Pandas Case 문을 사용하는 방법?
Case 문은 여러 가지 방법으로 만들 수 있습니다. 다음 기본 구문을 사용하는 NumPy where() 함수는 Pandas DataFrame에서 case 문을 구성하는 가장 간단한 방법입니다.
DF [ '열 이름' ] = np.어디에 ( 상태 1 , '값1',np.어디에 ( 상태 둘 , '값2',
np.어디에 ( 상태 삼 , '값3', '값4' ) ) )
위의 명령문은 값에 대한 각 조건을 확인하고 조건이 충족되면 출력을 생성하거나 조건에 대한 값을 반환합니다.
예제 # 1: where() 함수를 사용하는 Pandas Case 문
case 문을 사용할 수 있도록 먼저 데이터 프레임을 만들어 보겠습니다. 데이터 프레임을 생성하기 위해 먼저 numpy 및 pandas 모듈을 가져와서 해당 기능을 사용할 수 있습니다. pd.Dataframe()은 데이터 프레임을 생성하는 데 사용됩니다.

우리는 'df' 데이터 프레임을 만들었습니다. Python 사전은 키와 값이 포함된 인수로 pd.DataFrame() 함수 내부에 전달됩니다. 우리는 데이터 프레임을 보기 위해 print() 함수를 사용할 것입니다.
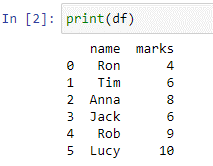
'df' 데이터 프레임에는 값 ['Ron', 'Tim', 'Anna', 'Jack', 'Rob', 'Lucy'] 및 [4, 6 , 8, 6, 9,10]. name이 학생의 이름을 저장하는 열이고 'marks' 열이 최근 시험의 점수를 저장한다고 가정합니다. 이제 각 조건에 대해 우리가 지정한 값을 기반으로 하는 'remarks'라는 새 열을 추가하는 case 문을 작성합니다.

'numpy.where()' 메서드는 지정된 조건을 충족하는 입력 배열, 열 또는 목록의 요소 인덱스를 제공합니다. 위의 스위치의 경우 np.where() 함수는 'marks' 열의 각 요소를 확인합니다. 값이 5보다 작거나 같으면 '실패'를 출력으로 반환합니다. 값이 7보다 작거나 같으면 만족스러운 값을 반환하고 값이 9보다 작거나 같으면 '우수'를 반환합니다. 값이 없으면 결과가 우수합니다.
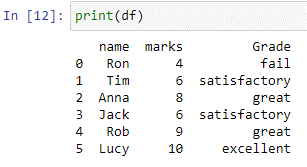
알 수 있듯이 새 열 'remarks'는 위의 case 문에서 반환된 값을 저장하는 'df' 데이터 프레임에 생성됩니다.
예 # 2:
다른 데이터 프레임으로 위의 case 문을 다시 시도해보자. 이전 축구 토너먼트에서 총 골을 기준으로 선수의 등급을 매겨야 한다고 가정합니다. 이제 축구 선수 기록을 저장할 데이터 프레임을 만들어 보겠습니다.
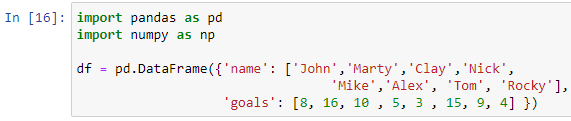
데이터 프레임을 생성하기 위해 pd.DataFrame() 함수 내부에 'name' 및 'goals' 키가 있는 사전을 전달했습니다. 데이터 프레임을 인쇄하려면 인쇄 기능을 사용합니다.
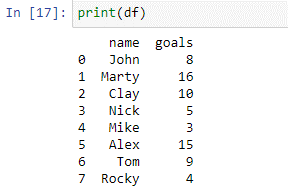
위의 데이터 프레임에서 볼 수 있듯이 '이름'과 '목표'라는 두 개의 열이 있습니다. 열 이름에는 플레이어의 이름이 있습니다 ['John', 'Marty', 'Clay', 'Nick', 'Mike', 'Alex', 'Tom', 'Rocky']. '열' 골에는 이전 토너먼트에서 각 플레이어가 득점한 총 골 수가 있습니다. 이제 사례 설명을 사용하여 득점한 골을 기반으로 이러한 선수의 등급을 매깁니다.

