위 비트는 D7입니다.
IRQ Interrupt ReQuest 'active' low를 나타냅니다. µP에 대한 이 입력 라인은 일반적으로 약 5V로 높습니다. 약 0V로 떨어지면 이는 µP에 신호를 보내는 인터럽트 요청입니다. 요청이 승인되자마자 라인은 다시 높아집니다. 인터럽트 요청을 승인한다는 것은 µP가 인터럽트를 처리하는 코드(서브루틴)로 분기한다는 것을 의미합니다.
NMI Non-Maskable Interrupt 'active' low를 나타냅니다. 코드는 IRQ 처형되고 있다 NMI 낮아질 수 있습니다. 이 경우, NMI 처리됩니다(자체 코드가 실행됨). 그 후의 코드는 IRQ 계속됩니다. 코드 다음에 IRQ 종료되면 기본 프로그램 코드가 계속됩니다. 그건, NMI 방해하다 IRQ 매니저. 에 대한 신호 NMI µP가 유휴 상태이고 아무것도 처리하지 않거나 메인 프로그램을 실행하지 않는 경우에도 µP에 여전히 주어질 수 있습니다.
메모: 실제로는 높은 곳에서 낮은 곳으로의 전환입니다. NMI , 그건 NMI 신호 – 이에 대해서는 나중에 자세히 설명합니다. IRQ 일반적으로 CIA 1과 NMI 일반적으로 CIA 2에서 나옵니다. NMI Non-Maskable Interrupt의 약자로, Non-Maskable Interrupt로 간주할 수 있습니다.
인터럽트 처리
요청의 출처인지 여부 IRQ 또는 NMI , 현재 명령이 완료되어야 합니다. 6502에는 A, X, Y 레지스터만 있습니다. 서브루틴이 작동하는 동안 이 세 개의 레지스터를 함께 사용할 수 있습니다. 인터럽트 핸들러는 그렇게 보이지는 않지만 여전히 서브루틴입니다. 현재 명령어가 완료된 후 65C02 µP에 대한 A, X 및 Y 레지스터의 내용이 스택에 저장됩니다. 프로그램 카운터의 다음 명령어 주소도 스택으로 전송됩니다. 그런 다음 µP는 인터럽트용 코드로 분기됩니다. 그런 다음 A, X, Y 레지스터의 내용이 전송된 역순으로 스택에서 복원됩니다.
인터럽트 코딩 예제
단순화를 위해 µP의 루틴이 다음과 같다고 가정합니다. IRQ 인터럽트는 $01과 $02라는 숫자를 더하고 $03의 결과를 $0400의 메모리 주소에 저장하는 것입니다. 코드는 다음과 같습니다
ISR PHA
PHX
PHY
;
LDA #$01
ADC #$02
가격은 $0400입니다
;
주름
PLX
PLA
RTI
ISR은 레이블이며 PHA 명령어가 있는 메모리 주소를 식별합니다. ISR은 인터럽트 서비스 루틴을 의미합니다. PHA, PHX 및 PHY는 중단 직전에 실행 중인 모든 코드(프로그램)에 필요할 것이라는 희망을 가지고 A, X 및 Y 레지스터의 내용을 스택에 보냅니다. 다음 세 가지 명령어는 인터럽트 핸들러의 핵심을 형성합니다. PLY, PLX 및 PLA 명령어는 이 순서대로 이루어져야 하며 Y, X 및 A 레지스터의 내용을 다시 가져옵니다. 마지막 명령어인 RTI(피연산자 없음)는 중단 전에 실행 중이던 모든 코드(프로그램)에 대해 실행 연속을 반환합니다. RTI는 실행 중인 코드의 다음 명령어 주소를 스택에서 프로그램 카운터로 다시 가져옵니다. RTI는 인터럽트에서 복귀를 의미합니다. 이것으로 인터럽트 처리(서브루틴)은 끝났습니다.
