'Pandas'는 데이터 중심 파이썬 패키지의 훌륭한 생태계로 인해 데이터 분석을 수행하는 데 훌륭한 언어입니다. 이렇게 하면 두 요소의 분석 및 가져오기가 더 쉬워집니다. 표준 편차는 평균에서 파생된 '전형적인' 편차입니다. 데이터 프레임의 원래 측정 단위를 반환하므로 많이 사용됩니다. 팬더는 표준 편차를 계산하기 위해 std()를 사용했습니다. 표준 편차는 행 또는 열의 형태로 데이터 프레임에 있을 수 있는 주어진 값에서 계산할 수 있습니다. 우리는 판다 표준편차를 사용하는 가능한 모든 방법을 구현할 것입니다. 코드 구현을 위해 파이썬 친화적인 환경에서 작성된 'spyder' 도구를 사용할 것입니다.'
통사론
'df.std ( ) '
다음 구문은 데이터 프레임의 표준 편차를 계산하는 데 사용됩니다. 데이터 프레임의 'df'는 '데이터 프레임'의 약어입니다. 표준 편차는 무엇을합니까? 필요한 데이터가 얼마나 확장되었는지 측정합니다. 더 확장된 높은 값, 더 높은 표준 편차가 발생해야 합니다.
반품
팬더 표준 편차는 요구 사항에 따라 수준이 지정된 경우 데이터 프레임을 반환합니다.
'std()' 함수는 팬더 표준 편차를 계산하는 동안 'df'의 'NaN' 값을 자동으로 무시합니다. 'NaN'은 '숫자가 아님'으로 설명할 수 있습니다. 즉, 특정에 할당된 값이 없음을 의미합니다.
다음은 pandas 표준 편차의 예와 함께 실행될 메서드입니다.
-
- 단일 열의 팬더 표준 편차 계산.
- 여러 열에서 팬더 표준 편차 계산.
- 모든 숫자 열의 팬더 표준 편차 계산.
- 축 = 1을 사용하는 팬더 표준 편차.
- 축 = 0을 사용하는 팬더 표준 편차.
Pandas에서 표준 편차 계산을 위한 데이터 프레임 만들기
먼저 '스파이더' 소프트웨어를 엽니다. 이제 pandas 라이브러리를 pd로 가져옵니다. '22', '10', '11', '16', '12', '45'와 같은 점수와 'x', 'y' 및 'z'라는 용어가 있는 스코어보드로 구성된 데이터 프레임을 생성합니다. ', '36' 및 '40'. 어시스트 값은 '8', '9', '13', '7', '22', '24', '4' 및 '6'이며 리바운드 값은 '17', ' 14', '3', 5', '9', '8', '7' 및 '4'.
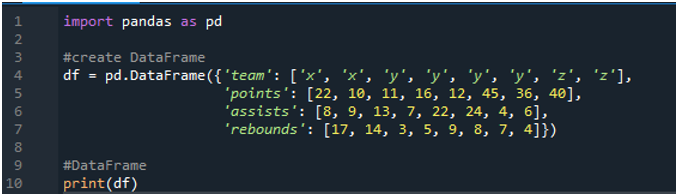
디스플레이에는 코드에 할당된 값에 따라 생성된 데이터 프레임이 표시됩니다.

예제 # 01: 단일 열에서 Pandas 표준 편차 계산
이 예에서는 pandas 데이터 프레임에 있는 단일 열의 표준 편차를 계산합니다. 데이터 프레임은 팀의 값이 'u', 'v' 및 'b'이고 점수가 '44', '33', '22', '44', '45', '88', '96'입니다. ' 및 '78'. 어시스트 값은 '7','8', '9', '10', '11', '14', '18' 및 '17'이며 리바운드 값도 '11', ' 9', '8', '7', '6', '5', '4' 및 '3'입니다. 열 '점'은 단일 열 표준 편차를 계산하기 위해 데이터 프레임에서 선택됩니다.
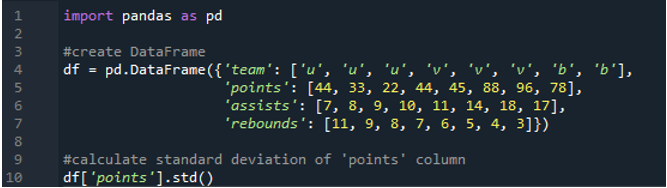
출력은 'points' 열에 대해 계산된 표준 편차를 보여줍니다.

예제 # 02: 여러 열에서 Pandas 표준 편차 계산
이 예에서는 여러 열에서 팬더 표준 편차 계산을 실행합니다. 이 데이터 프레임에서 데이터는 팀 값이 'n', 'w' 및 't'이고 점수가 '33', '22', '66', '55'인 스포츠 스코어보드의 데이터입니다. '44', '88', '99' 및 '77'. '9', '7', '8', '11', '16', '14', '12' 및 '13'의 어시스트 및 '5', '8', '1', '리바운드' 2', '3', '4', '6' 및 '7'입니다. 여기서 우리는 데이터 프레임에 적용된 std() 함수를 사용하여 두 열 'points'와 'rebounds'의 표준 편차를 계산할 것입니다.
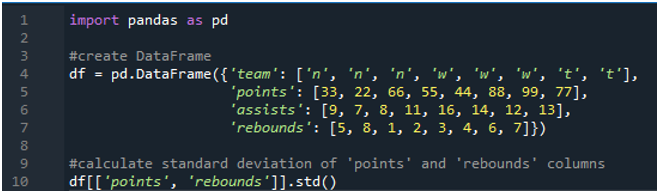
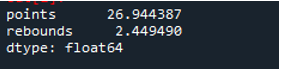
보시다시피, 출력은 표준 편차가 포인트 열에서 각각 26.944387, 리바운드 열에서 2.449490으로 나타났음을 보여줍니다.
