데이터는 매일 엄청난 양으로 수집되며 빅데이터 관리는 Elasticsearch 엔진의 가장 중요한 사용 사례입니다. 데이터는 분석 데이터베이스에 실시간으로 저장되며 사용자는 쿼리를 사용하여 데이터를 추출하여 유용한 지식을 찾을 수 있습니다. 사용자는 쿼리를 적용하여 여러 인덱스에서 데이터를 찾고 관계형 데이터베이스에서 단일 버킷에 표시할 수 있습니다.
이 가이드는 다른 집계를 사용하는 예제와 함께 Elasticsearch 집계를 설명합니다.
Elasticsearch 집계란 무엇입니까?
Elasticsearch에서 집계는 필드를 결합하거나 그룹화하여 관계형 데이터베이스에서 정보를 추출하는 프로세스입니다. Elasticsearch의 집계는 다음과 같이 간주할 수 있습니다. 조항별로 그룹화 또는 골재() SQL 언어의 기능.
Elasticsearch 집계를 사용하는 방법?
Elasticsearch에서 집계를 사용하려면 사용자는 데이터베이스에 대한 기본적인 이해가 필요합니다. 구문과 실제 구현을 살펴보겠습니다.
통사론
데이터베이스에서 데이터를 찾기 위해 Elasticsearch 엔진의 집계 구문은 다음과 같습니다.
'에그' : {'name_of_aggregation' : {
'type_of_aggregation' : {
'필드' : '문서_필드_이름'
}
위의 스니펫:
-
- '를 사용합니다. 어그 ” 쿼리에서 집계의 사용을 설명하는 키워드입니다.
- 그만큼 name_of_aggregation 필요한 정보에 따라 사용자가 설정합니다.
- 그 후, type_of_aggregation 데이터를 가져오는 데 사용됩니다.
- 마지막 줄은 다음을 사용합니다. 필드 키워드 다음에 문서의 속성 이름이 옵니다.
예 1: Kibana 샘플 데이터의 집계
이 섹션에서는 먼저 연결하여 Kibana의 샘플 데이터를 사용하는 예제의 도움으로 집계를 설명합니다. 그런 다음 ' 개발 도구 ” 검색창에서 검색하고 클릭하면:
샘플 데이터에서 데이터 가져오기
다음 명령을 사용하여 '에서 데이터를 가져옵니다. kibana_sample_data_logs Dev Tools 콘솔의 ” 인덱스:
얻다 / kibana_sample_data_logs / _찾다
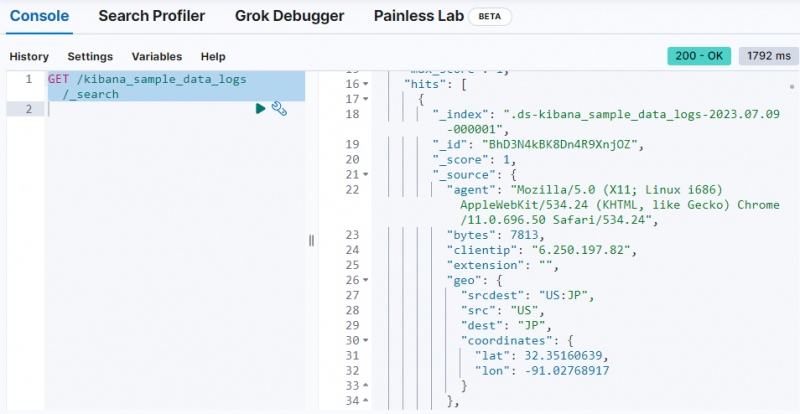
출력은 데이터가 ' kibana_sample_data_logs ' 색인.
