프로그래머, 코더 및 개발자는 Python 스크립트를 사용하여 방법을 자동화하여 반복 작업을 수행함으로써 중요한 시간과 노력을 절약할 수 있습니다. Python은 Java와 마찬가지로 프로세스 자동화에 적합한 컴퓨터 언어입니다. 다른 언어에 비해 상대적으로 배우기 쉽습니다. 또한 특정 작업을 자동화하기 위한 크고 활발한 커뮤니티와 내장 라이브러리가 있습니다.
파이썬 설치
작업 자동화를 시작하기 전에 컴퓨터나 시스템에 Python을 설치하십시오. Python을 설치하려면 먼저 공식 Python 웹사이트를 방문해야 합니다. 설치 중에 시스템의 PATH에 Python을 추가했는지 확인하세요.
- IDE 또는 텍스트 편집기 선택
Python 스크립트를 작성하는 데 모든 텍스트 편집기를 사용할 수 있습니다. 하지만 PyCharm, Visual Studio Code, Jupyter Notebook을 포함한 통합 개발 환경(IDE)은 구문 강조 및 디버깅과 같은 도구를 사용하여 프로세스를 개선할 수 있습니다. 그러나 이 기사에서는 Notepad++를 사용합니다.
- 자동화해야 하는 작업 결정
여기에는 대량 이메일 보내기, 보고서 작성, 파일 다운로드, 백업 만들기 등이 포함될 수 있습니다.
- 라이브러리 및 기능 조사
하위 작업을 자동화할 수 있는 함수와 라이브러리를 살펴보세요.
- Python으로 스크립트 작성
여기에서 모든 조각을 모아 완전한 작업 스크립트를 만듭니다.
- 일
스프레드시트에 저장된 데이터에서 보고서 생성을 자동화합니다.
- 파이썬 스크립트
Python 스크립트를 사용하여 스프레드시트에서 데이터를 읽고 PDF, HTML 또는 CSV와 같은 다양한 형식으로 보고서를 생성할 수 있습니다. 또한 스크립트를 사용하여 이메일이나 Slack을 통해 이해관계자에게 보고서를 자동으로 배포할 수 있습니다.
스프레드시트 데이터를 사용하여 보고서를 작성하려면 여러 단계를 거쳐야 합니다. Pandas 라이브러리를 사용하여 Excel 스프레드시트에서 데이터를 읽고 CSV 보고서를 생성하는 간단한 Python 스크립트를 제공합니다. 이 스크립트를 기반으로 다른 형식으로 보다 복잡한 보고서를 생성하고 필요에 따라 이메일 또는 Slack 알림을 자동화할 수 있다는 점을 기억하십시오.
필수 라이브러리 설치
스크립트를 실행하기 전에 아직 설치되지 않은 경우 Pandas 라이브러리를 설치해야 합니다.
씨 설치하다 팬더 openpyxl

Python 코드에는 직원 급여 데이터가 포함된 Excel 스프레드시트의 경로와 보고서를 저장해야 하는 CSV 파일의 경로라는 두 가지 인수를 사용하는 generate_report()라는 함수가 있습니다.
이 함수는 먼저 Excel 스프레드시트를 Pandas DataFrame 개체로 읽어옵니다. 그런 다음 필요에 따라 데이터 처리 및 분석을 수행합니다. 이 인스턴스에서는 'Salary' 열의 합계가 함수에 의해 계산됩니다.
다음으로, 이 함수는 모든 직원의 총 급여가 포함된 보고서 문자열을 생성합니다. 마지막으로 이 함수는 보고서를 CSV 파일로 저장합니다.
코드의 주요 기능은 입력 Excel 파일과 출력 보고서 파일을 지정한 후 generate_report() 함수를 호출하여 보고서를 생성하는 것입니다.
