6.1 소개
최신 범용 컴퓨터에는 CISC와 RISC의 두 가지 유형이 있습니다. CISC는 Complex Instruction Set Computer의 약자입니다. RISK는 축소 명령 집합 컴퓨터(Reduced Instruction Set Computer)를 나타냅니다. Commodore-64 컴퓨터에 적용할 수 있는 6502 또는 6510 마이크로프로세서는 CISC 아키텍처보다 RISC 아키텍처와 더 유사합니다.
RISC 컴퓨터는 일반적으로 CISC 컴퓨터에 비해 어셈블리 언어 명령어(바이트 수 기준)가 더 짧습니다.
메모 : CISC, RISC, 구형 컴퓨터 등 주변기기는 내부 포트에서 시작하여 컴퓨터의 시스템 유닛(베이스 유닛) 수직면에 있는 외부 포트를 거쳐 외부 장치로 나갑니다.
CISC 컴퓨터의 일반적인 명령어는 여러 개의 짧은 어셈블리 언어 명령어를 하나의 긴 어셈블리 언어 명령어로 결합하여 결과 명령어를 복잡하게 만드는 것처럼 보일 수 있습니다. 특히 CISC 컴퓨터는 메모리에서 마이크로프로세서 레지스터로 피연산자를 로드하고 연산을 수행한 다음 결과를 다시 메모리에 저장합니다. 이 모든 것이 하나의 명령으로 이루어집니다. 반면에 RISC 컴퓨터의 경우 이는 최소 3개의 명령어(짧음)입니다.
CISC 컴퓨터에는 Intel 마이크로프로세서 컴퓨터와 AMD 마이크로프로세서 컴퓨터라는 두 가지 인기 있는 시리즈가 있습니다. AMD는 Advanced Micro Devices의 약자입니다. 반도체 제조회사입니다. Intel 마이크로프로세서 시리즈는 개발 순서대로 8086, 8088, 80186, 80286, 80386, 80486, Pentium, Core, i 시리즈, Celeron, Xeon입니다. 8086, 8088 등 초기 인텔 마이크로프로세서의 어셈블리 언어 명령어는 그다지 복잡하지 않습니다. 그러나 새로운 마이크로프로세서의 경우에는 복잡합니다. 최근 CISC 시리즈용 AMD 마이크로프로세서는 Ryzen, Opteron, Athlon, Turion, Phenom 및 Sempron입니다. Intel 및 AMD 마이크로프로세서는 x86 마이크로프로세서로 알려져 있습니다.
ARM은 고급 RISC 머신을 의미합니다. ARM 아키텍처는 다양한 애플리케이션에 사용하기에 적합한 RISC 프로세서 제품군을 정의합니다. 많은 Intel 및 AMD 마이크로프로세서가 데스크톱 개인용 컴퓨터에 사용되는 반면, 많은 ARM 프로세서는 자동차 잠김 방지 브레이크와 같은 안전 필수 시스템의 내장형 프로세서 및 스마트워치, 휴대전화, 태블릿, 노트북 컴퓨터의 범용 프로세서로 사용됩니다. . 두 가지 유형의 마이크로프로세서 모두 소형 및 대형 장치에서 볼 수 있지만 RISC 마이크로프로세서는 대형 장치보다 소형 장치에서 더 많이 발견됩니다.
컴퓨터 워드
컴퓨터를 32비트 워드의 컴퓨터라고 하면 마더보드 내부에 32비트 바이너리 코드 형태로 정보가 저장, 전송, 조작된다는 뜻이다. 이는 또한 컴퓨터 마이크로프로세서의 범용 레지스터가 32비트 폭이라는 것을 의미합니다. 6502 마이크로프로세서의 A, X, Y 레지스터는 범용 레지스터입니다. 폭이 8비트이므로 Commodore-64 컴퓨터는 8비트 워드 컴퓨터입니다.
일부 어휘
X86 컴퓨터
x86 컴퓨터에서 바이트, 워드, 더블워드, 쿼드워드, 더블쿼드워드의 의미는 다음과 같습니다.
- 바이트 : 8비트
- 단어 : 16비트
- 더블워드 : 32비트
- 쿼드워드 : 64비트
- 이중 쿼드워드 : 128비트
ARM 컴퓨터
ARM 컴퓨터에서 바이트, 하프워드, 워드 및 더블워드의 의미는 다음과 같습니다.
- 바이트 : 8비트
- 반이 되다 : 16비트
- 단어 : 32비트
- 더블워드 : 64비트
x86 및 ARM 이름(및 값)의 차이점과 유사점에 유의해야 합니다.
메모 : 두 컴퓨터 유형 모두의 부호 정수는 2의 보수입니다.
메모리 위치
Commodore-64 컴퓨터의 경우 메모리 위치는 일반적으로 1바이트이지만 포인터(간접 주소 지정)를 고려할 때 경우에 따라 2개의 연속 바이트가 될 수도 있습니다. 최신 x86 컴퓨터의 메모리 위치는 16바이트(128비트)의 더블 쿼드워드를 처리할 때 연속 16바이트, 8바이트(64비트)의 쿼드워드를 처리할 때 8연속 바이트, 더블워드(64비트)를 처리할 때 4연속 바이트입니다. 4바이트(32비트), 2바이트(16비트)의 워드를 처리할 때는 연속 2바이트, 1바이트(8비트)를 처리할 때는 1바이트입니다. 최신 ARM 컴퓨터의 메모리 위치는 8바이트(64비트)의 더블워드를 처리할 때 연속 8바이트, 4바이트(32비트)의 워드를 처리할 때 연속 4바이트, 하프워드를 처리할 때 연속 2바이트입니다. 2바이트(16비트)이고, 1바이트(8비트)를 처리할 때는 1바이트입니다.
이 장에서는 CISC 및 RISC 아키텍처의 공통점과 차이점을 설명합니다. 이는 6502 µP 및 해당되는 Commodore-64 컴퓨터와 비교하여 수행됩니다.
6.2 최신 PC의 마더보드 블록 다이어그램
PC는 개인용 컴퓨터를 의미합니다. 다음은 개인용 컴퓨터용 단일 마이크로프로세서를 갖춘 최신 마더보드의 일반적인 기본 블록 다이어그램입니다. CISC 또는 RISC 마더보드를 나타냅니다.
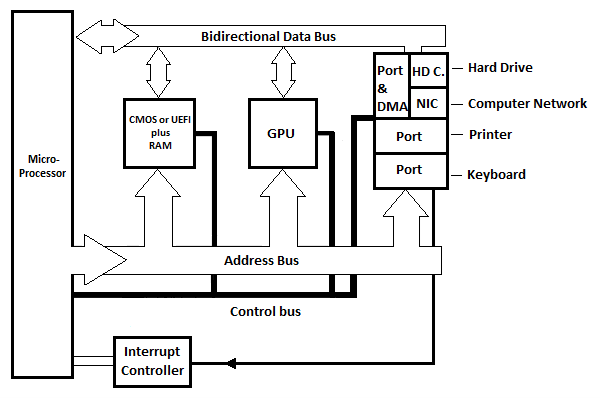
그림 6.21 최신 PC의 기본 마더보드 블록 다이어그램
다이어그램에는 3개의 내부 포트가 표시되어 있지만 실제로는 더 많은 포트가 있습니다. 각 포트에는 포트 자체로 볼 수 있는 레지스터가 있습니다. 각 포트 회로에는 '상태 레지스터'라고 부를 수 있는 또 다른 레지스터가 하나 이상 있습니다. 상태 레지스터는 마이크로프로세서에 인터럽트 신호를 보내는 프로그램의 포트를 나타냅니다. 서로 다른 포트의 서로 다른 인터럽트 라인을 구별하고 µP에 대한 몇 개의 라인만 갖는 인터럽트 컨트롤러 회로(표시되지 않음)가 있습니다.
다이어그램의 HD.C는 하드 드라이브 카드를 나타냅니다. NIC는 네트워크 인터페이스 카드를 나타냅니다. 하드 드라이브 카드(회로)는 최신 컴퓨터의 기본 장치(시스템 장치) 내부에 있는 하드 드라이브에 연결됩니다. 네트워크 인터페이스 카드(회로)는 외부 케이블을 통해 다른 컴퓨터에 연결됩니다. 다이어그램에는 하드 디스크 카드 및/또는 네트워크 인터페이스 카드에 연결된 포트 하나와 DMA(다음 그림 참조)가 있습니다. DMA는 직접 메모리 액세스를 나타냅니다.