위의 경우는 where() 함수를 사용하여 생성됩니다. 케이스 내부에서 statement 함수는 조건에 대해 'marks' 열의 각 요소를 확인합니다. 'goals' 열의 값이 5 이하이면 'C'를 반환합니다. 'goals' 열의 값이 9 이하이면 'B'를 반환합니다. 'goals' 열의 값이 10 이상인 경우 'A'를 반환합니다. 명령문에서 반환된 값은 새 열 'rating'에 저장됩니다. 결과를 보기 위해 'df'를 인쇄해 봅시다.
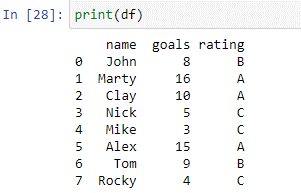
위의 스크립트를 사용하여 새 열 '등급'이 성공적으로 생성되었습니다.
예제 # 3: apply() 함수를 사용하는 Pandas if-else 문
데이터 프레임의 행 또는 열 축은 함수를 구현하기 위해 apply() 메서드에서 사용됩니다. 우리는 우리 자신의 정의된 함수를 생성하고 pandas의 데이터 프레임에서 사용할 수 있습니다. if-else 조건으로 구성됩니다. 먼저 데이터 프레임을 생성한 다음 if-else 문을 사용하여 결과를 생성하는 함수를 생성하겠습니다. 데이터 프레임을 생성하기 위해 먼저 pandas의 모듈을 가져온 다음 pd.DataFrame() 메서드 내부에 사전을 전달합니다.
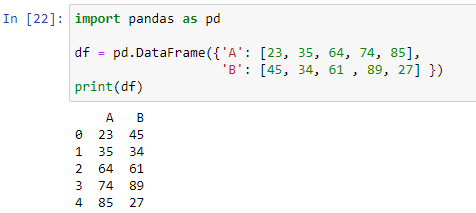
보시다시피 데이터 프레임은 숫자 값 [23, 35, 64, 74, 85]을 저장하는 두 개의 열 'A'와 값이 [45, 34, 61, 89, 27]인 'B'로 구성됩니다. 이제 데이터 프레임의 각 행에 있는 두 열 중 어느 값이 더 큰지 결정하는 함수를 만들 것입니다.
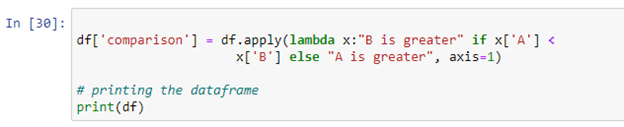
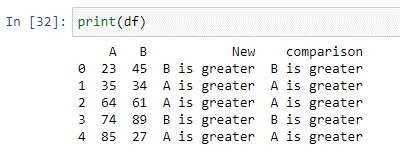
Python 람다 함수 'pandas.xml'을 사용할 수 있습니다. DataFrame.apply()”를 사용하여 표현식을 실행합니다. Python에서 람다 함수는 임의의 수의 인수를 허용하고 표현식을 실행하는 컴팩트한 익명 함수입니다. 위의 스크립트에서 두 열의 값을 비교하고 결과를 새 '비교' 열에 저장하는 조건문을 만들었습니다. 열 'A'의 값이 열 'B'의 값보다 작으면 'B가 더 큼'을 반환합니다. 조건이 충족되지 않으면 'A is more'를 반환합니다.
예 # 4:
다른 데이터 프레임과 함께 apply() 함수 내에서 if-else 문을 사용하여 다른 예를 시도해 보겠습니다.
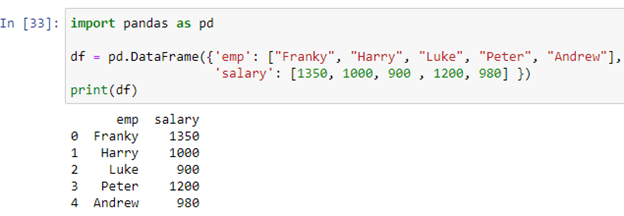
데이터 프레임이 어떤 회사 직원의 기록을 저장하고 있다고 가정합니다. 'emp' 열은 직원의 이름['Franky', 'Harry', 'Luke', 'Peter', 'Andrew']을 저장하는 반면, 'salary' 열은 각 직원의 급여를 저장합니다[1350, 1000, 900 , 1200, 980] 'df' 데이터 프레임. 이제 apply() 메서드를 사용하여 if-else 문을 만듭니다.

위의 조건은 'salary' 열의 각 값을 확인하고 급여 값이 1000보다 작거나 같은 직원의 급여에 200을 추가합니다. apply() 함수에서 반환된 값을 새 열 '에 저장했습니다. 증가'. 위 스크립트의 결과를 보자.
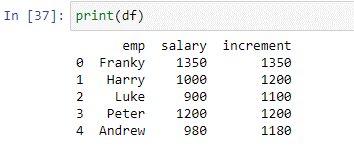
보시다시피 함수는 100보다 작거나 같은 값에 200을 성공적으로 추가했습니다. 1000보다 큰 값은 변경되지 않은 상태로 유지되었습니다.
결론:
이 자습서에서는 조건이 충족될 때 case 문이라고 하는 이 유형의 문에서 값을 반환하는 것을 보았습니다. 필요한 작업이나 작업을 수행하기 위해 case 문을 만드는 방법을 살펴보았습니다. 이 튜토리얼에서는 np.where() 함수와 apply() 함수를 사용하여 case 문을 생성했습니다. where() 함수를 사용하여 pandas case 문을 사용하는 방법과 apply() 함수를 사용하여 case 문을 만드는 방법을 알려주기 위해 몇 가지 예제를 구현했습니다.