소프트웨어 인터럽트
6502 µP에 대한 소프트웨어 인터럽트를 갖는 주요 방법은 BRK 묵시적 주소 명령어를 사용하는 것입니다. 메인 프로그램이 실행 중이고 BRK 명령을 만났다고 가정합니다. 그 시점부터 현재 명령어가 완료되면 PC의 다음 명령어 주소가 스택으로 전송되어야 합니다. 소프트웨어 명령어를 처리하는 서브루틴은 'next'라고 호출되어야 합니다. 이 인터럽트 서브루틴은 A, X, Y 레지스터 내용을 스택에 푸시해야 합니다. 서브루틴의 핵심이 실행된 후, 완성된 서브루틴에 의해 A, X, Y 레지스터의 내용이 스택에서 해당 레지스터로 풀백되어야 합니다. 루틴의 마지막 문은 RTI입니다. 또한 RTI로 인해 PC 콘텐츠가 스택에서 PC로 자동으로 풀백됩니다.
서브루틴과 인터럽트 서비스 루틴의 비교 및 대조
다음 표에서는 서브루틴과 인터럽트 서비스 루틴을 비교하고 대조합니다.

4.17 6502 주요 주소 지정 모드 요약
6502의 각 명령어는 1바이트이고 그 뒤에 0개 이상의 피연산자가 옵니다.
즉시 주소 지정 모드
즉시 주소 지정 모드에서는 피연산자 뒤에 값이 있고 메모리 주소는 없습니다. 값 앞에는 #이 와야 합니다. 값이 16진수인 경우 '#' 뒤에 '$'가 와야 합니다. 65C02에 대한 즉시 주소 지정 명령은 ADC, AND, BIT, CMP, CPX, CPY, EOR, LDA, LDX, LDY, ORA, SBC입니다. 이 장에서 설명되지 않은 여기에 나열된 지침을 사용하는 방법을 알아보려면 독자는 65C02 µP에 대한 설명서를 참조해야 합니다. 예제 지침은 다음과 같습니다.
LDA #$77
절대 주소 지정 모드
절대 주소 지정 모드에는 피연산자가 하나 있습니다. 이 피연산자는 메모리에 있는 값의 주소입니다(보통 16진수 또는 레이블). 64K가 있습니다 10 = 65,536 10 6502 µP의 메모리 주소입니다. 일반적으로 1바이트 값은 이러한 주소 중 하나에 있습니다. 65C02의 절대 주소 지정 명령은 ADC, AND, ASL, BIT, CMP, CPX, CPY, DEC, EOR, INC, JMP, JSR, LDA, LDX, LDY, LSR, ORA, ROL, ROR, SBC, STA입니다. , STX, STY, STZ, TRB, TSB. 독자는 여기에 나열된 지침을 사용하는 방법과 이 장에서 설명하지 않은 나머지 주소 지정 모드에 대해 알아보려면 65C02 µP에 대한 설명서를 참조해야 합니다. 예제 지침은 다음과 같습니다.
가격은 $1234입니다
묵시적 주소 지정 모드
묵시적 주소 지정 모드에는 피연산자가 없습니다. 관련된 모든 µP 레지스터는 명령어에 의해 암시됩니다. 65C02에 대한 암시적 주소 지정 지침은 BRK, CLC, CLD, CLI, CLV, DEX, DEY, INX, INY, NOP, PHA, PHP, PHX, PHY, PLA, PLP, PLX, PLY, RTI, RTS, SEC입니다. , SED, SEI, 세금, TAY, TSX, TXA, TXS, TYA. 예제 지침은 다음과 같습니다.
DEX : X 레지스터를 1단위 감소시킵니다.
상대 주소 지정 모드
상대 주소 지정 모드는 분기 명령어만 처리합니다. 상대 주소 지정 모드에는 피연산자가 하나만 있습니다. -128의 값입니다. 10 +127까지 10 . 이 값을 오프셋이라고 합니다. 부호에 따라 이 값은 프로그램 카운터의 다음 명령어에 더해지거나 빼어 의도된 다음 명령어의 주소가 됩니다. 상대 주소 모드 명령어는 BCC, BCS, BEQ, BMI, BNE, BPL, BRA, BVC, BVS입니다. 지침 예는 다음과 같습니다.