Commodore-64 컴퓨터 장에서 메모리의 바이트를 디스크 드라이브나 다른 컴퓨터로 전송하려면 각 바이트를 해당 내부 포트에 복사하기 전에 마이크로프로세서의 레지스터에 복사한 다음 자동으로 복사해야 한다는 점을 기억하십시오. 장치에. 디스크 드라이브나 다른 컴퓨터에서 메모리로 바이트를 수신하려면 각 바이트를 메모리에 복사하기 전에 해당 내부 포트 레지스터에서 마이크로프로세서 레지스터로 복사해야 합니다. 스트림의 바이트 수가 많으면 일반적으로 시간이 오래 걸립니다. 빠른 전송을 위한 솔루션은 마이크로프로세서를 통하지 않고 직접 메모리 액세스(회로)를 사용하는 것입니다.
DMA 회로는 포트와 HD 사이에 있습니다. C 또는 NIC. DMA 회로의 직접적인 메모리 액세스를 통해 대규모 바이트 스트림의 전송은 마이크로프로세서의 지속적인 참여 없이 DMA 회로와 메모리(RAM) 사이에서 직접 이루어집니다. DMA는 µP 대신 주소 버스와 데이터 버스를 사용합니다. 전체 전송 기간은 µP 하드를 사용하는 경우보다 짧습니다. HD C나 NIC 모두 RAM(메모리)으로 전송하기 위한 대용량 데이터 스트림(바이트)이 있는 경우 DMA를 사용합니다.
GPU는 그래픽 처리 장치를 의미합니다. 마더보드의 이 블록은 텍스트와 동영상 또는 정지 이미지를 화면으로 보내는 역할을 합니다.
최신 컴퓨터(PC)에는 읽기 전용 메모리(ROM)가 없습니다. 그러나 일종의 비휘발성 RAM인 BIOS 또는 UEFI가 있습니다. BIOS의 정보는 실제로 배터리에 의해 유지됩니다. 배터리는 실제로 컴퓨터에 적합한 시간과 날짜에 시계 타이머를 유지하는 역할도 합니다. UEFI는 BIOS 이후에 발명되었으며 BIOS를 대체했지만 BIOS는 여전히 최신 PC와 관련이 있습니다. 이에 대해서는 나중에 더 자세히 논의하겠습니다!
최신 PC에서 µP와 내부 포트 회로(및 메모리) 사이의 주소 및 데이터 버스는 병렬 버스가 아닙니다. 이는 한 방향으로 전송하기 위해 두 개의 도체와 반대 방향으로 전송하기 위해 또 다른 두 개의 도체가 필요한 직렬 버스입니다. 예를 들어, 이는 32비트가 어느 방향으로든 직렬로(1비트씩) 전송될 수 있음을 의미합니다.
직렬 전송이 두 개의 컨덕터(두 개의 라인)를 사용하여 한 방향으로만 이루어지는 경우 이를 반이중이라고 합니다. 직렬 전송이 4개의 컨덕터(어느 방향이든 한 쌍)를 사용하여 양방향으로 전송되는 경우 이를 전이중이라고 합니다.
현대 컴퓨터의 전체 메모리는 여전히 일련의 바이트 위치(바이트당 8비트)로 구성됩니다. 최신 컴퓨터의 메모리 공간은 최소 4GB = 4 x 210 x 2입니다. 10 x 2 10 = 4 x 1,073,741,824 10 바이트 = 4 x 1024 10/하위> x 1024 10 x 1024 10 = 4 x 1,073,741,824 10 .
메모 : 이전 마더보드에는 타이머 회로가 표시되지 않았지만 최신 마더보드에는 모두 타이머 회로가 있습니다.
6.3 x64 컴퓨터 아키텍처 기본
6.31 x64 레지스터 세트
x86 마이크로프로세서 시리즈 중 64비트 마이크로프로세서는 64비트 마이크로프로세서입니다. 동일한 시리즈의 32비트 프로세서를 교체하는 것은 상당히 현대적입니다. 64비트 마이크로프로세서의 범용 레지스터와 그 이름은 다음과 같습니다.
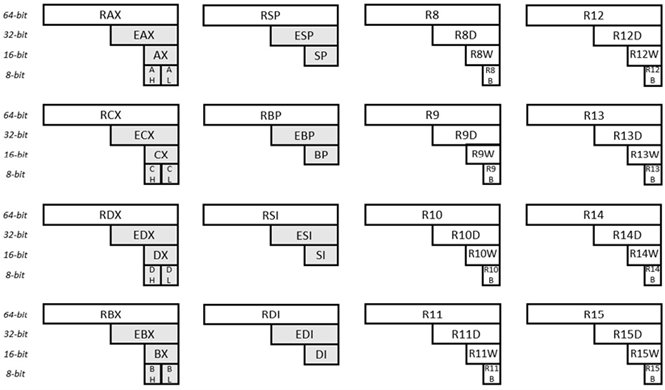
그림 6.31 x64용 범용 레지스터
주어진 그림에는 16개의 범용 레지스터가 표시되어 있습니다. 각 레지스터의 너비는 64비트입니다. 왼쪽 상단의 레지스터를 보면 64비트가 RAX로 식별됩니다. 동일한 레지스터의 처음 32비트(오른쪽부터)는 EAX로 식별됩니다. 동일한 레지스터의 처음 16비트(오른쪽부터)는 AX로 식별됩니다. 동일한 레지스터의 두 번째 바이트(오른쪽부터)는 AH로 식별됩니다(여기서 H는 높음을 의미함). 그리고 (이 동일한 레지스터의) 첫 번째 바이트는 AL로 식별됩니다(여기서 L은 낮음을 의미함). 오른쪽 하단의 레지스터를 보면 64비트가 R15로 식별됩니다. 동일한 레지스터의 처음 32비트는 R15D로 식별됩니다. 동일한 레지스터의 처음 16비트는 R15W로 식별됩니다. 첫 번째 바이트는 R15B로 식별됩니다. 다른 레지스터(및 하위 레지스터)의 이름도 유사하게 설명됩니다.
Intel과 AMD µP 간에는 몇 가지 차이점이 있습니다. 이 섹션의 정보는 Intel에 대한 것입니다.
6502 µP의 경우 다음에 실행될 명령을 저장하는 프로그램 카운터 레지스터(직접 액세스할 수 없음)의 폭은 16비트입니다. 여기(x64)에서 프로그램 카운터는 명령어 포인터(Instruction Pointer)라고 불리며, 너비는 64비트입니다. RIP라고 표시되어 있습니다. 이는 x64 µP가 최대 264 = 1.844674407 x 1019(실제로는 18,446,744,073,709,551,616) 메모리 바이트 위치를 처리할 수 있음을 의미합니다. RIP는 범용 레지스터가 아닙니다.
스택 포인터 레지스터(RSP)는 16개의 범용 레지스터 중 하나입니다. 이는 메모리의 마지막 스택 항목을 가리킵니다. 6502 µP와 마찬가지로 x64의 스택은 아래쪽으로 늘어납니다. x64에서는 RAM의 스택이 서브루틴의 반환 주소를 저장하는 데 사용됩니다. 또한 '그림자 공간'을 저장하는 데에도 사용됩니다(다음 설명 참조).
6502 µP에는 8비트 프로세서 상태 레지스터가 있습니다. x64에서 이에 상응하는 것을 RFLAGS 레지스터라고 합니다. 이 레지스터는 연산 결과와 프로세서(μP) 제어에 사용되는 플래그를 저장합니다. 너비는 64비트입니다. 상위 32비트는 예약되어 있으며 현재 사용되지 않습니다. 다음 표는 RFLAGS 레지스터에서 일반적으로 사용되는 비트의 이름, 인덱스 및 의미를 제공합니다.
| 표 6.31.1 가장 많이 사용되는 RFLAGS 플래그(비트) |
|||
|---|---|---|---|
| 상징 | 조금 | 이름 | 목적 |
| CF | 0 | 나르다 | 산술 연산이 결과의 최상위 비트에서 캐리 또는 빌림을 생성하는 경우 설정됩니다. 그렇지 않으면 지워집니다. 이 플래그는 부호 없는 정수 연산의 오버플로 조건을 나타냅니다. 다중 정밀도 연산에도 사용됩니다. |
| PF | 2 | 동등 | 결과의 최하위 바이트에 짝수 1비트가 포함된 경우 설정됩니다. 그렇지 않으면 지워집니다. |
| 의 | 4 | 조정하다 | 산술 연산이 결과의 비트 3에서 캐리 또는 차용을 생성하는 경우 설정됩니다. 그렇지 않으면 지워집니다. 이 플래그는 BCD(Binary-Coded Decimal) 연산에 사용됩니다. |
| ZF | 6 | 영 | 결과가 0이면 설정됩니다. 그렇지 않으면 지워집니다. |
| SF | 7 | 징후 | 부호 있는 정수의 부호 비트(0은 양수, 1은 음수)인 결과의 최상위 비트와 같을 경우 설정됩니다. |
| 의 | 열하나 | 과다 | 정수 결과가 대상 피연산자에 맞추기에는 너무 큰 양수이거나 너무 작은 음수(부호 비트 제외)인 경우 설정됩니다. 그렇지 않으면 지워집니다. 이 플래그는 부호 있는 정수(2의 보수) 산술에 대한 오버플로 조건을 나타냅니다. |
| DF | 10 | 방향 | 방향 문자열 명령어가 동작(증가 또는 감소)하는지 여부가 설정됩니다. |
| ID | 이십 일 | 신분증 | 변경 가능성이 CPUID 명령의 존재를 나타내는 경우 설정됩니다. |
이전에 표시된 18개의 64비트 레지스터 외에도 x64 아키텍처 µP에는 부동 소수점 연산을 위한 8개의 80비트 폭 레지스터가 있습니다. 이 8개 레지스터는 MMX 레지스터로도 사용할 수 있습니다(다음 설명 참조). XMM용 16개의 128비트 레지스터도 있습니다(다음 설명 참조).
