실시예 01
MongoDB의 데이터베이스 컬렉션 필드에 대해 $count 작업을 수행하려면 수많은 레코드가 필요합니다. 따라서 우리는 “Test”라는 컬렉션을 생성하고 insertMany() 함수를 사용하여 12개의 레코드를 동시에 삽입했습니다. 이제 이 '테스트' 컬렉션의 레코드가 find() 함수 쿼리를 통해 MongoDB 셸에 표시되었습니다. 총 3개의 필드(_id, name, Score)가 있는 것을 확인할 수 있습니다.
테스트> db.Test.find({}) 
이제 모든 필드에 $count 단계를 적용하려면 'db' 명령 내에서 MongoDB의 집계 함수를 사용해야 합니다. 집계 함수는 종종 특정 필드에 $match 연산자를 사용하는 조건문과 $count 연산자를 사용하여 지정된 조건 필드에서 얻은 총 개수를 표시하는 새 필드로 구성됩니다.
우리의 경우 $match 연산자를 사용하여 점수 필드의 '60' 값과 일치하는 레코드를 검색했으며 $count 연산자를 사용하여 가져온 총 레코드 수를 계산하고 이를 아래에 표시했습니다. 'SameScore'라는 새 필드. 이 쿼리의 출력에는 'Test' 컬렉션에 'score' 값 '60'이 2인 두 개의 레코드가 있음을 나타내는 값 '2'가 있는 'SameScore' 필드가 표시되었습니다.
db.Test.aggregate([ { $match: { '점수' : 60 } }, { $개수: '동일점수' } ])
또한 $count 집계를 사용하여 테스트 컬렉션의 'name' 필드와 같이 숫자 이외의 필드를 계산할 수도 있습니다. 우리는 일치 집계를 사용하여 이름 필드의 값이 'John'인 컬렉션에서 레코드를 검색했습니다. 개수 집계는 일치하는 총 레코드 수인 2를 성공적으로 계산했습니다.
db.Test.aggregate([ { $match: { '이름' : '남자' } }, { $개수: 'SameName' } ])
실시예 02
위의 쿼리를 업데이트하고 다른 조건을 적용하여 다른 레코드를 얻어보겠습니다. 이번에는 점수 필드의 $match 집계를 적용하여 점수 필드의 값이 30보다 작은 레코드의 총 개수를 가져옵니다. 개수 집계는 총 레코드 수를 계산하고 새 레코드에 추가합니다. 열 'GradeD' 출력에는 일치하는 값의 개수로 결과 '2'가 표시됩니다.
db.Test.aggregate( [ { $match: { 점수: { $lt: 30 } } }, { $개수: 'D등급' } ] )필드 레코드에 대해 두 개 이상의 조건을 수행하기 위해 논리 연산자를 적용하는 동안 $count 집계를 사용할 수도 있습니다. 따라서 $and 연산자를 사용하여 'Score' 필드에 gte(크거나 같음)와 lte(작고 같음)의 두 가지 조건이 적용되었습니다. 결과를 얻고 레코드 수를 계산하려면 두 조건이 모두 true여야 합니다. 총 개수에는 일치 기준이 있는 레코드가 5개 있음이 표시됩니다.
db.Test.aggregate( [ { $match: { '$그리고' : [ { '점수' : {$gte: 60 }}, { '점수' : {$lte: 80 }} ] }},
{ $개수: 'B등급' } ] )
실시예 03
위 그림에서는 지정된 점수 또는 이름과 같은 특정 필드 값에 대해 일치하는 레코드 수만 가져오기 위해 개수 집계를 사용했습니다. MongoDB의 집계 방법을 사용하면 컬렉션에 중복된 값이 포함된 모든 레코드의 개수를 얻을 수 있습니다.
이를 위해서는 아래와 같이 집계 함수 명령 내에서 $group 집계를 사용해야 합니다. _id 필드는 개수 집계가 작동하는 '이름' 필드를 지정하는 데 사용되었습니다. 이와 함께 NameCount 사용자 정의 필드는 $count 집계를 활용하여 'name' 필드의 여러 중복 항목을 계산합니다.