다음 코드는 얻다 '에 대한 요청 kibana_sample_data_log ”에서 value_count 집계를 사용하여 검색합니다. 클라이언트 ' 필드:
얻다 / kibana_sample_data_logs / _찾다{ '크기' : 0 ,
'에그' : {
'ip_count' : {
'value_count' : {
'필드' : '클라이언트 팁'
}
}
}
}
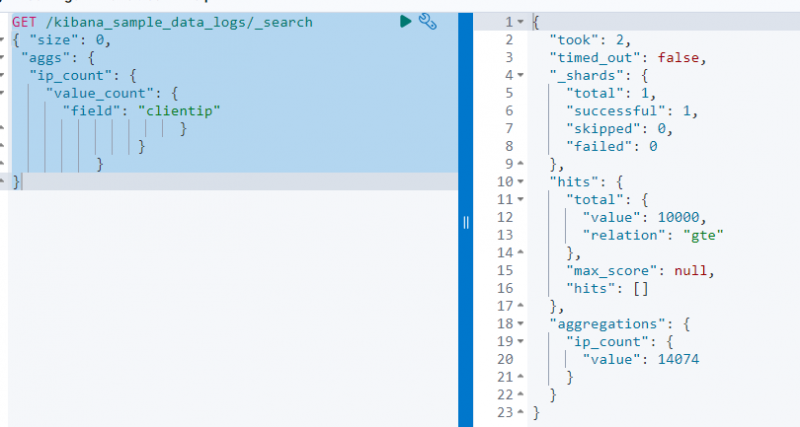
위의 스크린샷은 클라이언트 값이 있는 필드 14074 .
중요한 집계
데이터베이스에서 데이터를 효율적으로 찾는 데 사용되는 몇 가지 중요한 집계는 다음과 같습니다.
다음 예에서는 위에서 언급한 집계를 다음을 사용하여 설명합니다. 얻다 '에서 요청 kibana_sample_data_ecommerce ' 색인:
카디널리티 집계
다음 코드는 ' 카디널리티 '에 대한 집계 스쿠 ” 전자 상거래 데이터의 필드. 이 코드를 실행하면 단일 값 집계를 통해 Elasticsearch 데이터베이스에서 고유 SKU를 가져옵니다.
얻다 / kibana_sample_data_ecommerce / _찾다{
'크기' : 0 ,
'에그' : {
'unique_skus' : {
'카디널리티' : {
'필드' : 'sku'
}
}
}
}
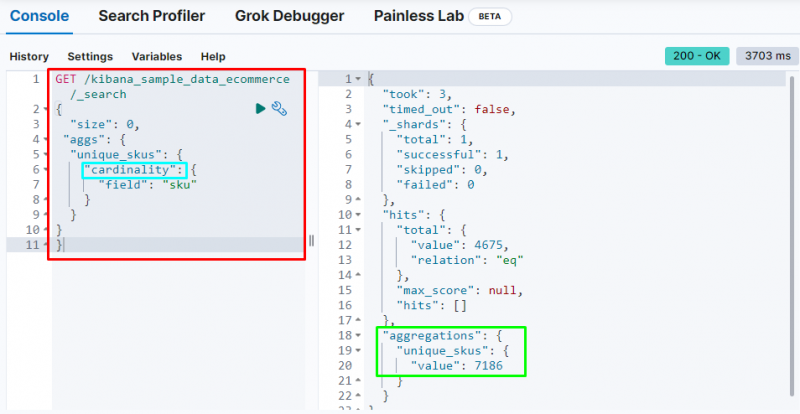
그것은 표시합니다 카디널리티 집계 찾기 7186개의 값 색인에서.
통계 집계
또 다른 중요한 집계는 ' 통계 '를 가져오는 데 사용되는 집계 세다 ”, “ 분 ”, “ 최대 ”, “ 평균 ', 그리고 ' 합집합 ”의 통계 총량 ' 필드:
얻다 / kibana_sample_data_ecommerce / _찾다{
'크기' : 0 ,
'에그' : {
'quantity_stats' : {
'통계' : {
'필드' : '총량'
}
}
}
}
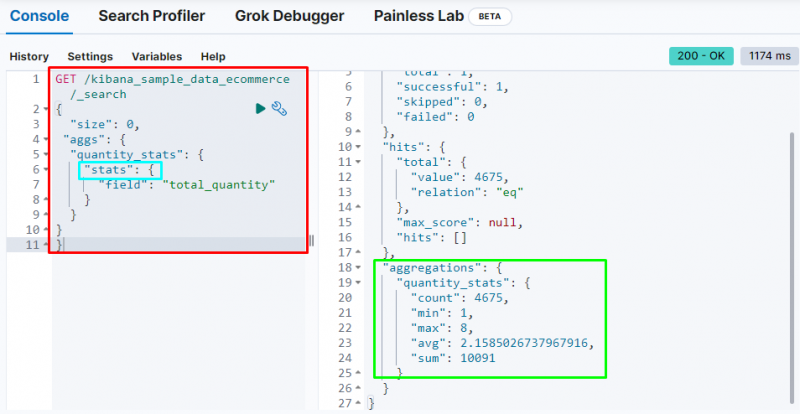
위의 스크린샷은 ' 총량 ' 필드.