이것이 레지스터의 전부는 아닙니다. 세그먼트 레지스터(대부분 x64에서는 사용되지 않음), 제어 레지스터, 메모리 관리 레지스터, 디버그 레지스터, 가상화 레지스터, 모든 종류의 내부 매개변수(캐시 적중/실패, 마이크로 연산 실행, 타이밍)를 추적하는 성능 레지스터인 x64 레지스터가 더 있습니다. , 그리고 훨씬 더).
심드
SIMD는 단일 명령 다중 데이터를 나타냅니다. 이는 하나의 어셈블리 언어 명령어가 하나의 마이크로프로세서에서 동시에 여러 데이터에 대해 작동할 수 있음을 의미합니다. 다음 표를 고려하십시오.
| 1 | 2 | 삼 | 4 | 5 | 6 | 7 | 8 | |
| + | 9 | 10 | 열하나 | 12 | 13 | 14 | 열 다섯 | 16 |
| = | 10 | 12 | 14 | 16 | 18 | 이십 | 22 | 24 |
이 표에서는 8개의 숫자 쌍이 병렬로(동일한 기간 동안) 추가되어 8개의 답을 제공합니다. 하나의 어셈블리 언어 명령어는 MMX 레지스터에서 8개의 병렬 정수 추가를 수행할 수 있습니다. XMM 레지스터를 사용하여 비슷한 작업을 수행할 수 있습니다. 따라서 정수에 대한 MMX 명령어와 부동 소수점에 대한 XMM 명령어가 있습니다.
6.32 메모리 맵과 x64
64비트를 갖는 명령어 포인터(프로그램 카운터)를 사용하면 이는 264 = 1.844674407 x 1019 메모리 바이트 위치가 주소 지정될 수 있음을 의미합니다. 16진수에서 가장 높은 바이트 위치는 FFFF,FFFF,FFFF,FFFF16입니다. 오늘날 어떤 일반 컴퓨터도 이렇게 큰 메모리(완전한) 공간을 제공할 수 없습니다. 따라서 x64 컴퓨터에 적합한 메모리 맵은 다음과 같습니다.

0000,8000,0000,000016에서 FFFF,7FFF,FFFF,FFFF16까지의 간격에는 메모리 위치가 없습니다(메모리 RAM 뱅크 없음). 이는 FFFF,0000,0000,000116만큼의 차이로 꽤 크다. 정식 상위 절반에는 운영 체제가 있고, 정식 하위 절반에는 사용자 프로그램(응용 프로그램)과 데이터가 있습니다. 운영 체제는 작은 UEFI(BIOS)와 하드 드라이브에서 로드되는 큰 부분의 두 부분으로 구성됩니다. 다음 장에서는 최신 운영 체제에 대해 자세히 설명합니다. 이 메모리 맵과 64KB가 많은 메모리처럼 보일 수 있는 Commodore-64의 유사점에 유의하세요.
이러한 맥락에서 운영 체제는 대략 '커널'이라고 불립니다. 커널은 Commodore-64 컴퓨터의 커널과 유사하지만 훨씬 더 많은 서브루틴이 있습니다.
x64의 엔디안은 리틀 엔디안입니다. 즉, 위치의 경우 하위 주소가 메모리의 하위 콘텐츠 바이트를 가리킵니다.
6.33 x64용 어셈블리 언어 주소 지정 모드
주소 지정 모드는 명령어가 µP 레지스터와 메모리(내부 포트 레지스터 포함)에 액세스할 수 있는 방법입니다. x64에는 다양한 주소 지정 모드가 있지만 여기서는 일반적으로 사용되는 주소 지정 모드만 다룹니다. 여기서 명령어의 일반적인 구문은 다음과 같습니다.
opcode 대상, 소스
십진수는 접두사나 접미사 없이 작성됩니다. 6502에서는 소스가 암시적입니다. x64에는 6502보다 더 많은 연산 코드가 있지만 일부 연산 코드에는 동일한 니모닉이 있습니다. 개별 x64 명령어는 가변 길이이며 크기 범위는 1~15바이트입니다. 일반적으로 사용되는 주소 지정 모드는 다음과 같습니다.
즉시 주소 지정 모드
여기서 소스 피연산자는 주소나 레이블이 아닌 실제 값입니다. 예(댓글 읽기):
EAX 추가, 14 ; 64비트 RAX의 32비트 EAX에 10진수 14를 추가하면 답은 EAX(대상)에 남습니다.
주소 지정 모드를 등록하려면 등록하세요.
예:
R8B, AL 추가; RAX의 8비트 AL을 64비트 R8의 R8B에 추가 - 답변은 R8B(대상)에 남아 있음
간접 및 인덱스 주소 지정 모드
6502 µP를 사용한 간접 주소 지정은 명령어에서 주어진 주소의 위치가 최종 위치의 유효 주소(포인터)를 갖는다는 것을 의미합니다. x64에서도 비슷한 일이 발생합니다. 6502 µP를 사용한 인덱스 주소 지정은 유효 주소를 갖기 위해 µP 레지스터의 내용이 명령어의 지정된 주소에 추가된다는 의미입니다. x64에서도 비슷한 일이 발생합니다. 또한 x64를 사용하면 레지스터의 내용을 지정된 주소에 추가하기 전에 1, 2, 4 또는 8을 곱할 수도 있습니다. x64의 mov(복사) 명령은 간접 주소 지정과 인덱스 주소 지정을 모두 결합할 수 있습니다. 예:
MOV R8W, 1234[8*RAX+RCX] ; 주소에서 워드 이동(8 x RAX + RCX) + 1234
여기서 R8W에는 R8의 첫 번째 16비트가 있습니다. 주어진 주소는 1234입니다. RAX 레지스터에는 8을 곱한 64비트 숫자가 있습니다. 결과는 64비트 RCX 레지스터의 내용에 추가됩니다. 이 두 번째 결과는 유효 주소를 얻기 위해 주어진 주소인 1234에 추가됩니다. 유효 주소 위치의 숫자는 R8 레지스터의 첫 번째 16비트 위치(R8W)로 이동(복사)되어 거기에 있던 모든 것을 대체합니다. 대괄호 사용에 유의하세요. x64의 한 단어는 16비트 너비라는 점을 기억하세요.
RIP 상대 주소 지정
6502 µP의 경우 상대 주소 지정은 분기 명령에만 사용됩니다. 여기에서 opcode의 단일 피연산자는 유효 명령어 주소(데이터 주소가 아님)에 대한 프로그램 카운터의 내용에 더하거나 빼는 오프셋입니다. 프로그램 카운터가 명령어 포인터라고 불리는 x64에서도 비슷한 일이 발생합니다. x64 명령어는 분기 명령어일 필요는 없습니다. RIP 상대 주소 지정의 예는 다음과 같습니다.
이동 알, [RIP]
RAX의 AL에는 다음 명령어를 가리키기 위해 RIP(64비트 명령어 포인터)의 내용에 더하거나 빼는 8비트 부호 있는 숫자가 있습니다. 이 명령어에서는 소스와 대상이 예외적으로 교체된다는 점에 유의하세요. 또한 RIP의 내용을 나타내는 대괄호 사용에 유의하세요.