GenReport.py:팬더 수입 ~처럼 pd_obj
def generate_report ( emp_salary_data, emp_salary_report_file ) :
노력하다:
# Excel 스프레드시트에서 데이터를 읽습니다.
df_obj = pd_obj.read_excel ( emp_salary_data )
# 필요에 따라 데이터 처리 및 분석을 수행합니다.
# 단순화를 위해 열의 합계를 계산한다고 가정해 보겠습니다.
급여_총액 = df_obj [ '샐러리' ] .합집합 ( )
# 보고서 작성
급여_보고서 = f '모든 직원 급여 총액: {salary_total}'
# 보고서를 CSV 파일로 저장
열린 채로 ( emp_salary_report_file, '안에' ) ~처럼 csv_obj:
csv_obj.write ( 급여_보고서 )
인쇄 ( 에프 '보고서가 생성되어 {emp_salary_report_file}에 저장되었습니다.' )
예외 제외 ~처럼 전:
인쇄 ( 에프 '오류가 발생했습니다: {str(e)}' )
만약에 __이름__ == '__기본__' :
# 입력 엑셀 파일과 출력 보고서 파일을 지정
emp_salary_data = 'input_employee_data.xlsx'
emp_salary_report_file = 'salary_sum.csv'
# 보고서를 생성하려면 generate_report 함수를 호출하세요.
generate_report ( emp_salary_data, emp_salary_report_file )
입력 직원 파일의 데이터는 다음과 같습니다.
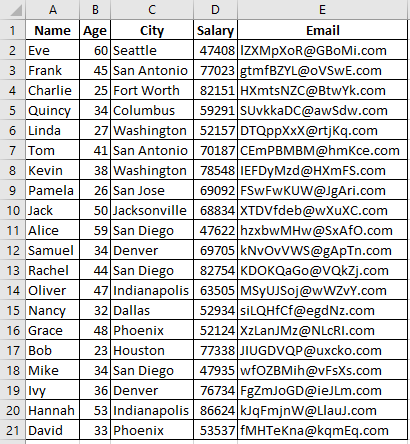
스크립트 테스트
스크립트가 의도한 대로 작동하는지 확인하기 위해 스크립트를 작성한 후 광범위하게 테스트해야 합니다. Python 컴파일러를 사용하여 자동화하는 파일을 테스트합니다. 이 경우 이 파일은 보고서를 성공적으로 생성하고 CSV 파일에 저장합니다.


스크립트 예약 또는 트리거
자동화 요구 사항에 따라 다양한 방법으로 Python 스크립트를 실행할 수 있습니다.
- 수동 실행: IDE에서 스크립트를 수행하거나 다음 명령을 사용하여 명령줄을 통해 수동으로 스크립트를 실행합니다. 파이썬 생성Report.py .
- 예약된 작업(Windows): Windows 작업 스케줄러를 사용하여 특정 시간이나 간격으로 스크립트를 실행할 수 있습니다. Windows 서비스를 사용하면 특정 이벤트를 호출할 수도 있습니다.
- 크론 작업(Linux/macOS): cron 작업을 사용하여 Unix 계열 시스템에서 특정 시간에 스크립트가 실행되도록 예약할 수 있습니다.
- 이벤트 중심: Watchdog과 같은 라이브러리를 사용하거나 웹훅과 통합하여 파일 변경과 같은 특정 이벤트에 대한 응답으로 스크립트를 트리거할 수 있습니다.
Python을 사용하여 MySQL 백업 자동화
매 시간마다 MySQL 서버의 백업 프로세스를 자동화하기 위해 'mysqlclient' 라이브러리와 함께 Python을 사용하여 MySQL 데이터베이스에 연결하고 백업을 생성할 수 있으며 Cron과 같은 작업 스케줄러(Unix 기반)를 사용할 수 있습니다. 시스템)을 사용하여 매시간 간격으로 Python 스크립트를 실행합니다. 다음은 이 목적으로 사용할 수 있는 Python 스크립트입니다.
1단계: 필수 라이브러리 설치
MySQL 연결을 위해서는 “mysqlclient” 라이브러리를 설치해야 합니다. pip를 사용하여 설치할 수 있습니다.
씨 설치하다 mysql클라이언트


2단계: 구성 파일 생성
비밀번호를 포함한 MySQL 연결 정보를 저장할 텍스트 파일(예: mysqlconfig.ini)을 만듭니다. 다음은 'mysqlconfig.ini' 파일의 모양에 대한 예입니다.