예제 # 03: 모든 숫자 열의 Pandas 표준 편차 계산
이제 우리는 단일 행과 다중 행의 표준 편차를 계산하는 방법을 배웠습니다. 데이터 프레임의 모든 열 이름을 지정하고 전체 데이터 프레임을 계산하지 않으려면 어떻게 해야 합니까? 이것은 결과에서 전체 데이터 프레임의 계산을 위한 팬더 표준 편차의 간단한 함수 구현으로 가능합니다. 여기서 데이터 프레임은 'l', 'm' 및 'o'로 구성되며 점수 값은 '33', '36', '79', '78', '58', '55'이며 두 팀의 점수는 동일합니다. 그것은 '25'입니다. 어시스트는 '1', '2', '3', '4', '6', '9', '5' 및 '7'이고 리바운드는 '14', '10', '2'입니다. , '5', '8', '3', '6' 및 '9'. pandas 'std()' 함수를 사용하여 데이터 프레임에서 pandas의 모든 표준 열 편차를 계산할 수 있습니다.
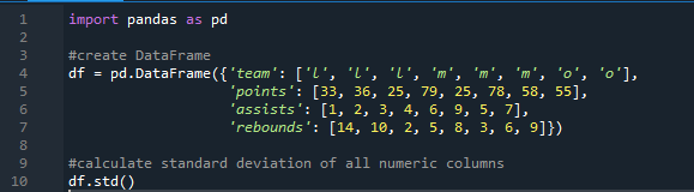
디스플레이에는 아래 표시된 전체 'df'의 계산된 표준 편차가 있습니다. 또한 pandas는 숫자 열이 아니기 때문에 '팀'인 첫 번째 열의 표준 편차를 계산하지 않았음을 알 수 있습니다.
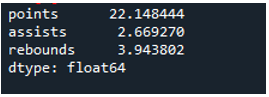
예제 # 04: 축 = 0을 사용하는 Pandas 표준 편차
이 예에서 데이터 프레임에는 추가 데이터와 함께 'g', 'h' 및 'k'로 스포츠 팀이 있습니다. 여기서는 pandas 표준편차에서 사용하는 파라미터인 “0”을 축으로 하여 표준편차를 계산해 보겠습니다. 이 인수는 데이터 프레임의 열 방향 표준 편차를 계산합니다.
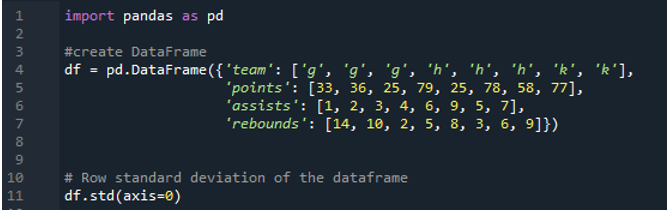
다음 출력은 계산된 표준 편차의 열에 결과를 표시합니다. 포인트 열의 계산 표준 편차는 '24.0313062', 지원 열의 계산 표준 편차는 '2.669270', 리바운드 열의 계산 표준 편차는 '3.943802'입니다.
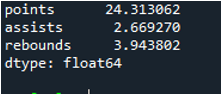
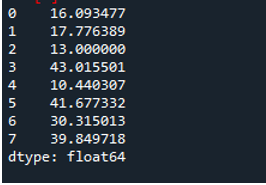
예제 # 05: 축 = 1을 사용하는 Pandas 표준 편차
여기에서 '1'로 할당된 축 매개변수를 사용하여 팬더의 표준 편차를 계산합니다. 축 '1'은 어떤 차이를 만들 수 있습니까? '1' 축 인수는 데이터 프레임에 있는 숫자 값의 행 방향 표준 편차를 계산합니다. 데이터 프레임은 'd', 'e'의 세 팀으로 구성되며 팀의 포인트, 팀의 어시스트 및 팀의 리바운드로 생성된 데이터 열이 추가됩니다. 방향은 모두 데이터 프레임에서 다른 값으로 할당됩니다. 이 축 매개변수는 시간이 지나면 수행된 표준 편차로 계산된 더하기 열에 데이터가 포함되기를 원하는 데이터에 대해 작업해야 하므로 게임 체인저입니다.
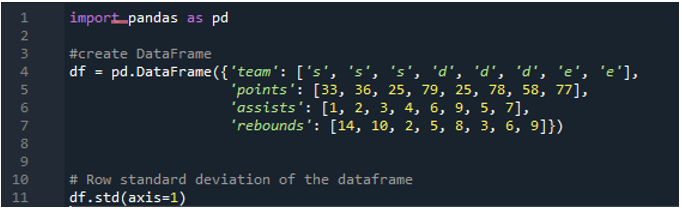
다음 출력은 데이터 프레임의 행에서 계산된 표준 편차를 표시합니다.
결론
Pandas 표준편차는 매우 기술적인 기능으로, Pandas 데이터프레임의 열정약정의 표준편차를 찾아주는 매우 유익한 기능입니다. 이 사설에서는 판다에서 표준편차를 계산하는 방법을 연구했습니다. 우리는 표준 편차와 여러 열의 단일 열 계산을 수행했으며 전체 데이터 프레임의 표준 편차도 함께 계산했습니다. 모든 전략은 일관되게 사용하고 원하는 결과를 얻으면 잘 작동합니다.