6.34 x64에서 일반적으로 사용되는 명령어
다음 표에서 *는 opcode 하위 집합의 가능한 다양한 접미사를 의미합니다.
| 표 6.34.1 x64에서 일반적으로 사용되는 명령어 |
|
|---|---|
| 연산코드 | 의미 |
| MOV | 메모리와 레지스터 간 이동(복사) |
| CMOV* | 다양한 조건부 이동 |
| XCHG | 교환 |
| BSWAP | 바이트 스왑 |
| 푸시/팝 | 스택 사용량 |
| 추가/ADC | 추가/캐리 포함 |
| 서브/SBC | 빼기/캐리 포함 |
| 멀/이뮬 | 곱하기/부호 없는 |
| DIV/IDIV | 분할/부호 없음 |
| 증가/감소 | 증가/감소 |
| 네거티브 | 부정 |
| CMP | 비교하다 |
| AND/OR/XOR/NOT | 비트별 연산 |
| SHR/SAR | 오른쪽으로 시프트 논리/산술 |
| SHL/SAL | 왼쪽으로 시프트 논리/산술 |
| ROR/역할 | 오른쪽/왼쪽으로 회전 |
| RCR/RCL | 캐리비트를 통해 좌/우 회전 |
| BT/방탄소년단/BTR | 비트 테스트/및 설정/및 재설정 |
| JMP | 무조건 점프 |
| JE/JNE/JC/JNC/J* | 같음/같지 않음/나르기/나르지 않음/기타 다수일 경우 점프 |
| 걷기/걷기/걷기 | ECX를 사용한 루프 |
| 통화/재전송 | 서브루틴 호출/리턴 |
| 안돼 | 작동하지 않음 |
| CPUID | CPU 정보 |
x64에는 곱셈과 나눗셈 명령어가 있습니다. µP에는 곱셈과 나눗셈 하드웨어 회로가 있습니다. 6502 µP에는 곱셈 및 나눗셈 하드웨어 회로가 없습니다. 소프트웨어보다 하드웨어로 곱셈과 나눗셈을 수행하는 것이 더 빠릅니다(비트 이동 포함).
문자열 지침
많은 문자열 명령어가 있지만 여기서 설명할 유일한 명령어는 주소 C000에서 시작하는 문자열을 복사하는 MOVS(문자열 이동) 명령어입니다. 시간 . 주소 C100에서 시작하려면 시간 , 다음 지침을 사용하십시오.
MOVS [C100H], [C000H]
16진수에는 접미사 H가 붙습니다.
6.35 x64에서 루핑
6502 µP에는 루핑을 위한 분기 명령이 있습니다. 분기 명령어는 새 명령어가 있는 주소 위치로 점프합니다. 주소 위치는 '루프'라고 할 수 있습니다. x64에는 루핑을 위한 LOOP/LOOPE/LOOPNE 명령어가 있습니다. 이러한 예약된 어셈블리 언어 단어를 '루프' 레이블(따옴표 제외)과 혼동하지 마십시오. 동작은 다음과 같습니다.
LOOP는 ECX를 감소시키고 ECX가 0이 아닌지 확인합니다. 해당 조건(0)이 충족되면 지정된 레이블로 점프합니다. 그렇지 않으면 실패합니다(다음 설명의 나머지 지침을 계속 진행).
LOOPE는 ECX를 감소시키고 ECX가 0이 아닌지(예를 들어 1일 수 있음) ZF가 1로 설정되어 있는지 확인합니다. 이러한 조건이 충족되면 레이블로 점프합니다. 그렇지 않으면 넘어집니다.
LOOPNE는 ECX를 감소시키고 ECX가 0이 아니고 ZF IS NOT 설정(즉, 0이 됨)을 확인합니다. 이러한 조건이 충족되면 레이블로 점프합니다. 그렇지 않으면 넘어집니다.
x64를 사용하면 RCX 레지스터나 ECX 또는 CX와 같은 하위 부분이 카운터 정수를 보유합니다. LOOP 명령을 사용하면 카운터는 일반적으로 점프(루프)할 때마다 1씩 감소하여 카운트다운됩니다. 다음 루핑 코드 세그먼트에서 EAX 레지스터의 숫자는 10번의 반복을 통해 0에서 10으로 증가하는 반면 ECX의 숫자는 10번 감소(감소)합니다(주석 읽기).
MOV EAX, 0 ;
MOV ECX, 10 ; 기본적으로 각 반복마다 한 번씩 10번 카운트다운합니다.
상표:
INC EAX ; 루프 본문으로 EAX를 증가시킵니다.
루프 라벨 ; EAX를 감소시키고 EAX가 0이 아니면 'label:'에서 루프 본문을 다시 실행합니다.
루프 코딩은 'label:'에서 시작됩니다. 콜론의 사용에 유의하세요. 루프 코딩은 EAX 감소를 나타내는 'LOOP 레이블'로 끝납니다. 내용이 0이 아닌 경우 'label:' 이후의 명령어로 돌아가서 'LOOP label'까지 아래로 오는 모든 명령어(모든 본문 명령어)를 다시 실행합니다. '라벨'에는 여전히 다른 이름이 있을 수 있습니다.
6.36 x64의 입출력
이 장의 이 섹션에서는 데이터를 출력(내부) 포트로 전송하거나 입력(내부) 포트에서 데이터를 수신하는 방법을 다룹니다. 칩셋에는 8비트 포트가 있습니다. 두 개의 연속된 8비트 포트는 16비트 포트로 처리될 수 있으며, 연속된 네 개의 포트는 32비트 포트가 될 수 있습니다. 이러한 방식으로 프로세서는 외부 장치와 8, 16 또는 32비트를 전송할 수 있습니다.
정보는 두 가지 방법, 즉 메모리 매핑된 입력/출력을 사용하거나 별도의 입력/출력 주소 공간을 사용하여 프로세서와 내부 포트 간에 전송될 수 있습니다. 메모리 매핑된 I/O는 포트 주소가 실제로 전체 메모리 공간의 일부인 6502 프로세서에서 발생하는 것과 같습니다. 이 경우 특정 주소 위치로 데이터를 보낼 때 메모리 뱅크가 아닌 포트로 이동합니다. 포트에는 별도의 I/O 주소 공간이 있을 수 있습니다. 후자의 경우 모든 메모리 뱅크의 주소는 0부터 시작됩니다. 0000H부터 FFFF16까지 별도의 주소 범위가 있습니다. 이는 칩셋의 포트에서 사용됩니다. 마더보드는 메모리 매핑된 I/O와 별도의 I/O 주소 공간을 혼동하지 않도록 프로그래밍되었습니다.
메모리 매핑된 I/O
이를 통해 포트는 메모리 위치로 간주되며 메모리와 µP 간에 사용되는 일반 opcode는 µP와 포트 간의 데이터 전송에 사용됩니다. 따라서 주소 F000H의 포트에서 µP 레지스터 RAX:EAX:AX:AL로 바이트를 이동하려면 다음을 수행하십시오.
MOV AL, [F000H]
문자열은 메모리에서 포트로 또는 그 반대로 이동할 수 있습니다. 예:
MOVS [F000H], [C000H] ; 소스는 C000H이고 대상은 F000H의 포트입니다.
별도의 I/O 주소 공간
이를 위해서는 입력 및 출력에 대한 특수 명령을 사용해야 합니다.
단일 항목 이전
전송을 위한 프로세서 레지스터는 RAX입니다. 실제로 더블워드는 RAX:EAX, 워드는 RAX:EAX:AX, 바이트는 RAX:EAX:AX:AL입니다. 따라서 FFF0h의 포트에서 RAX:EAX:AX:AL로 바이트를 전송하려면 다음을 입력하십시오.
AL에서 [FFF0H]
역방향 전송의 경우 다음을 입력합니다.
출력 [FFF0H], AL
따라서 단일 항목의 경우 지침은 IN 및 OUT입니다. 포트 주소는 RDX:EDX:DX 레지스터에서도 제공될 수 있습니다.
문자열 전송
문자열은 메모리에서 칩셋 포트로 또는 그 반대로 전송될 수 있습니다. FFF0H 주소의 포트에서 메모리로 문자열을 전송하려면 C100H에서 시작하고 다음을 입력합니다.
INS [ESI], [DX]
이는 다음과 같은 효과를 갖습니다:
INS [EDI], [DX]
프로그래머는 FFF0H의 2바이트 포트 주소를 RDX:EDX:Dx 레지스터에 넣어야 하며, C100H의 2바이트 포트 주소를 RSI:ESI 또는 RDI:EDI 레지스터에 넣어야 합니다. 역방향 전송의 경우 다음을 수행합니다.
