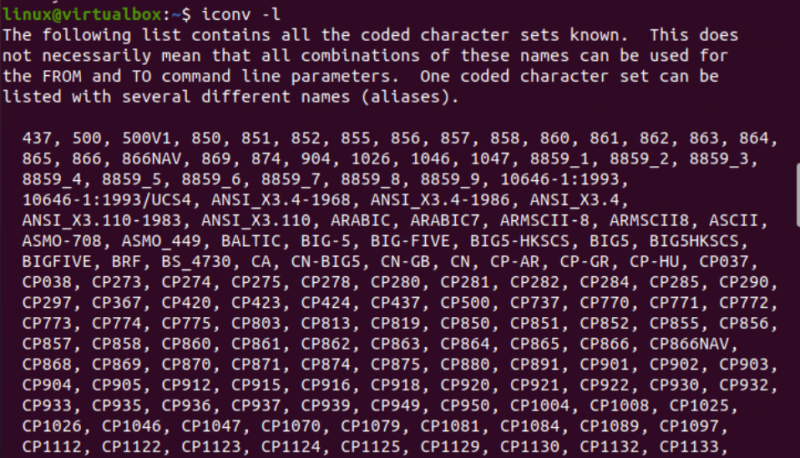
이제 터미널 콘솔에서 Linux의 iconv 유틸리티를 살펴보겠습니다. 그래서 우리는 터미널 화면에 알려지고 가장 많이 사용되는 모든 코딩된 문자 집합을 표시하기 위해 '-l' 플래그와 함께 'iconv' 명령을 실행했습니다. 코드화된 문자 집합과 해당 별칭이 표시됩니다. 조금 아래로 스크롤하면 코딩된 문자 집합의 긴 목록을 볼 수 있습니다.
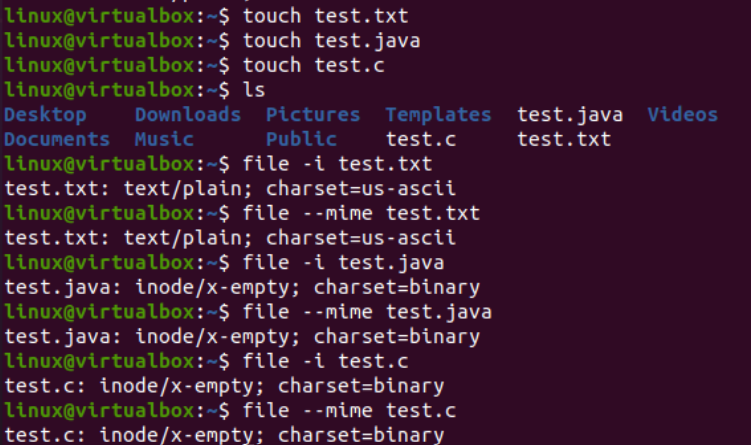
이제 Linux에서 iconv 명령 구현을 시작할 때입니다. 먼저, 한 유형의 파일을 다른 유형으로 변환하려면 시스템에 다른 유형의 파일이 필요합니다. 따라서 콘솔 터미널에서 '터치' 쿼리를 사용하여 Java 유형, C 유형 및 텍스트 유형의 세 가지 파일을 생성합니다. 현재 디렉토리 내용을 나열하면 새로 생성된 파일을 찾을 수 있습니다.
그런 다음 각 파일의 이름과 함께 '파일' 쿼리를 사용하여 각 파일의 유형을 개별적으로 살펴보겠습니다. 이 쿼리는 각 파일에 대한 코딩 문자 집합의 유형을 별도로 표시하기 위해 '-I' 옵션이 필요합니다. '-I' 옵션을 사용하는 것을 잊은 경우 대신 '-mime' 플래그를 사용하십시오. '-I' 및 '-mime' 플래그는 모두 동일하게 작동합니다.
이제 'txt' 형식 파일에 대해 'file' 명령을 실행한 후 'US-ASCII' 문자 형식 인코딩을 얻었습니다. Java 및 C 파일에 대해 동일한 명령을 사용하는 동안 두 파일 모두 'BINARY' 문자 유형 인코딩이 포함되어 있음을 보여줍니다. 이와 함께 이 명령은 이 세 파일이 모두 비어 있음을 보여줍니다.
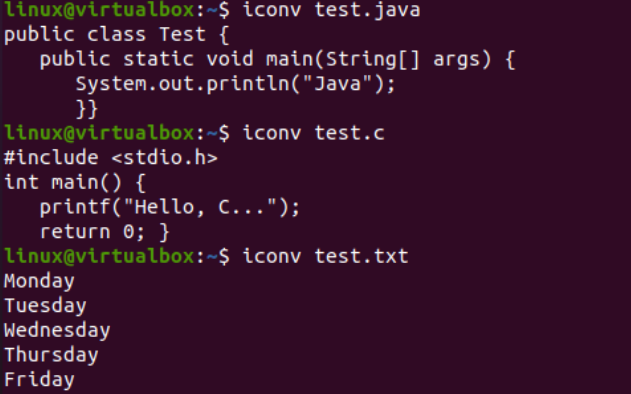
이제 콘솔에서 iconv 명령어를 사용하여 특정 문자 집합 인코딩 파일을 다른 문자 집합 인코딩으로 변환하는 방법을 설명합니다. 그 전에 파일에 코드나 데이터를 추가해야 합니다. 따라서 'text.java' 파일에 Java 코드, 'text.c' 파일에 C 코드, 'test.txt' 파일에 텍스트 데이터를 추가했습니다. cat 쿼리는 아래와 같이 세 파일 모두의 내용을 표시하는 데 사용되었습니다.
