Amazon Redshift는 데이터 웨어하우스의 목적을 충족하는 AWS에서 제공하는 클라우드 솔루션입니다. 데이터 웨어하우스는 엄청난 양의 데이터를 저장하는 클라우드의 큰 공간입니다. 데이터 웨어하우스와 데이터베이스의 차이점은 전자가 현재 데이터를 저장할 뿐만 아니라 데이터의 전체 기록도 저장한다는 것입니다.
이 기사에서는 AWS의 Amazon Redshift와 이 서비스가 지원하는 데이터 유형에 대해 알아봅니다.
아마존 레드시프트란?
데이터 웨어하우징을 기반으로 하는 클라우드 솔루션입니다. '포스트그레SQL' . 라는 기술을 사용합니다. '대량 병렬 처리(MPP)' 빛의 속도로 페타바이트의 데이터를 처리합니다. 이는 기록 데이터 및 스트리밍 솔루션을 기반으로 실시간 예측을 위한 손쉬운 솔루션을 제공합니다.
다음 그림은 Amazon Redshift의 작동 메커니즘을 보여줍니다.
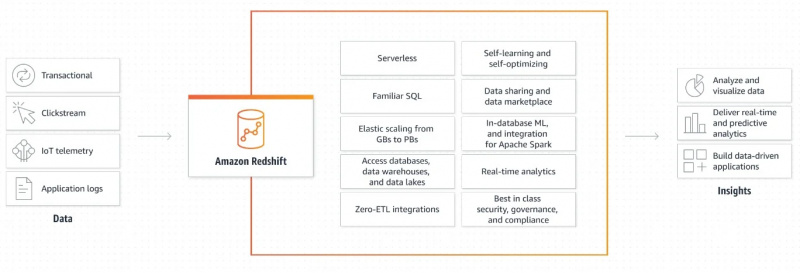
Amazon Redshift의 작동 방식에 대한 이 그래픽 설명은 매우 간단하고 명확합니다. 출력을 생성하고 데이터 기반 응용 프로그램을 만들기 위해 데이터를 검색하고 추가로 처리하는 방법에 대한 정보를 제공합니다.
Amazon Redshift의 데이터 웨어하우스 아키텍처는 아래 그림에서도 볼 수 있습니다.
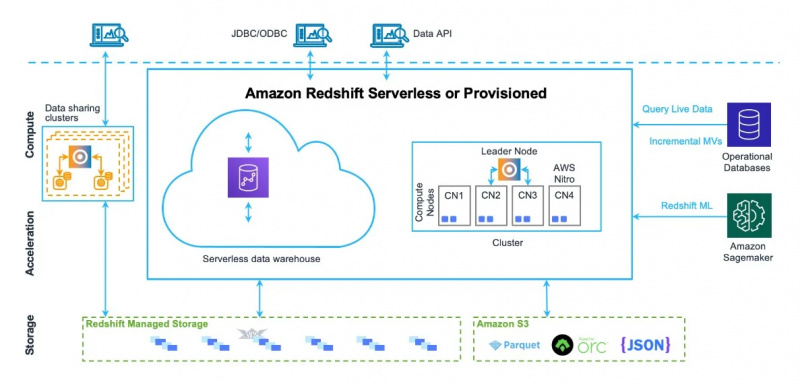
이제 이 서비스의 용도와 기능에 대해 알아보겠습니다.
특징
이미 언급한 바와 같이 Amazon Redshift는 PostgreSQL을 기반으로 하며 대량 병렬 처리라는 기술을 사용하여 페타바이트 규모의 데이터를 즉시 처리할 수 있습니다. 따라서 Redshift는 많은 기능과 용도를 제공합니다. 이러한 기능 중 일부는 다음과 같습니다.
- 데이터 보안 및 암호화.
- 비즈니스 분석.
- 데이터 기반 애플리케이션 지원.
- 예측 분석.
- 자동화된 작업 반복.
- 동시 데이터 스케일링.
- 데이터 웨어하우징.
이 서비스의 일부 추가 기능은 아래 그림에서 볼 수 있습니다.