INS [DX], [ESI]
이는 다음과 같은 효과를 갖습니다:
INS [DX], [EDI]
6.37 x64의 스택
6502 프로세서와 마찬가지로 x64 프로세서도 RAM에 스택을 가지고 있습니다. x64의 스택은 2개일 수 있습니다. 16 = 65,536바이트 길이 또는 2일 수 있음 32 = 4,294,967,296바이트 길이. 아래쪽으로도 자랍니다. 레지스터의 내용이 스택에 푸시되면 RSP 스택 포인터의 숫자는 8만큼 감소합니다. x64의 메모리 주소는 64비트 너비라는 점을 기억하십시오. µP의 스택 포인터 값은 RAM에 있는 스택의 다음 위치를 가리킵니다. 레지스터의 내용(또는 한 피연산자의 값)이 스택에서 레지스터로 팝되면 RSP 스택 포인터의 숫자가 8만큼 증가합니다. 운영 체제는 스택의 크기와 RAM에서 스택이 시작되는 위치를 결정합니다. 그리고 아래쪽으로 자랍니다. 이 경우 스택은 아래쪽으로 늘어나고 위쪽으로 줄어드는 후입선출(LIFO) 구조라는 점을 기억하세요.
µP RBX 레지스터의 내용을 스택에 푸시하려면 다음을 수행하십시오.
푸시 RBX
스택의 마지막 항목을 다시 RBX로 팝하려면 다음을 수행합니다.
팝 RBX
6.38 x64의 절차
x64의 서브루틴을 '프로시저'라고 합니다. 스택은 6502 µP에 사용된 것보다 여기에서 더 많이 사용됩니다. x64 프로시저의 구문은 다음과 같습니다.
proc_name:
절차 본문
…
오른쪽
계속하기 전에 x64 서브루틴(일반적으로 어셈블리 언어 명령어)의 opcode와 레이블은 대소문자를 구분하지 않는다는 점에 유의하세요. 즉, proc_name은 PROC_NAME과 동일합니다. 6502와 마찬가지로 프로시저 이름(레이블)의 이름은 어셈블리 언어의 텍스트 편집기에서 새 줄의 시작 부분에서 시작됩니다. 그 뒤에는 6502와 같이 공백과 opcode가 아닌 콜론이 옵니다. 서브루틴 본문은 6502 µP와 같이 RTS가 아닌 RET로 끝나며 이어집니다. 6502와 마찬가지로 RET를 포함한 본문의 각 명령어는 해당 줄의 시작 부분에서 시작되지 않습니다. 여기의 라벨 길이는 8자 이상일 수 있습니다. 이 프로시저를 호출하려면 입력된 프로시저 위 또는 아래에서 다음을 수행합니다.
proc_name 호출
6502의 경우 라벨 이름은 단지 호출을 위한 유형일 뿐입니다. 그러나 여기서는 예약어 'CALL' 또는 'call'을 입력하고 공백 뒤에 프로시저(서브루틴) 이름을 입력합니다.
절차를 다룰 때 일반적으로 두 가지 절차가 있습니다. 한 프로시저가 다른 프로시저를 호출합니다. 호출하는(호출 명령이 있는) 프로시저를 '호출자'라고 하며, 호출되는 프로시저를 '호출자'라고 합니다. 따라야 할 관례(규칙)가 있습니다.
호출자의 규칙
호출자는 서브루틴을 호출할 때 다음 규칙을 준수해야 합니다.
1. 서브루틴을 호출하기 전에 호출자는 호출자 저장으로 지정된 특정 레지스터의 내용을 스택에 저장해야 합니다. 호출자가 저장한 레지스터는 R10, R11 및 매개변수가 저장되는 모든 레지스터(RDI, RSI, RDX, RCX, R8, R9)입니다. 이러한 레지스터의 내용이 서브루틴 호출 전체에 걸쳐 보존되어야 하는 경우 RAM에 저장하는 대신 스택에 푸시합니다. 이전 내용을 지우려면 호출 수신자가 레지스터를 사용해야 하기 때문에 이러한 작업을 수행해야 합니다.
2. 예를 들어 두 개의 숫자를 추가하는 절차인 경우 두 개의 숫자는 스택에 전달될 매개변수입니다. 서브루틴에 매개변수를 전달하려면 매개변수 중 6개를 RDI, RSI, RDX, RCX, R8, R9 순서대로 레지스터에 입력하십시오. 서브루틴에 6개 이상의 매개변수가 있는 경우 나머지 매개변수를 역순으로(즉, 마지막 매개변수부터) 스택에 푸시합니다. 스택이 작아지기 때문에 첫 번째 추가 매개변수(실제로는 7번째 매개변수)가 가장 낮은 주소에 저장됩니다(이러한 매개변수 반전은 역사적으로 함수(서브루틴)가 다양한 수의 매개변수와 함께 전달될 수 있도록 하는 데 사용되었습니다).
3. 서브루틴(절차)을 호출하려면 호출 명령을 사용하십시오. 이 명령어는 반환 주소를 스택의 매개변수(최하위 위치) 위에 배치하고 서브루틴 코드에 대한 분기를 배치합니다.
4. 서브루틴이 반환된 후(즉, 호출 명령 직후) 호출자는 스택에서 추가 매개변수(레지스터에 저장된 6개 이외의 매개변수)를 제거해야 합니다. 그러면 호출이 수행되기 전의 상태로 스택이 복원됩니다.
5. 호출자는 RAX 레지스터에서 서브루틴의 반환 값(주소)을 찾을 것으로 예상할 수 있습니다.
6. 호출자는 호출자가 저장한 레지스터(R10, R11 및 매개변수 전달 레지스터의 모든 항목)를 스택에서 꺼내어 내용을 복원합니다. 호출자는 서브루틴에 의해 수정된 다른 레지스터가 없다고 가정할 수 있습니다.
호출 규칙의 구조화 방식으로 인해 일반적으로 이러한 단계 중 일부(또는 대부분)가 스택을 변경하지 않는 경우가 있습니다. 예를 들어 매개변수가 6개 이하인 경우 해당 단계에서는 아무것도 스택에 푸시되지 않습니다. 마찬가지로 프로그래머(및 컴파일러)는 일반적으로 과도한 푸시 및 팝을 방지하기 위해 1단계와 6단계에서 호출자가 저장한 레지스터에서 관심 있는 결과를 유지합니다.
매개변수를 서브루틴에 전달하는 다른 두 가지 방법이 있지만 이 온라인 직업 과정에서는 이에 대해 다루지 않습니다. 그 중 하나는 범용 레지스터 대신 스택 자체를 사용합니다.
수신자의 규칙
호출된 서브루틴의 정의는 다음 규칙을 따라야 합니다.
1. 레지스터를 사용하거나 스택에 공간을 만들어 지역 변수(프로시저 내에서 개발된 변수)를 할당합니다. 스택이 아래쪽으로 증가한다는 것을 기억하세요. 따라서 스택 상단에 공간을 만들려면 스택 포인터를 감소시켜야 합니다. 스택 포인터가 감소하는 양은 필요한 지역 변수 수에 따라 다릅니다. 예를 들어 로컬 float 및 로컬 long(총 12바이트)이 필요한 경우 이러한 로컬 변수를 위한 공간을 만들기 위해 스택 포인터를 12씩 줄여야 합니다. C와 같은 고급 언어에서 이는 값을 할당(초기화)하지 않고 변수를 선언하는 것을 의미합니다.
2. 다음으로 함수에서 사용하는 지정된 호출 수신자가 저장한 레지스터(호출자가 저장하지 않은 범용 레지스터)의 값을 저장해야 합니다. 레지스터를 저장하려면 레지스터를 스택에 푸시합니다. 호출 수신자가 저장하는 레지스터는 RBX, RBP 및 R12~R15입니다(RSP도 호출 규칙에 따라 유지되지만 이 단계 중에 스택에 푸시할 필요는 없습니다).
이 세 가지 작업이 수행된 후 서브루틴의 실제 작업이 진행될 수 있습니다. 서브루틴이 반환될 준비가 되면 호출 규칙 규칙이 계속됩니다.
3. 서브루틴이 완료되면 서브루틴의 반환 값이 아직 RAX에 없으면 RAX에 배치되어야 합니다.
4. 서브루틴은 수정된 호출 수신자 저장 레지스터(RBX, RBP 및 R12~R15)의 이전 값을 복원해야 합니다. 레지스터 내용은 스택에서 팝하여 복원됩니다. 레지스터는 푸시된 순서와 반대 순서로 팝되어야 합니다.
5. 다음으로 지역 변수 할당을 해제합니다. 가장 쉬운 방법은 1단계에서 차감한 금액을 RSP에 추가하는 것입니다.
6. 마지막으로 ret 명령을 실행하여 호출자에게 돌아갑니다. 이 명령어는 스택에서 적절한 반환 주소를 찾아서 제거합니다.