이제 데이터를 성공적으로 추가했으므로 이 파일의 문자 집합 인코딩을 다시 한 번 볼 수 있습니다. 따라서 '-I' 플래그와 파일 이름(예: test.txt, test.java 및 test.c)을 사용하여 쉘 내에서 동일한 파일 명령을 시도했습니다. 세 파일 모두에 대해 이 세 가지 지침을 개별적으로 실행하면 문자 집합 인코딩이 Java 및 C 파일에 대해 업데이트되었지만 텍스트 파일(예: US-ASCII)에 대해서는 동일하게 유지되었음을 알 수 있습니다. Java 및 C 파일의 인코딩은 이전에 '바이너리'였습니다. 이제 'US-ASCII'입니다. 또한 텍스트 파일에는 일반 텍스트 데이터가 포함되어 있고 다른 두 코드 파일에는 스크립트가 내용으로 포함되어 있음을 보여줍니다.

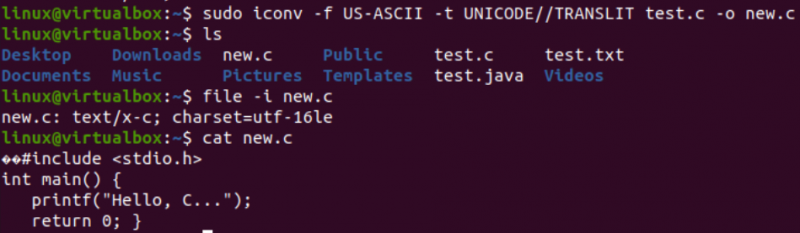
이제 이 기사에 필요한 실제 작업, 즉 셸에서 iconv 명령을 사용하여 인코딩을 다른 인코딩으로 변환할 시간입니다. 따라서 'sudo' 권한이 있는 쉘 터미널 내에서 'iconv' 명령을 사용하고 있습니다. 이 명령은 '-f' 옵션은 'from'을 의미하고 '-t' 옵션은 'to', 즉 한 인코딩에서 다른 인코딩으로를 나타냅니다.
'-f' 옵션 뒤에는 파일에 이미 있는 인코딩(예: US-ASCII)을 지정해야 합니다. '-t' 옵션 뒤에 있는 동안 이전 인코딩(예: UNICODE)으로 교체하려는 인코딩을 지정해야 합니다. 객체 이미지를 생성하려면 –o 옵션을 사용하여 소스로 사용되는 파일의 이름을 지정해야 합니다. 객체 이미지는 동일한 유형이지만 새로운 인코딩과 동일한 데이터를 사용하는 다른 파일, 즉 'new.c'입니다.
다음 명령을 실행하면 'ls' 쿼리에 따라 동일한 디렉토리에 새 파일이 생성됩니다. 이제 iconv 명령을 사용하여 생성된 새 파일의 문자 집합 인코딩을 확인합니다. '-I' 옵션과 새 파일 이름, 즉 new.c와 함께 '파일' 명령을 다시 활용합니다.
이 새 파일의 문자 집합이 이전 파일의 문자 집합(예: UTF-16LE 문자 집합)과 다르다는 것을 알 수 있습니다. 이는 new.c 파일에 대한 iconv 명령을 사용하여 US-ASCII 인코딩을 UNICODE 인코딩으로 변환했기 때문입니다. 'cat' 쿼리는 파일 내에서 동일한 C 코드를 표시했지만 이미 제시된 것처럼 일부 유니코드 문자로 시작했습니다.
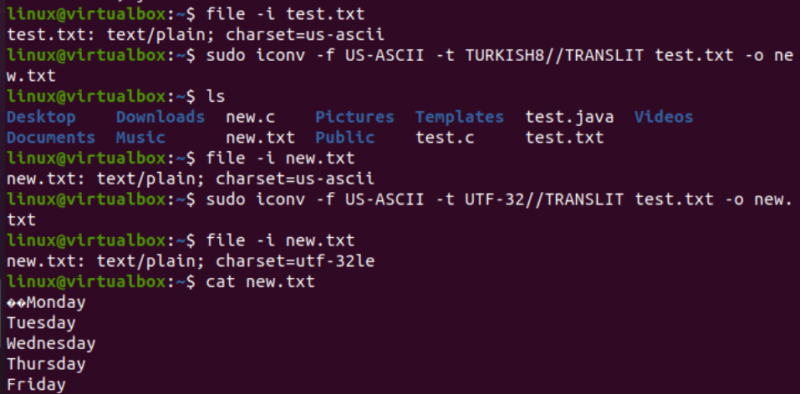
매우 유사한 방식으로 test.txt 텍스트 파일의 인코딩을 변경합니다. 파일 명령은 US-ASCII 문자 집합 인코딩이 있음을 보여줍니다. iconv 명령은 test.txt 파일의 인코딩을 US-ASCII에서 TURKISH8로 변환하기 위해 동일한 형식으로 사용되었습니다. US-ASCII를 터키어로 변경하지 않는 것을 볼 수 있습니다.
그런 다음 동일한 명령을 사용하여 동일한 파일에 대한 US-ASCII에서 UTF-32 문자 세트 인코딩을 처리했습니다. 이번에는 작동합니다. 이는 때때로 한 인코딩 세트를 다른 인코딩 세트로 변환하는 데 문제가 있거나 다른 인코딩이 지원하지 않을 수 있기 때문입니다.
결론
이 기사에서는 iconv Linux 명령어를 사용하여 별칭을 사용하여 인코딩 문자 집합을 다른 인코딩 문자 집합으로 변환하는 방법에 대해 설명했습니다. 이런 식으로 다른 유형의 파일을 만들어야 했습니다.