이 문서에서는 S3 버킷의 비용을 최적화하기 위해 Intelligent-Tiering을 구현하는 방법에 대한 지침을 제공합니다.
S3 버킷의 지능형 계층화란 무엇입니까?
데이터는 전 세계적으로 기하급수적으로 증가하고 있습니다. 이 데이터 중 일부는 매일 액세스되지만 나머지는 가끔씩만 필요합니다. S3는 데이터 저장을 위한 AWS의 가장 인기 있는 서비스 중 하나이므로 AWS는 다음과 같은 스토리지 클래스를 도입했습니다. “지능형 계층화” 데이터 저장으로 인한 S3 지출을 줄이기 위해. 다음 문서를 참조하여 S3 버킷의 다양한 스토리지 클래스에 대해 자세히 알아보세요. “S3의 다양한 스토리지 클래스 개요” .
Intelligent-Tiering은 데이터 액세스 패턴을 모니터링하여 S3 지출을 최적화할 수 있습니다. 이 기능은 어떤 데이터가 자주 액세스되는지 또는 가끔 액세스되는지를 결정하는 데 충분히 효율적입니다. 이러한 패턴을 기반으로 운영 오버헤드나 성능 저하 없이 자동으로 식별하여 가장 비용 효율적인 계층에 배치합니다.
지능형 계층화를 통해 Amazon S3에서 데이터 스토리지 비용을 최적화하는 방법은 무엇입니까?
데이터 액세스 패턴에 따라 거의 액세스되지 않는 개체는 저렴한 액세스 계층 최적의 비용 목적을 위해. 사용자가 객체에 접근하면 자동으로 즉시 해당 객체로 다시 이동됩니다. 빈번한 액세스 계층 추가 비용 없이 이용 가능 여부:
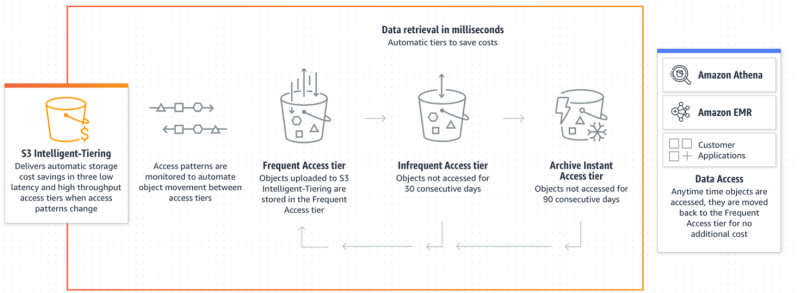
지능형 계층화는 예측할 수 없는 데이터 액세스 패턴에 대한 비용을 최적화하려는 경우 사용자에게 실현 가능하고 이상적인 선택입니다. 다음은 비용 효율성을 위해 지능형 계층화 스토리지 클래스를 구현할 수 있는 단계입니다.
1단계: S3 대시보드
S3 버킷을 사용하여 데이터 스토리지에 대한 비용 최적의 솔루션을 얻으려면 다음을 검색하십시오. 'S3' AWS 검색 창에서 서비스를 클릭하고 표시된 결과에서 해당 서비스를 클릭합니다.
2단계: 버킷 생성
다음을 클릭하세요. “버킷 생성” 버튼을 S3 콘솔 :
3단계: 일반 구성
표시된 인터페이스에서 고유 식별자 S3 버킷의 경우 “일반 구성” 부분:
4단계: '버킷 만들기' 버튼을 탭하세요.
기본값을 유지하면서 “버킷 생성” 인터페이스 하단에 있는 버튼:
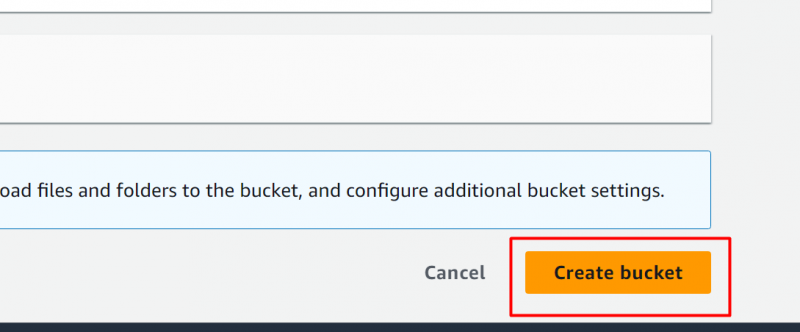
버킷이 성공적으로 생성되었습니다. 다음으로 이 버킷에 파일을 업로드하겠습니다. 버킷 이름을 클릭하여 파일 업로드 인터페이스로 이동합니다.