'myFunc'라는 다른 서브루틴을 호출하기 위한 호출자 서브루틴 본문의 예는 다음과 같습니다(주석 읽기).
; 3개를 사용하는 'myFunc' 함수를 호출하고 싶습니다.
; 정수 매개변수. 첫 번째 매개변수는 RAX 에 있습니다.
; 두 번째 매개변수는 상수 456입니다.
; 매개변수가 메모리 위치 'variabl'에 있습니다.
푸시 rdi ; rdi는 param이므로 저장하세요.
; long retVal = myFunc ( x , 456 , z ) ;
mov rdi , rax ; RDI에 첫 번째 매개변수 넣기
이동 rsi, 456; RSI에 두 번째 매개변수 넣기
mov rdx , [변수] ; RDX에 세 번째 매개변수를 넣습니다.
myFunc를 호출합니다. 함수를 호출
팝 rdi ; 저장된 RDI 값 복원
; 이제 myFunc의 반환 값을 RAX에서 사용할 수 있습니다.
피호출자 함수(myFunc)의 예는 다음과 같습니다(주석 읽기).
myFunc :
; *** 표준 서브루틴 프롤로그 ***
하위 rsp, 8 ; '하위' opcode를 사용하는 64비트 지역 변수(결과)를 위한 공간
푸시 rbx ; 호출 수신자 저장 - 레지스터 저장
푸시 rbp ; 둘 다 myFunc에서 사용됩니다.
; ********* 서브루틴 바디 ******
mov rax, rdi ; 매개변수 1 - RAX
이동 rbp , rsi ; 매개변수 2를 RBP로
mov rbx , rdx ; 매개변수 3을 rb x로
mov [rsp+16], rbx; rbx를 로컬 변수에 넣습니다.
추가 [ rsp + 1 6 ] , rbp ; 지역 변수에 rbp 추가
mov rax, [ rsp +16 ] ; 지역 변수의 내용을 RAX로 이동
; (반환 값/최종 결과)
; *** 표준 서브루틴 에필로그 ***
팝 rbp ; 호출 수신자 저장 레지스터 복구
팝 rbx; 밀었을 때의 반대
추가 rsp, 8 ; 지역 변수 할당을 해제합니다. 8은 8바이트를 의미합니다.
다시 ; 스택에서 최상위 값을 팝하고 거기로 점프합니다.
6.39 x64에 대한 인터럽트 및 예외
프로세서는 프로그램 실행, 인터럽트 및 예외를 중단하기 위한 두 가지 메커니즘을 제공합니다.
- 인터럽트는 일반적으로 I/O 장치에 의해 트리거되는 비동기(언제든지 발생할 수 있음) 이벤트입니다.
- 예외는 명령을 실행하는 동안 프로세서가 하나 이상의 미리 정의된 조건을 감지할 때 생성되는 동기 이벤트(일부 발생에 따라 코드가 실행되고 사전 프로그래밍될 때 발생함)입니다. 오류, 트랩 및 중단이라는 세 가지 예외 클래스가 지정됩니다.
프로세서는 기본적으로 동일한 방식으로 인터럽트와 예외에 응답합니다. 인터럽트나 예외가 신호를 받으면 프로세서는 현재 프로그램이나 작업의 실행을 중단하고 인터럽트나 예외 조건을 처리하기 위해 특별히 작성된 핸들러 프로시저로 전환합니다. 프로세서는 IDT(Interrupt Descriptor Table)의 항목을 통해 처리기 프로시저에 액세스합니다. 핸들러가 인터럽트나 예외 처리를 완료하면 프로그램 제어가 인터럽트된 프로그램이나 작업으로 반환됩니다.
운영 체제, 실행 프로그램 및/또는 장치 드라이버는 일반적으로 응용 프로그램이나 작업과 별도로 인터럽트 및 예외를 처리합니다. 그러나 응용 프로그램은 운영 체제에 통합된 인터럽트 및 예외 처리기에 액세스하거나 어셈블리 언어 호출을 통해 이를 실행할 수 있습니다.
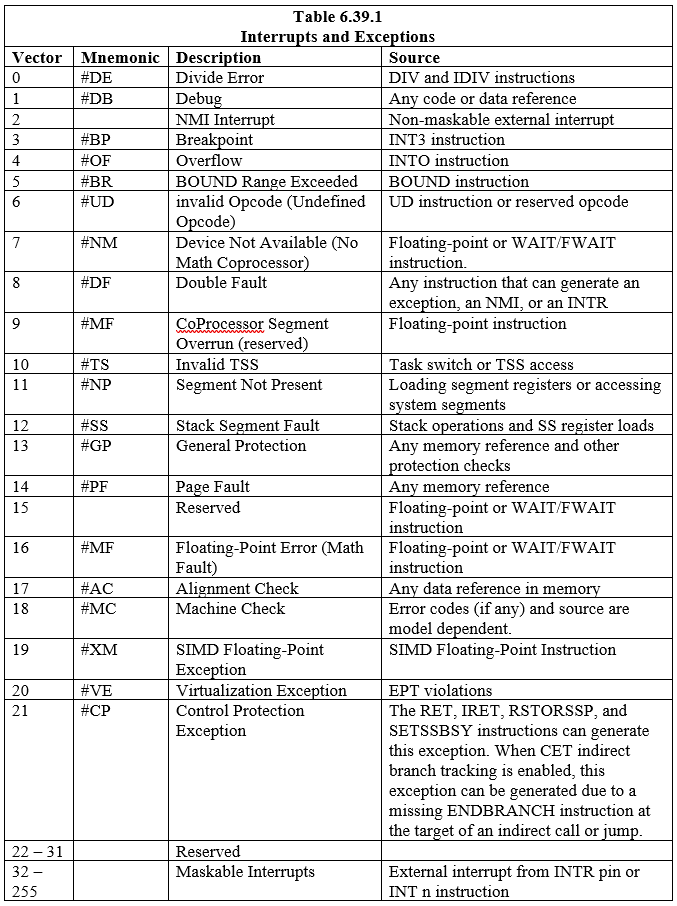
IDT의 항목과 관련된 18개의 사전 정의된 인터럽트 및 예외가 정의됩니다. 224개의 사용자 정의 인터럽트도 생성하여 테이블과 연결할 수 있습니다. IDT의 각 인터럽트와 예외는 '벡터'라는 숫자로 식별됩니다. 표 6.39.1에는 IDT의 항목과 해당 벡터가 포함된 인터럽트 및 예외가 나열되어 있습니다. 벡터 0~8, 10~14, 16~19는 미리 정의된 인터럽트 및 예외입니다. 벡터 32부터 255는 소프트웨어 인터럽트 또는 마스크 가능한 하드웨어 인터럽트를 위한 소프트웨어 정의 인터럽트(사용자)를 위한 것입니다.
프로세서가 인터럽트나 예외를 감지하면 다음 작업 중 하나를 수행합니다.
- 핸들러 프로시저에 대한 암시적 호출 실행
- 핸들러 작업에 대한 암시적 호출 실행
6.4 64비트 ARM 컴퓨터 아키텍처 기본
ARM 아키텍처는 다양한 애플리케이션에 사용하기에 적합한 RISC 프로세서 제품군을 정의합니다. ARM은 ALU(산술 논리 장치) 연산과 같은 처리가 수행되기 전에 메모리에서 레지스터로 데이터를 로드해야 하는 로드/저장 아키텍처입니다. 후속 명령어는 결과를 다시 메모리에 저장합니다. 이는 단일 명령(물론 프로세서 레지스터 사용)으로 메모리의 피연산자에서 직접 작동하는 x86 및 x64 아키텍처에서 한 단계 뒤로 물러난 것처럼 보일 수 있지만 로드/저장 접근 방식은 실제로 여러 순차적 작업을 허용합니다. 피연산자가 많은 프로세서 레지스터 중 하나에 로드되면 피연산자에 대해 고속으로 수행됩니다. ARM 프로세서에는 리틀 엔디안 또는 빅 엔디안 옵션이 있습니다. 기본 ARM 64 설정은 운영 체제에서 일반적으로 사용되는 구성인 리틀 엔디안입니다. 64비트 ARM 아키텍처는 현대적이며 32비트 ARM 아키텍처를 대체하도록 설정되었습니다.
메모 : 64비트 ARM µP에 대한 모든 명령어의 길이는 4바이트(32비트)입니다.
6.41 64비트 ARM 레지스터 세트
64비트 ARM µP에는 31개의 범용 64비트 레지스터가 있습니다. 다음 다이어그램은 범용 레지스터와 일부 중요한 레지스터를 보여줍니다.