BNE $7F : (상태 레지스터에서 Z = 0이면 분기, P)
현재 프로그램 카운터(실행할 주소)에 127을 추가하고 해당 주소에서 명령어 실행을 시작합니다. 비슷하게:
BEQ $F9 : (Z = : 상태 레지스터에서 P인 경우 분기)
현재 프로그램 카운터에 -7을 추가하고 새 프로그램 카운터 주소에서 실행을 시작합니다. 피연산자는 2의 보수입니다.
절대 인덱스 주소 지정
절대 인덱스 주소 지정에서는 X 또는 Y 레지스터의 내용이 주어진 절대 주소($0000부터 $FFFF까지, 즉 0부터)에 추가됩니다. 10 65536까지 10 ) 실제 주소를 알고 싶습니다. 이렇게 주어진 절대 주소를 기본 주소라고 합니다. X 레지스터를 사용하는 경우 어셈블리 명령은 다음과 같습니다.
LDA $C453,X
Y 레지스터를 사용하면 다음과 같습니다.
LDA $C453,Y
X 또는 Y 레지스터의 값은 카운트 또는 인덱스 값이라고 하며 $00(0 10 ) ~ $FF(250) 10 ). 오프셋이라고 부르지 않습니다.
절대 인덱스 주소 지정 명령어는 ADC, AND, ASL(X만 해당), BIT(누산기와 메모리 포함, X만 포함), CMP, DEC(메모리 및 X만 해당), EOR, INC(메모리 및 X만 해당), LDA입니다. , LDX, LDY, LSR(X만), ORA, ROL(X만), ROR(X만), SBC, STA, STZ(X만).
절대 간접 주소 지정
이는 점프 명령에만 사용됩니다. 이를 통해 주어진 절대 주소에는 포인터 주소가 있습니다. 포인터 주소는 2바이트로 구성됩니다. 2바이트 포인터는 메모리의 대상 바이트 값을 가리킵니다(주소). 따라서 어셈블리 언어 명령어는 다음과 같습니다.
JMP ($3456)
괄호를 사용하면 $13은 $3456의 주소 위치에 있고 $EB는 $3457(= $3456 + 1)의 주소 위치에 있습니다. 그런 다음 대상 주소는 $13EB이고 $13EB가 포인터입니다. 절대값 $3456은 명령에서 괄호 안에 표시됩니다. 여기서 34는 하위 바이트이고 56은 상위 바이트입니다.
4.18 6502 µP 어셈블리 언어로 문자열 만들기
다음 장에서 설명하는 것처럼 메모리에 파일을 생성한 후 해당 파일을 디스크에 저장할 수 있습니다. 파일에 이름을 지정해야 합니다. 이름은 문자열의 예입니다. 프로그래밍에는 문자열의 다른 예가 많이 있습니다.
ASCII 코드 문자열을 생성하는 두 가지 주요 방법이 있습니다. 두 가지 방법 모두 모든 ASCII 코드(문자)는 메모리에서 연속적인 바이트 위치를 차지합니다. 한 가지 방법으로 이 바이트 시퀀스 앞에는 시퀀스(문자열)의 길이(문자 수)인 정수 바이트가 옵니다. 다른 방법으로는 문자 시퀀스가 00인 Null 바이트로 이어집니다(즉시 뒤따릅니다). 16 , 즉 $00입니다. 문자열의 길이(문자 수)는 이와 달리 표시되지 않습니다. Null 문자는 첫 번째 방법으로 사용되지 않습니다.