5단계: 파일 업로드
다음을 클릭하세요. “업로드” 표시된 인터페이스의 버튼:
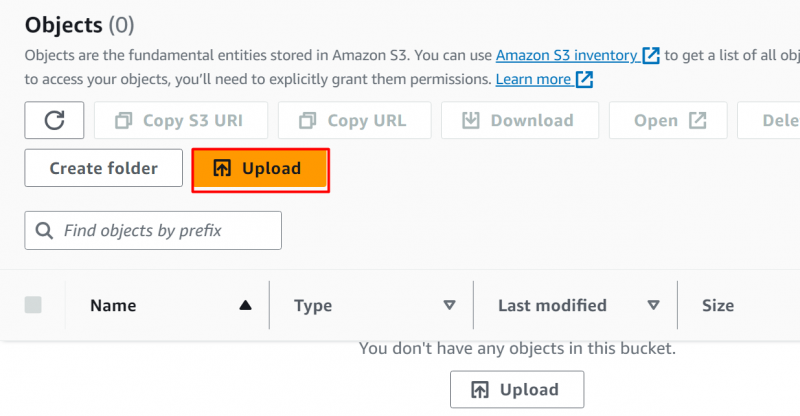
파일을 선택하려면 '파일 추가' 버튼을 누른 다음 장치에서 파일/폴더를 선택합니다. 파일이 S3 버킷에 업로드되었습니다.
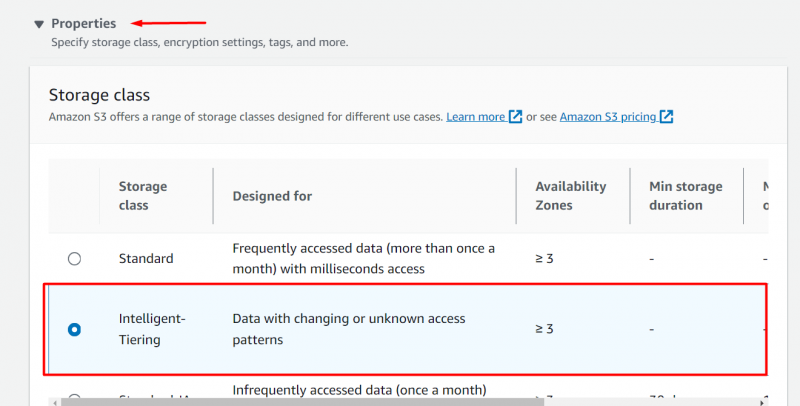
다음으로 이동하세요. '속성' 차단하고 '를 선택하세요. 지능형 계층화” 옵션에서 스토리지 클래스 부분 :
나머지 부분을 유지함으로써 설정은 변경되지 않음 , “업로드” 인터페이스 하단에 있는 버튼:
AWS는 확인 메시지 이는 파일이 성공적으로 업로드되었음을 나타냅니다.
6단계: '속성' 탭을 탭하세요.
파일을 업로드한 후 다음을 클릭하세요. '속성' 탭:
7단계: 지능형 계층화 아카이브 구성
로부터 속성 인터페이스에서 아래로 스크롤하여 “지능형 계층화 아카이브 구성” 섹션을 클릭하고 “구성 만들기” 단추:
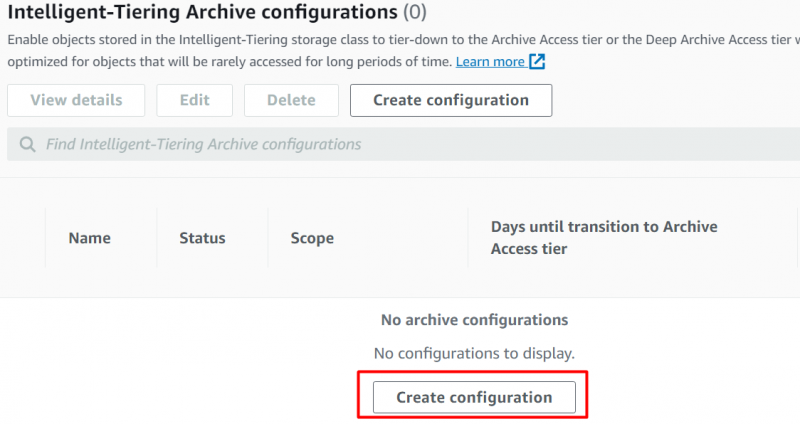
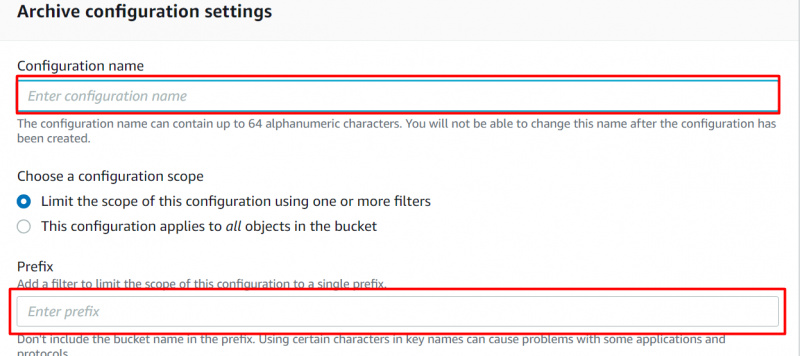
제공 '이름' 그리고 '접두사' 다음에 표시되는 인터페이스에 대한 구성:
8단계: 아카이브 액세스 계층
다음으로 이동하세요. '보관 규칙 작업' 개체를 이동해야 하는 시기를 구성하는 섹션입니다. 다음 옵션을 활성화하고 개체를 다음 위치로 이동할 연속 일 수를 제공합니다. “아카이브 액세스 계층” :
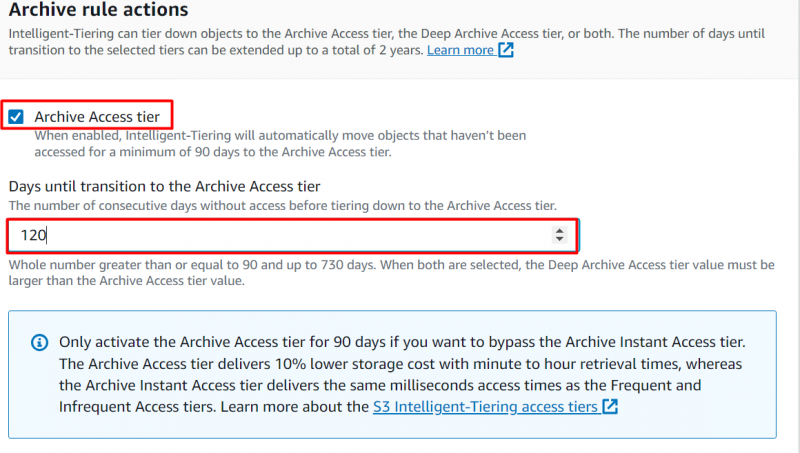