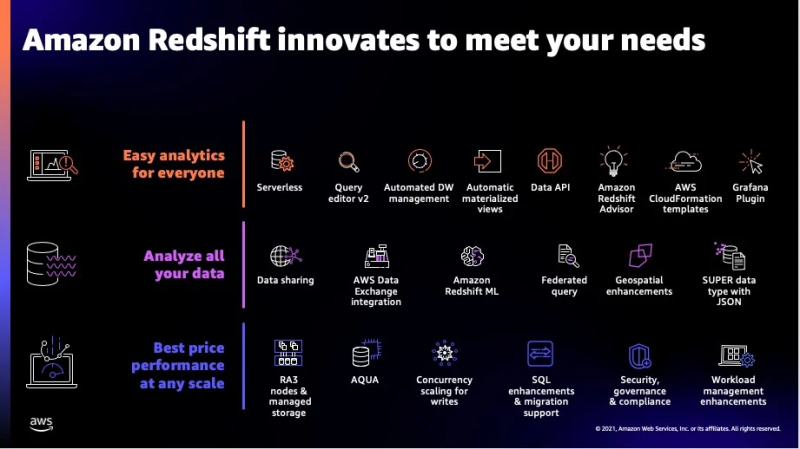
이는 Redshift가 제공하는 대부분의 기능이었으며 이제 이 서비스에서 지원하는 데이터 유형으로 이동하겠습니다.
데이터 유형
Amazon Redshift는 다양한 기능을 갖춘 데이터 웨어하우징 솔루션입니다. 구조화 및 비구조화 데이터 유형을 모두 지원합니다. PostgreSQL을 기반으로 하므로 간단한 SQL 쿼리를 통해 데이터를 조작할 수 있습니다.
이제 또 다른 질문이 생깁니다. 즉, 이러한 데이터 형식이 서로 어떻게 다릅니까? 이 두 가지 데이터 형식에 대해 살펴보겠습니다.
구조화된 데이터
기계 학습 알고리즘으로 쉽게 변환되는 고도로 형식화된 데이터 유형을 구조화된 데이터라고 합니다. SQL 데이터베이스는 구조화된 데이터와 함께 작동합니다. 구조화된 데이터는 관계형 데이터베이스에서 사용하는 데이터와 같은 테이블 형식입니다.
널리 사용되는 SQL 데이터베이스 관리 시스템 중 하나는 MYSQL입니다. 아키텍처는 주어진 그림에서 아래에서 볼 수 있습니다.
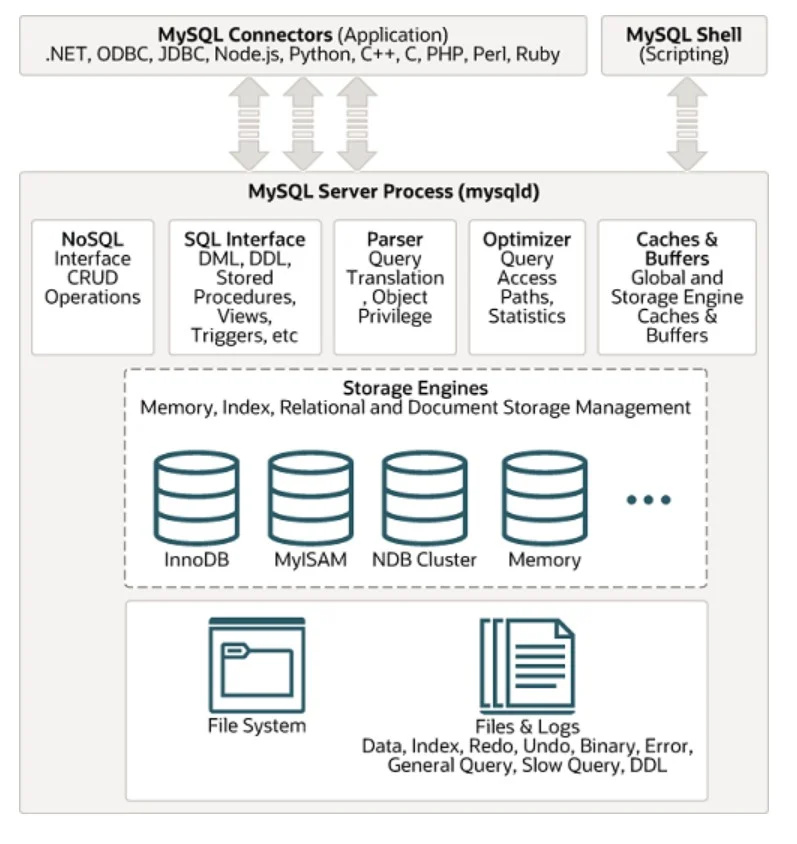
구조화되지 않은 데이터
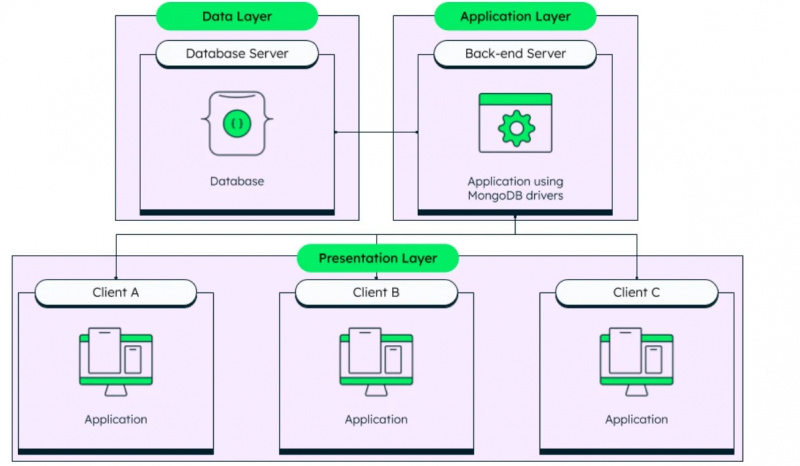