필터 집계
필터 집계는 다음 코드에 포함된 데이터베이스의 용어 또는 구문을 기반으로 데이터를 필터링하는 데 사용됩니다.
얻다 / kibana_sample_data_ecommerce / _찾다{ '크기' : 0 ,
'에그' : {
'필터_집계' : {
'필터' : {
'용어' : {
'사용자' : '에디' } } ,
'에그' : {
'평균가격' : {
'평균' : {
'필드' : '제품.가격' } }
} } } }
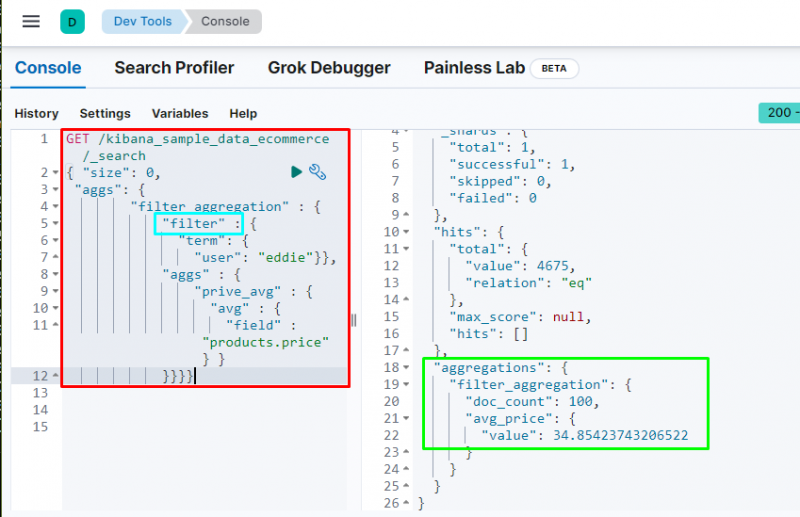
코드를 실행하면 ' 에디 ” 사용자가 구매한 상품의 평균 가격을 표시합니다. 위의 스크린샷은 사용자 찾았다 100 데이터와 값 의 평균 _ 가격 집합.
기간 집계
aggregation이라는 용어는 버킷을 생성하고 필드의 데이터를 버킷에 저장하며 다음 코드는 ' 사용자 ” 필드는 데이터를 버킷에 저장합니다.
얻다 / kibana_sample_data_ecommerce / _찾다{
'크기' : 0 ,
'에그' : {
'용어_집계' : {
'자귀' : {
'필드' : '사용자'
}
}
}
}
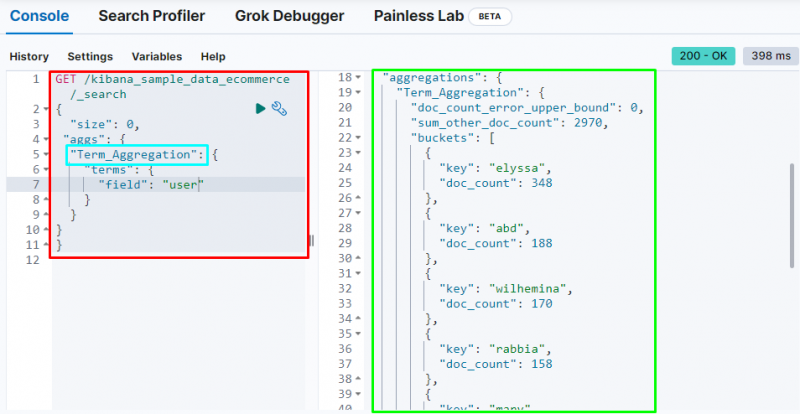
다음 스크린샷은 용어 집계가 각 사용자 및 해당 문서 수에 대한 버킷을 생성했음을 표시합니다.
이것이 Elasticsearch 집계 및 다른 중요한 집계에 관한 전부입니다.
결론
Elasticsearch에서 집계는 집계된 문서에서 데이터를 가져오는 데 사용되며 이러한 문서는 특정 필드에서 추출됩니다. 인덱스에서 유용한 통찰력을 얻는 데 사용되는 몇 가지 중요한 집계가 설명되어 있습니다. 이 가이드에서는 Elasticsearch 집계에 대해 설명하고 Elasticsearch 집계를 사용하는 프로세스를 시연했습니다.