[ mysql ]mySQL_DB_HOST = 로컬호스트
mySQL_DB_USERNAME = 루트
mySQL_DB_PASSWORD = 1234
mySQL_DB_DATABASE_NAME = 브랜드w9_data
3단계: MySQL Bin 디렉터리 확인 :
'mysqldump' 명령은 MySQL bin 디렉터리에 있어야 합니다. 시스템의 PATH에 bin 디렉토리가 포함되어 있는지 확인하십시오. MySQL 저장소 위치를 포함하도록 PATH 환경 변수를 수정할 수 있습니다.
Windows: '시작' 메뉴에서 '환경 변수'를 탐색하고 MySQL bin 디렉터리(예: C:\Program Files\MySQL\MySQL Server X.X\bin)를 PATH 변수에 추가하여 시스템의 PATH를 편집할 수 있습니다.
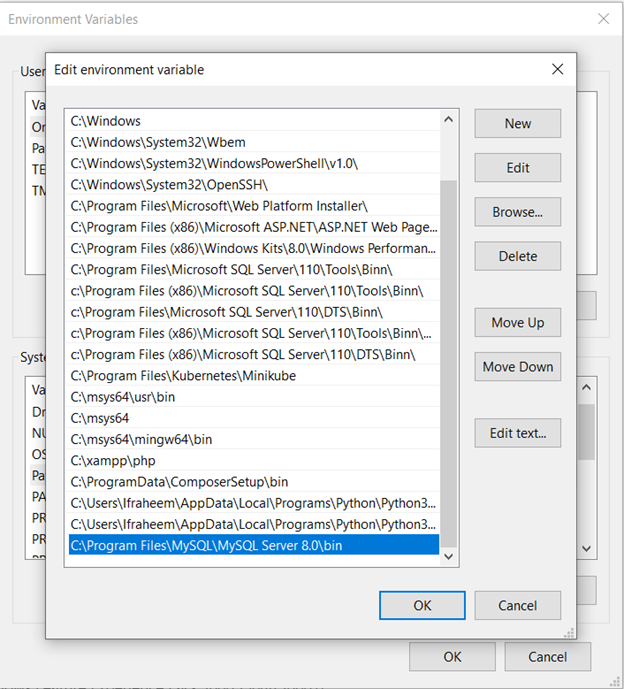
3단계: Python 스크립트 작성
MySQL 백업 프로세스를 자동화하려면 MySQLBackup.py와 같은 Python 스크립트를 만듭니다. 필요에 따라 자리 표시자를 데이터베이스 연결 세부 정보 및 파일 경로로 바꿉니다.
가져오기 하위 프로세스 ~처럼 sp날짜/시간에서 날짜/시간 가져오기 ~처럼 dt_obj
구성 파서 가져오기 ~처럼 mysql_config
# MySQL 데이터베이스 연결 세부정보
# 구성 파일에서 MySQL 연결 세부 정보를 로드합니다.
config_obj = mysql_confg.ConfigParser ( )
config_obj.read ( 'mysqlconfig.ini' ) # 필요한 경우 경로를 조정합니다.
mySQL_DB_HOST = config_obj.get ( '마이SQL' , 'mySQL_DB_HOST' )
mySQL_DB_USERNAME = config_obj.get ( '마이SQL' , 'mySQL_DB_USERNAME' )
mySQL_DB_PASSWORD = config_obj.get ( '마이SQL' , 'mySQL_DB_PASSWORD' )
mySQL_DB_DATABASE_NAME = config_obj.get ( '마이SQL' , 'mySQL_DB_DATABASE_NAME' )
# 백업 디렉토리
bk_dir = '백업_디렉토리/'