구조화되지 않은 데이터는 비관계형 데이터베이스에서 사용되는 데이터와 같이 패턴이 없고 형식이 없는 데이터입니다. MongoDB는 유명한 비관계형 데이터베이스입니다. SQL 쿼리는 비관계형 데이터베이스에서 작동하지 않으므로 이러한 데이터베이스를 NoSQL 데이터베이스라고도 합니다.
이미 언급했듯이 MongoDB는 구조화되지 않은 데이터베이스 관리 시스템이며 해당 아키텍처는 주어진 그림에서 아래에서 볼 수 있습니다.
데이터베이스에서 사용되는 두 가지 기본 데이터 유형을 살펴보았으며 이제 Amazon Redshift에서 지원하는 실제 데이터 유형으로 이동하겠습니다. 이러한 데이터 유형은 다음과 같습니다.
- 숫자 데이터
- 문자 데이터
- 날짜/시간 데이터
- 부울 데이터
- HLLSKETCH 데이터
- 슈퍼 데이터
- 교체 데이터
다음 데이터 유형에 대해 논의해 보겠습니다.
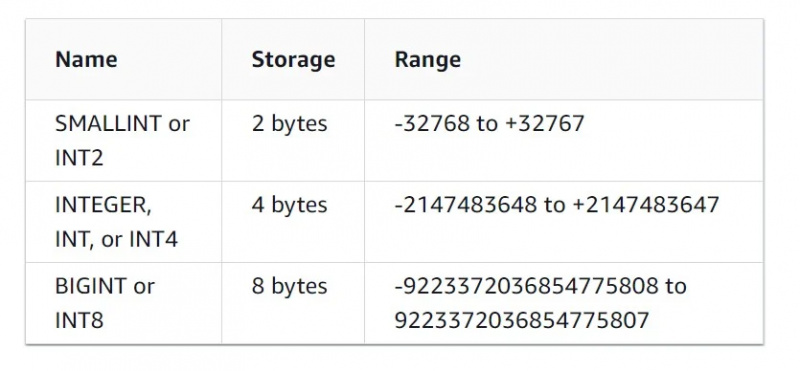
숫자 데이터
이 데이터 유형은 자명합니다. 정수, 10진수, 부동 소수점 및 기타 숫자 데이터 형식의 데이터를 지원합니다.
정수 데이터 유형의 특성은 아래 그림에서 볼 수 있습니다.
10진수 데이터 유형은 사용자의 정밀도를 기준으로 데이터를 저장합니다. 그 특성은 다음과 같습니다.