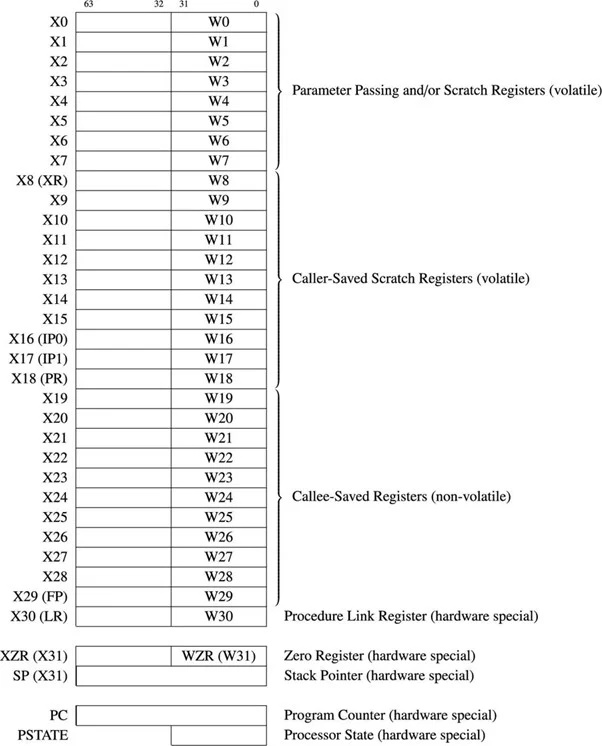
그림 4.11.1 64비트 범용 및 일부 중요 레지스터
범용 레지스터는 X0부터 X30까지를 지칭합니다. 각 레지스터의 첫 번째 32비트 부분은 W0부터 W30까지 참조됩니다. 32비트와 64비트의 차이가 강조되지 않는 경우에는 'R' 접두사가 사용됩니다. 예를 들어 R14는 W14 또는 X14를 나타냅니다.
6502 µP에는 16비트 프로그램 카운터가 있으며 2개의 주소를 지정할 수 있습니다. 16 메모리 바이트 위치. 64비트 ARM µP에는 64비트 프로그램 카운터가 있으며 최대 2개의 주소를 지정할 수 있습니다. 64 = 1.844674407 x 1019(실제로는 18,446,744,073,709,551,616) 메모리 바이트 위치. 프로그램 카운터는 다음에 실행될 명령어의 주소를 보유합니다. ARM64 또는 AArch64의 명령어 길이는 일반적으로 4바이트입니다. 프로세서는 각 명령어가 메모리에서 인출된 후 자동으로 이 레지스터를 4씩 증가시킵니다.
스택 포인터 레지스터 또는 SP는 31개의 범용 레지스터에 속하지 않습니다. 모든 아키텍처의 스택 포인터는 메모리의 마지막 스택 항목을 가리킵니다. ARM-64의 경우 스택이 아래쪽으로 늘어납니다.
6502 µP에는 8비트 프로세서 상태 레지스터가 있습니다. ARM64의 해당 항목을 PSTATE 레지스터라고 합니다. 이 레지스터는 연산 결과와 프로세서(μP) 제어에 사용되는 플래그를 저장합니다. 너비는 32비트입니다. 다음 표는 PSTATE 레지스터에서 일반적으로 사용되는 비트의 이름, 인덱스 및 의미를 제공합니다.
| 표 6.41.1 가장 많이 사용된 PSTATE 플래그(비트) |
||
|---|---|---|
| 상징 | 조금 | 목적 |
| 중 | 0-3 | 모드: 현재 실행 권한 수준(USR, SVC 등)입니다. |
| 티 | 4 | Thumb: T32(Thumb) 명령어 세트가 활성화된 경우 설정됩니다. 지우면 ARM 명령어 세트가 활성화됩니다. 사용자 코드는 이 비트를 설정하고 지울 수 있습니다. |
| 그리고 | 9 | 엔디안: 이 비트를 설정하면 빅엔디안 모드가 활성화됩니다. 지워지면 리틀 엔디안 모드가 활성화됩니다. 기본값은 리틀 엔디안 모드입니다. |
| 큐 | 27 | 누적 포화 플래그: 일련의 작업 중 어느 시점에서 오버플로 또는 포화가 발생하는 경우 설정됩니다. |
| 안에 | 28 | 오버플로 플래그: 작업으로 인해 부호 있는 오버플로가 발생한 경우 설정됩니다. |
| 씨 | 29 | 캐리 플래그(Carry flag): 덧셈이 캐리를 생성했는지, 뺄셈을 통해 차용을 생성했는지 여부를 나타냅니다. |
| 와 함께 | 30 | Zero 플래그: 연산 결과가 0일 경우 설정됩니다. |
| N | 31 | 음수 플래그: 연산 결과가 음수인 경우 설정됩니다. |
ARM-64 µP에는 다른 많은 레지스터가 있습니다.
심드
SIMD는 단일 명령, 다중 데이터를 나타냅니다. 이는 하나의 어셈블리 언어 명령어가 하나의 마이크로프로세서에서 동시에 여러 데이터에 대해 작동할 수 있음을 의미합니다. SIMD 및 부동 소수점 연산에 사용할 수 있는 128비트 폭의 레지스터가 32개 있습니다.
6.42 메모리 매핑
RAM과 DRAM은 모두 랜덤 액세스 메모리입니다. DRAM은 RAM보다 작동 속도가 느립니다. DRAM은 RAM보다 저렴합니다. 메모리에 32GB 이상의 연속 DRAM이 있는 경우 더 많은 메모리 관리 문제가 발생합니다. 32GB = 32 x 1024 x 1024 x 1024바이트. 32GB보다 훨씬 큰 전체 메모리 공간의 경우 더 나은 메모리 관리를 위해 32GB 이상의 DRAM을 RAM과 함께 배치해야 합니다. ARM-64 메모리 맵을 이해하려면 먼저 32비트 ARM 중앙처리장치(CPU)에 대한 4GB 메모리 맵을 이해해야 합니다. CPU는 µP를 의미합니다. 32비트 컴퓨터의 경우 주소 지정이 가능한 최대 메모리 공간은 2입니다. 32 = 4×2 10 x 2 10 x 2 10 = 4 x 1024 x 1024 x 1024 = 4,294,967,296 = 4GB.
32비트 ARM 메모리 맵
32비트 ARM의 메모리 맵은 다음과 같습니다.

32비트 컴퓨터의 경우 전체 메모리의 최대 크기는 4GB입니다. 0GB 주소부터 1GB 주소까지는 ROM 운영 체제, RAM 및 I/O 위치입니다. ROM OS, RAM 및 I/O 주소에 대한 전체 아이디어는 6502 CPU가 가능한 Commodore-64의 상황과 유사합니다. Commodore-64의 OS ROM은 메모리 공간의 맨 위에 있습니다. 여기의 ROM OS는 Commodore-64보다 훨씬 크며 전체 메모리 주소 공간의 시작 부분에 있습니다. 다른 최신 컴퓨터와 비교할 때 여기의 ROM OS는 하드 드라이브에 있는 OS의 양과 비슷하다는 점에서 완전합니다. ROM 집적 회로에 OS를 포함하는 데는 두 가지 주요 이유가 있습니다. 1) ARM CPU는 주로 스마트폰과 같은 소형 장치에 사용됩니다. 많은 하드 드라이브는 2) 보안을 위해 스마트폰 및 기타 소형 장치보다 큽니다. OS가 읽기 전용 메모리에 있으면 해커가 OS를 손상(일부 덮어쓰기)할 수 없습니다. RAM 부분과 입출력 부분도 Commodore-64에 비해 매우 큽니다.
32비트 ROM OS로 전원을 켜면 OS는 0x00000000 주소에서 시작(부팅)해야 하며 HiVEC가 활성화된 경우 0xFFFF0000 주소에서 시작해야 합니다. 따라서 리셋 단계 이후에 전원을 켜면 CPU 하드웨어는 프로그램 카운터에 0x00000000 또는 0xFFFF0000을 로드합니다. '0x' 접두사는 16진수를 의미합니다. ARMv8 64비트 CPU의 부팅 주소는 정의된 구현입니다. 그러나 저자는 이전 버전과의 호환성을 위해 컴퓨터 엔지니어에게 0x00000000 또는 0xFFFF0000에서 시작하도록 조언합니다.
1GB부터 2GB까지는 매핑된 입력/출력입니다. 매핑된 I/O와 0GB와 1GB 사이에 있는 I/O에만 차이가 있습니다. I/O를 사용하면 Commodore-64와 마찬가지로 각 포트의 주소가 고정됩니다. 매핑된 I/O를 사용하면 각 포트의 주소가 컴퓨터의 각 작업(동적)에서 반드시 동일할 필요는 없습니다.