이 쿼리에 대한 출력이 아래에 표시되었습니다. 여기에는 '이름' 필드의 값과 값 중복에 따른 NameCount 필드 내의 해당 개수가 포함됩니다(예: Cillian이 4개의 중복을 갖는 등).
db.Test.aggregate([ { $group: { _id: '$이름' , 이름 개수: { $count: {} }, }, }, ]) 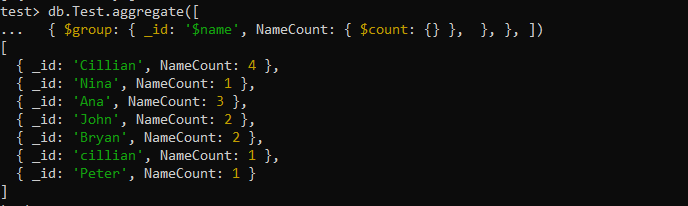
실시예 04
또한 중첩된 필드 레코드에 대한 개수 집계를 사용하여 특정 필드 값의 개수를 계산할 수도 있습니다. 이에 대해 자세히 설명하기 위해 'Teacher'라는 컬렉션을 만들고 그 안에 중첩 필드 'sub'와 배열 유형 필드 'shift'를 다른 필드인 이름 및 급여와 함께 추가했습니다. find() 함수는 이 컬렉션의 5개 레코드를 모두 표시했습니다.
테스트> db.Teacher.find({}) 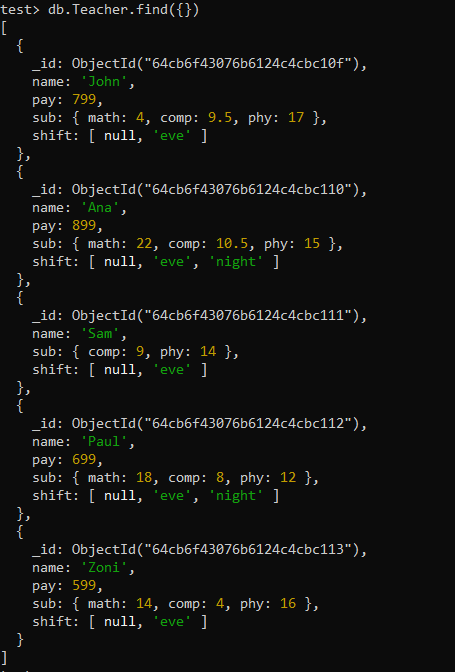
이제 일치 연산자가 포함된 집계 함수를 적용했습니다. 또한 두 가지 다른 조건이 포함된 'sub' 필드의 하위 필드 'math'에 $and 연산자가 적용되었습니다. 그런 다음 개수가 계산되었습니다. 출력에는 하위 필드 수학 값이 10보다 크고 20보다 작은 두 개의 레코드가 있음이 표시됩니다.
db.Teacher.aggregate( [ { $match: { '$그리고' : [ { '하위 수학' : {$gte: 10 }}, { '하위 수학' : {$lte: 이십 }} ] }}, { $개수: 'A 급' } ] )실시예 05
이번에는 count 집계를 사용하는 대신 count() 함수를 사용하는 방법을 설명하기 위해 마지막 예제를 살펴보겠습니다. 그래서 count() 함수가 “Teacher” 컬렉션의 배열 유형 필드, 즉 “shift”에 적용되었습니다. 인덱스 2를 사용하는 배열 필드의 인덱스를 사용하여 일치 기준을 '밤'으로 지정했습니다. 항목 'night'에 대한 총 카운트 수로 '2'를 출력합니다.
db.교사.카운트({ '교대.2' : '밤' })매우 유사한 방식으로, count() 함수는 'Teacher' 컬렉션의 'sub' 필드의 하위 필드 'phy'와 같은 중첩 필드에도 적용될 수 있습니다. 'phy' 하위 필드에 14 미만의 값을 나타내는 'lte' 연산자를 사용하여 일치 기준을 지정했습니다. 이 명령어의 출력에는 '2'가 표시되었습니다. 즉, 14보다 작은 값을 가진 4개의 레코드가 표시되었습니다.
db.교사.수({ '하위.phy' : { $lte: 14 } })결론
이 가이드는 여러 코드 예제를 통해 MongoDB의 $count 집계 사용에 대해 시연하고 자세히 설명했습니다. 이 예에는 컬렉션을 통해 특정 값 레코드 및 모든 필드 레코드에 대한 카운트 번호를 가져오는 카운트 집계의 의미가 포함됩니다. 또한 배열 필드 및 포함(중첩) 필드에 대한 개수 집계 사용이 포함됩니다. 결국 count 집계 사용과 count 함수 사용의 차이를 만들기 위해 count() 함수 예제가 포함되었습니다.