# 백업 파일 이름의 현재 날짜와 시간을 가져옵니다.
타임스탬프 = dt_obj.now ( ) .strftime ( '%Y%m%d%H%M%S' )
# 백업 파일 이름을 정의합니다.
my_sql_bk = f 'backup_{timestamp_oj}.sql'
# MySQL 덤프 명령
mysql_dump_cmd = f 'mysqldump -h {mySQL_DB_HOST} -u {mySQL_DB_USERNAME} -p{mySQL_DB_PASSWORD} {mySQL_DB_DATABASE_NAME} > {bk_dir}{my_sql_bk}'
노력하다:
# MySQL dump 명령을 실행하여 백업을 생성합니다.
sp.run ( mysql_dump_cmd, 껍데기 =사실, 확인하다 =사실 )
인쇄 ( 에프 '백업이 완료되어 '{bk_dir}'에 '{my_sql_bk}'로 저장되었습니다.' )
sp.CalledProcessError 제외 ~처럼 그것은:
인쇄 ( 에프 '백업 생성 오류: {str(e)}' )
4단계: 코드 테스트 및 실행

5단계: Windows 작업 스케줄러를 사용하여 스크립트 예약
이제 Windows 작업 스케줄러를 사용하여 Python 스크립트가 자동으로 실행되도록 예약해 보겠습니다.
'시작' 메뉴의 검색 표시줄에 '작업 스케줄러'를 입력하거나 '실행' 대화 상자(Win + R)에 'taskschd.msc'를 입력하여 Windows 작업 스케줄러를 시작합니다.
작업 스케줄러의 왼쪽 창에서 '작업 스케줄러 라이브러리'를 선택합니다.
오른쪽 창에서 '기본 작업 만들기…'를 클릭하여 '기본 작업 만들기 마법사'를 엽니다.
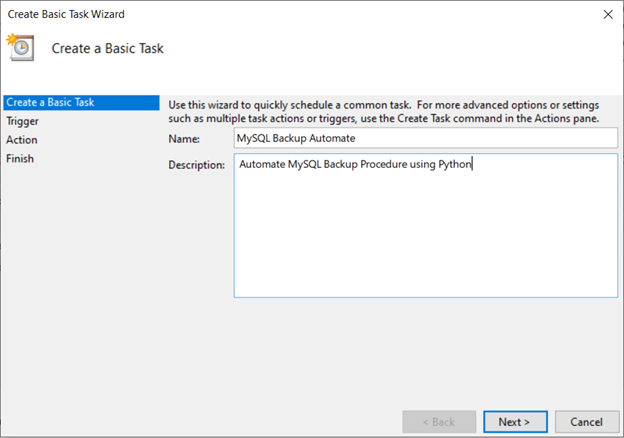
작업 이름과 설명을 입력합니다. 그런 다음 '다음'을 누르십시오.
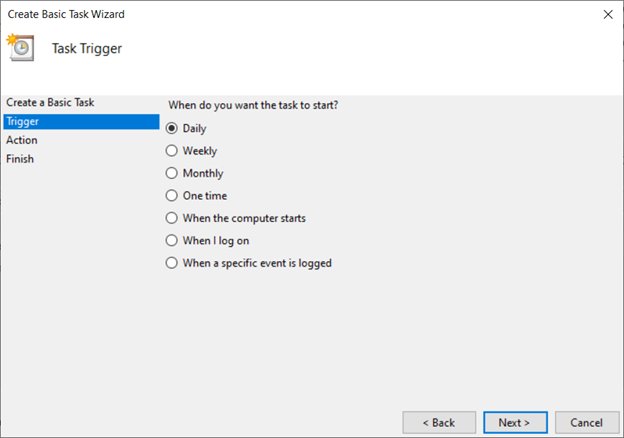
트리거 유형으로 '매일'을 선택합니다(매시간 실행하려는 경우에도 반복 간격을 설정할 수 있음). 그런 다음 '다음'을 클릭하십시오.
백업 작업의 시작 날짜와 시간을 지정합니다.
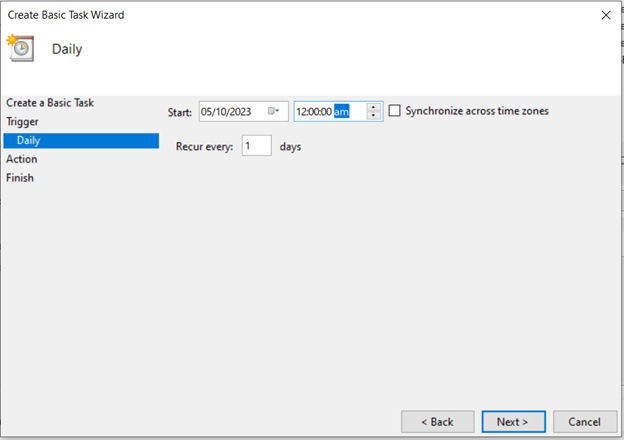
'작업 반복 간격:'을 선택하고 1시간으로 설정합니다.