문자 데이터
CHAR 및 VARCHAR 데이터 유형은 문자 기반 데이터 유형 범주에 속합니다. NCHAR 및 NVARCHAR도 문자 유형 데이터 유형입니다. CHAR 및 VARCHAR와 달리 이 두 데이터 유형은 고정 길이의 유니코드 문자를 저장합니다. 다음과 같은 이러한 데이터 유형의 속성을 살펴보겠습니다.
- CHAR, CHARACTER, NCHAR의 범위는 4KB입니다.
- VARCHAR, NVARCHAR의 범위는 64KB입니다.
- BPCHAR의 범위는 256바이트입니다.
- TEXT의 범위는 260바이트입니다.
날짜/시간 데이터
날짜/시간 데이터 유형은 DATE, TIME, TIMETZ, TIMESTAMP, TIMESTAMPTZ입니다. 이러한 데이터 유형의 기능적 기능은 다음과 같습니다.
- DATE는 단순히 달력 날짜를 저장합니다.
- TIME은 시간대를 참조하지 않고 시간을 저장합니다. 기본적으로 UTC입니다.
- TIMETZ는 시간대를 기준으로 시간을 저장합니다. 기본적으로 사용자 테이블과 시스템 테이블 모두에서 UTC입니다.
- TIMESTAMP는 시간뿐만 아니라 날짜도 포함합니다. 기본적으로 사용자 테이블과 시스템 테이블 모두에서 UTC입니다.
- TIMESTAMPTZ는 시간뿐만 아니라 날짜도 포함합니다. 기본적으로 사용자 테이블에서만 UTC입니다.
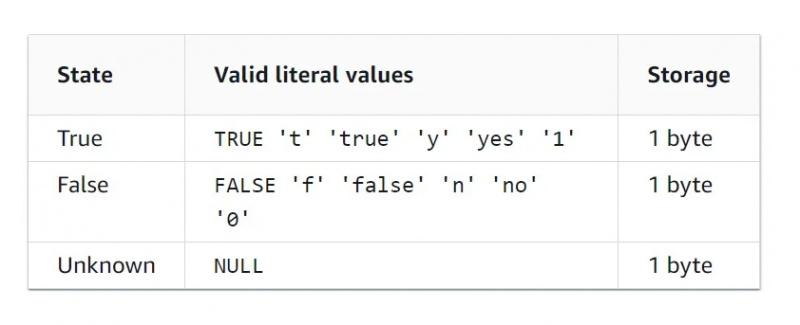
부울 데이터
Boolean 데이터 유형은 값이 두 개뿐인 이진 데이터 유형입니다. 부울 데이터 유형의 특성 테이블은 아래 그림에 나와 있습니다.
HLLSKETCH 데이터
이 데이터 유형은 스케치를 저장하는 데 사용됩니다. Redshift는 희박하거나 조밀한 형태로 스케치를 나타낼 수 있습니다. 스케치는 희박하게 시작하여 밀도가 높은 형식이 링크를 따라가면 더 많은 효율성을 제공할 때 점차 밀도가 높아집니다.
슈퍼데이터
이 데이터 유형은 배열, 중첩 구조 또는 JSON 형식일 수 있는 구조화되지 않은 데이터를 처리합니다. 데이터의 모델이나 형식이 없습니다. 사용자는 링크를 탐색하여 더 많은 정보를 탐색할 수 있습니다.
교체 데이터
이 데이터 유형은 문자도 저장합니다. 그러나 길이는 제한되어 있습니다. Amazon Redshift는 VARBYTE 데이터를 모든 정수 유형 또는 문자 유형 데이터로 캐스팅할 수 있습니다. 이 데이터 유형에 대한 자세한 내용을 보려면 아래 링크를 따르십시오.
이것이 Amazon Redshift와 이것이 지원하는 데이터 유형의 전부입니다.
결론
Amazon Redshift는 기본 형태로 데이터 웨어하우스의 목적을 수행하지만 분석 및 예측을 위한 매우 강력하고 기능이 뛰어난 솔루션인 AWS 서비스입니다. 이 기사에서는 Redshift와 Redshift가 지원하는 데이터 유형에 대해 설명했습니다. 이러한 데이터 유형은 특성과 함께 간략하게 설명되었습니다.