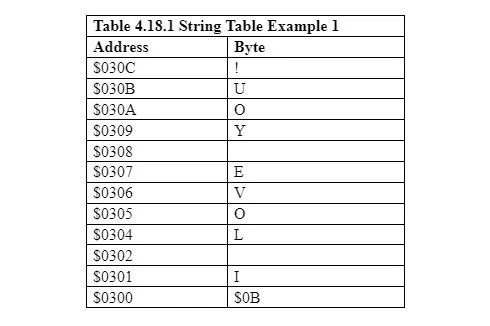
예를 들어, “사랑해요!”를 생각해 보세요. 따옴표가 없는 문자열입니다. 여기서 길이는 11입니다. 공백은 하나의 ASCII 바이트(문자)로 계산됩니다. 문자열이 첫 번째 문자가 주소 $0300에 있는 메모리에 배치되어야 한다고 가정합니다.
다음 표는 첫 번째 바이트가 11일 때의 문자열 메모리 설정을 보여줍니다. 10 = 0B 16 :
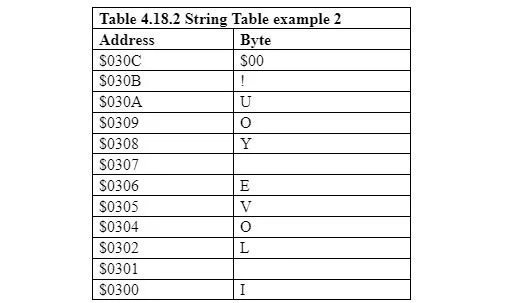
다음 표는 첫 번째 바이트가 'I'이고 마지막 바이트가 Null($00)일 때의 문자열 메모리 설정을 보여줍니다.
다음 명령을 사용하여 문자열 생성을 시작할 수 있습니다.
가격은 $0300입니다
첫 번째 바이트가 $0300 주소 위치로 전송될 누산기에 있다고 가정합니다. 이 명령은 두 경우 모두(두 가지 유형의 문자열 모두)에 적용됩니다.
메모리 셀의 모든 문자를 하나씩 맞춘 후 루프를 사용하여 문자열을 읽을 수 있습니다. 첫 번째 경우에는 길이 뒤의 문자 수를 읽습니다. 두 번째 경우에는 'I'부터 'Null'인 Null 문자를 만날 때까지 문자를 읽습니다.
4.19 6502 µP 어셈블리 언어로 배열 만들기
단일 바이트 정수 배열은 정수가 포함된 연속적인 메모리 바이트 위치로 구성됩니다. 그런 다음 첫 번째 정수의 위치를 가리키는 포인터가 있습니다. 따라서 정수 배열은 포인터와 일련의 위치라는 두 부분으로 구성됩니다.
문자열 배열의 경우 각 문자열은 메모리의 다른 위치에 있을 수 있습니다. 그런 다음 각 포인터가 각 문자열의 첫 번째 위치를 가리키는 포인터가 있는 연속적인 메모리 위치가 있습니다. 이 경우 포인터는 2바이트로 구성됩니다. 문자열이 해당 길이로 시작하는 경우 해당 포인터는 해당 길이의 위치를 가리킵니다. 문자열이 해당 길이로 시작하지 않고 널 문자로 끝나는 경우 해당 포인터는 문자열의 첫 번째 문자 위치를 가리킵니다. 그리고 연속된 포인터 중 첫 번째 포인터의 하위 바이트 주소를 가리키는 포인터가 있습니다. 따라서 문자열 배열은 메모리의 서로 다른 위치에 있는 문자열, 해당 연속 포인터, 연속 포인터의 첫 번째 포인터에 대한 포인터의 세 부분으로 구성됩니다.
4.20 문제점
독자는 다음 장으로 넘어가기 전에 한 장의 모든 문제를 해결하는 것이 좋습니다.
- 6502 µP에 대해 $0200부터 시작하고 부호 없는 숫자 2A94를 추가하는 어셈블리 언어 프로그램을 작성하세요. 시간 (추가) 2ABF에 시간 (Agend). 입력과 출력이 메모리에 있도록 하세요. 또한, 조립된 프로그램 문서를 직접 제작합니다.