기간을 '1일'로 설정합니다. 그런 다음 '다음'을 클릭하십시오.
'프로그램 시작'을 선택하고 '다음'을 누릅니다.
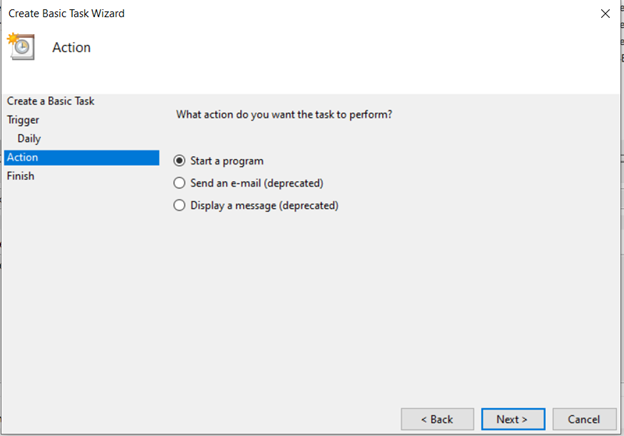
'찾아보기'를 클릭하여 Python 실행 파일(python.exe)을 찾아 선택합니다.
'찾아보기'를 클릭하여 Python 실행 파일(python.exe)을 찾아 선택합니다.
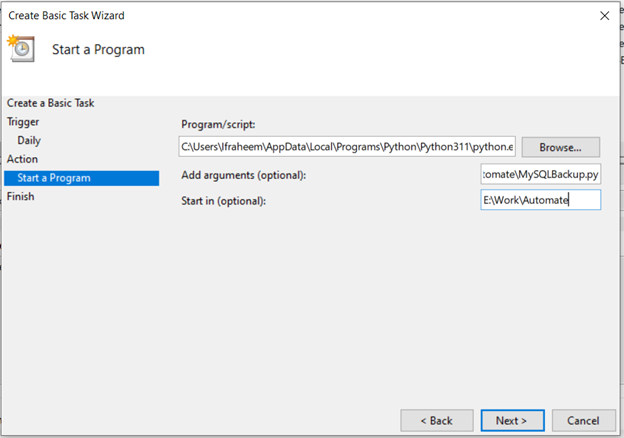
'인수 추가' 필드에 Python 스크립트의 전체 경로(예: C:\path\to\mysql_backup.py)를 입력합니다.
'시작 위치(선택 사항)' 필드에 Python 스크립트(예: C:\path\to\)가 포함된 디렉터리를 입력합니다.
“다음”을 클릭하세요.
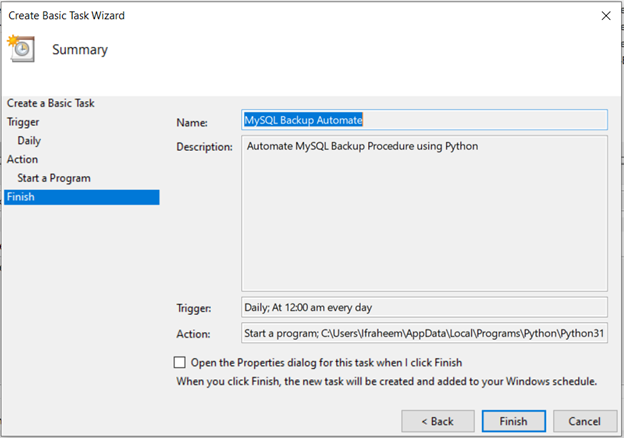
작업 설정을 검토하고 '마침'을 클릭하여 작업을 생성합니다.
결론
Python의 도구와 모범 사례를 활용하여 워크플로 시간을 단축하고 더 중요한 활동에 집중하는 안정적이고 효과적인 자동화 스크립트를 구축할 수 있습니다. Python 스크립트를 사용하여 작업을 자동화하는 데 확실히 도움이 되는 몇 가지 예를 제공했습니다.