메모 : 최소한의 시간 동안 객체에 접근하지 않은 경우 90일, 객체는 자동으로 아카이브 액세스 계층으로 이동됩니다. 사용자는 이 기간을 다음으로 연장할 수 있습니다. 최고 ~의 730일.
9단계: 심층 아카이브 액세스 계층
아카이브 액세스 계층과 마찬가지로 사용자는 Deep Archive 액세스 계층도 구성할 수 있습니다. 다음 옵션을 활성화하여 개체를 Deep Archive Access Tier로 이동해야 하는 일 수를 제공합니다. 일수를 입력한 후 다음을 클릭하세요. '만들다' 단추:
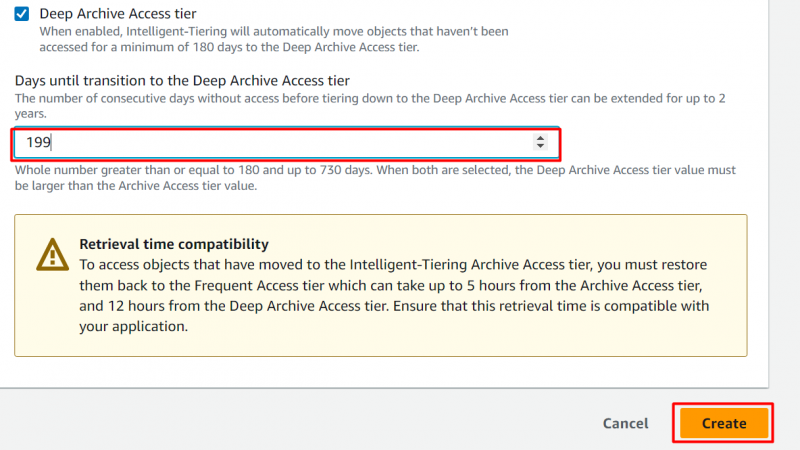
메모 : Deep Archive Access Tier에서는 일정 기간 동안 액세스되지 않은 개체입니다. 최소 180일 이 계층으로 이동됩니다. 사용자는 이 일수를 원하는 대로 맞춤 설정할 수 있습니다. 최대 730일 .
구성이 성공적으로 이루어졌습니다. 이제 지정된 시간 동안 사용자가 업로드된 객체에 액세스하지 않으면 지출을 최소화하기 위해 데이터가 자동으로 다른 계층으로 이동됩니다.
이것이 이 가이드의 전부입니다.
결론
S3 버킷을 사용한 비용 최적화를 위해 다음을 선택합니다. 지능형 계층화 클래스 파일을 업로드할 때 각 계층에 대한 시간을 제공하십시오. Intelligent-Tiering은 자주 액세스하는 개체와 거의 액세스하지 않는 개체를 각 계층으로 결정하여 비용을 절감합니다. 이 문서에서는 S3 버킷을 사용하여 비용 최적화 솔루션을 달성하기 위한 단계별 지침을 제공합니다.