- 6502 µP에 대해 $0200부터 시작하고 부호 없는 숫자 1569를 빼는 어셈블리 언어 프로그램을 작성하세요. 시간 (감수) 2ABF에서 시간 (피감수). 입력과 출력이 메모리에 있도록 하세요. 또한, 조립된 프로그램 문서를 직접 제작합니다.
- 루프를 사용하여 $00부터 $09까지 계산하는 6502 µP용 어셈블리 언어 프로그램을 작성하세요. 프로그램은 $0200부터 시작해야 합니다. 또한, 조립된 프로그램 문서를 직접 제작합니다.
- 6502 µP에 대해 $0200부터 시작하는 어셈블리 언어 프로그램을 작성하세요. 이 프로그램에는 두 개의 서브루틴이 있습니다. 첫 번째 서브루틴은 부호 없는 숫자 0203을 추가합니다. 시간 (가수) 및 0102H(가수). 두 번째 서브루틴은 0305H인 첫 번째 서브루틴의 합계를 0006에 더합니다. 시간 (Agend). 최종 결과는 메모리에 저장됩니다. FSTSUB인 첫 번째 서브루틴과 SECSUB인 두 번째 서브루틴을 호출합니다. 입력과 출력이 메모리에 있도록 하세요. 또한 전체 프로그램에 대해 조립된 프로그램 문서를 수작업으로 제작합니다.
- 이를 감안할 때 IRQ 핸들러는 누산기에서 $02를 $01에 코어 처리로 추가합니다. NMI 발행되고 핵심 처리 NMI 누산기에서 $05를 $04에 추가하고 해당 호출을 포함하여 두 핸들러에 대한 어셈블리 언어를 작성합니다. 에 대한 호출 IRQ 핸들러는 $0200의 주소에 있어야 합니다. 그만큼 IRQ 핸들러는 $0300의 주소에서 시작해야 합니다. 그만큼 NMI 핸들러는 $0400의 주소에서 시작해야 합니다. 결과는 IRQ 핸들러는 $0500의 주소에 있어야 하며, 그 결과는 NMI 핸들러는 $0501 주소에 있어야 합니다.
- 65C02 컴퓨터에서 BRK 명령을 사용하여 소프트웨어 인터럽트를 생성하는 방법을 간략하게 설명하십시오.
- 일반 서브루틴과 인터럽트 서비스 루틴을 비교하고 대조하는 표를 생성하십시오.
- 어셈블리 언어 명령어 예제를 통해 65C02 µP의 주요 주소 지정 모드를 간략하게 설명합니다.
- a) '사랑해!'를 입력하는 6502 기계어 프로그램을 작성하세요. 문자열 길이로 $0300 주소부터 시작하는 메모리의 ASCII 코드 문자열입니다. 프로그램은 $0200 주소에서 시작해야 합니다. 일부 서브루틴을 통해 누산기에서 각 문자가 전송된다는 가정하에 하나씩 누산기에서 각 문자를 얻습니다. 또한 프로그램을 손으로 조립하십시오. ('I love you!'에 대한 ASCII 코드를 알아야 하는 경우 다음과 같습니다. 'I':49 16 , 공간 : 20 16 , 'l': 6C 16 , 'o':6F 16 , 'in':76 16 , 'e':65, 'y':79 16 , 'in':75 16 , 그리고 '!':21 16 (참고: 각 코드는 1바이트를 차지합니다.)
b) '사랑해!'를 입력하는 6502 기계어 프로그램을 작성하세요. 문자열 길이가 없는 $0300 주소에서 시작하지만 00으로 끝나는 메모리의 ASCII 코드 문자열 16 . 프로그램은 $0200 주소에서 시작해야 합니다. 일부 서브루틴에 의해 하나씩 거기로 전송된다고 가정하고 누산기에서 각 문자를 얻습니다. 또한 프로그램을 손으로 조립하십시오.