2GB부터 4GB까지가 DRAM입니다. 이는 예상되는(또는 일반적인) RAM입니다. DRAM은 동적 RAM(Dynamic RAM)을 의미하며 컴퓨터 작동 중에 주소가 변경된다는 의미가 아니라 물리적 RAM의 각 셀 값이 각 클록 펄스에서 새로 고쳐져야 한다는 의미입니다.
메모 :
- 0x0000,0000부터 0x0000까지 FFFF는 OS ROM입니다.
- 0x0001,0000부터 0x3FFF,FFFF까지 ROM, RAM, I/O가 더 있을 수 있습니다.
- 0x4000,0000부터 0x7FFF,FFFF까지 추가 I/O 및/또는 매핑된 I/O가 허용됩니다.
- 0x8000,0000에서 0xFFFF,FFFF가 예상되는 DRAM입니다.
이는 실제로 예상되는 DRAM이 2GB 메모리 경계에서 시작할 필요가 없음을 의미합니다. 마더보드에 슬롯에 장착된 물리적 RAM 뱅크가 충분하지 않은 경우 프로그래머가 이상적인 경계를 존중해야 하는 이유는 무엇입니까? 이는 고객이 모든 RAM 뱅크에 대한 자금이 충분하지 않기 때문입니다.
36비트 ARM 메모리 맵
64비트 ARM 컴퓨터의 경우 32비트가 모두 전체 메모리 주소를 지정하는 데 사용됩니다. 64비트 ARM 컴퓨터의 경우 처음 36비트는 전체 메모리 주소를 지정하는 데 사용될 수 있으며, 이 경우에는 2입니다. 36 = 68,719,476,736 = 64GB. 이것은 이미 많은 메모리입니다. 오늘날 일반 컴퓨터에는 이 정도의 메모리가 필요하지 않습니다. 이는 아직 64비트로 액세스할 수 있는 최대 메모리 범위에 미치지 못합니다. ARM CPU의 36비트 메모리 맵은 다음과 같습니다.
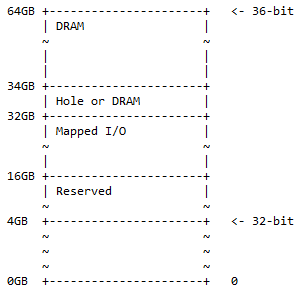
0GB 주소부터 4GB 주소까지는 32비트 메모리 맵입니다. '예약됨'은 사용되지 않고 향후 사용을 위해 보관되는 것을 의미합니다. 해당 공간을 위해 마더보드에 장착되는 물리적 메모리 뱅크일 필요는 없습니다. 여기서 DRAM과 매핑된 I/O는 32비트 메모리 맵과 동일한 의미를 갖습니다.
실제로 다음과 같은 상황이 나타날 수 있습니다.
- 0x1 0000 0000 – 0x3 FFFF FFFF; 예약된. 12GB의 주소 공간은 향후 사용을 위해 예약되어 있습니다.
- 0x4 0000 0000 – 0x7 FFFF FFFF; 매핑된 I/O. 동적으로 매핑된 I/O에 16GB의 주소 공간을 사용할 수 있습니다.
- 0x8 0000 0000 – 0x8 7FFF FFFF FFFF; 구멍 또는 DRAM. 2GB의 주소 공간에는 다음 중 하나가 포함될 수 있습니다.
- DRAM 장치 파티셔닝을 활성화하는 구멍입니다(다음 설명 참조).
- 음주.
- 0x8 8000 0000 – 0xF FFFF FFFF; 음주. DRAM용 주소 공간은 30GB입니다.
이 메모리 맵은 32비트 주소 맵의 상위 집합으로, 추가 공간은 옵션 구멍이 있는 50% DRAM(1/2)으로 분할되고 25% 매핑된 I/O 공간 및 예약된 공간(1/4) ). 나머지 25%(1/4)는 32비트 메모리 맵 ½ + ¼ + ¼ = 1에 대한 것입니다.
메모 : 32비트에서 360비트까지는 36비트의 최상위측에 4비트가 추가됩니다.
40비트 메모리 맵
40비트 주소 맵은 36비트 주소 맵의 상위 집합이며 옵션 홀의 50% DRAM, 25% 매핑된 I/O 공간 및 예약 공간, 나머지 25%의 동일한 패턴을 따릅니다. 이전 메모리 맵(36비트)을 위한 공간입니다. 메모리 맵의 다이어그램은 다음과 같습니다.
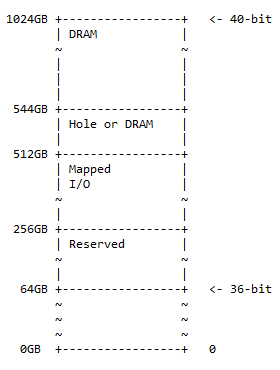
구멍의 크기는 544 – 512 = 32GB입니다. 실제로 다음과 같은 상황이 나타날 수 있습니다.
- 0x10 0000 0000 – 0x3F FFFF FFFF; 예약된. 192GB의 주소 공간은 향후 사용을 위해 예약되어 있습니다.
- 0x40 0000 0000 – 0x7F FFFF FFFF; 매핑되었습니다. I/O 동적으로 매핑된 I/O에 256GB의 주소 공간을 사용할 수 있습니다.
- 0x80 0000 0000 – 0x87 FFFF FFFF; 홀 또는 DRAM. 32GB의 주소 공간에는 다음 중 하나가 포함될 수 있습니다.
- DRAM 장치 파티셔닝을 활성화하는 구멍(다음 설명 참조)
- 음주
- 0x88 0000 0000 – 0xFF FFFF FFFF; 음주. DRAM용 주소 공간은 480GB입니다.
메모 : 36비트에서 40비트까지는 36비트의 최상위측에 4비트가 추가됩니다.
D램 홀
32비트 이상의 메모리 맵에서는 DRAM 홀이거나 위에서부터 DRAM의 연속입니다. 홀인 경우 다음과 같이 이해해야 합니다. DRAM 홀은 대형 DRAM 장치를 여러 주소 범위로 분할하는 방법을 제공합니다. 선택적 DRAM 홀은 더 높은 DRAM 주소 경계의 시작 부분에 제안됩니다. 이는 물리적으로 주소가 지정된 하위 영역에 걸쳐 대용량 DRAM 장치를 분할할 때 단순화된 디코딩 방식을 가능하게 합니다.
예를 들어, 64GB DRAM 부분은 다음과 같이 상위 주소 비트에서 간단한 빼기로 수행되는 주소 오프셋을 사용하여 세 개의 영역으로 세분화됩니다.
| 표 6.42.1 구멍이 있는 64GB DRAM 분할의 예 |
|||
|---|---|---|---|
| SoC의 물리적 주소 | 오프셋 | 내부 DRAM 주소 | |
| 2GB(32비트 맵) | 0x00 8000 0000 – 0x00 FFFF FFFF | -0x00 8000 0000 | 0x00 0000 0000 – 0x00 7FFF FFFF |
| 30GB(36비트 맵) | 0x08 8000 0000 – 0x0F FFFF FFFF | -0x08 0000 0000 | 0x00 8000 0000 – 0x07 FFFF FFFF |
| 32GB(40비트 맵) | 0x88 0000 0000 – 0x8F FFFF FFFF | -0x80 0000 0000 | 0x08 0000 0000 – 0x0F FFFF FFFF |
ARM CPU에 대해 제안된 44비트 및 48비트 주소 지정 메모리 맵
개인용 컴퓨터의 메모리가 1024GB(= 1TB)라고 가정합니다. 너무 많은 메모리입니다. 따라서 각각 16TB 및 256TB용 ARM CPU에 대한 44비트 및 48비트 주소 지정 메모리 맵은 미래의 컴퓨터 요구 사항에 대한 제안일 뿐입니다. 실제로 ARM CPU에 대한 이러한 제안은 이전 메모리 맵과 동일한 비율로 메모리 분할을 따릅니다. 즉, 옵션 구멍이 있는 DRAM 50%, 매핑된 I/O 공간 및 예약된 공간 25%, 이전 메모리 맵을 위한 나머지 25% 공간입니다.
52비트, 56비트, 60비트 및 64비트 주소 지정 메모리 맵은 먼 미래를 위해 ARM 64비트에 대해 여전히 제안될 예정입니다. 당시 과학자들이 여전히 전체 메모리 공간을 50:25:25로 분할하는 것이 유용하다고 생각한다면 그 비율을 유지할 것입니다.
메모 : SoC는 System-on-Chip의 약자로, 그렇지 않으면 존재하지 않았을 µP 칩의 회로를 나타냅니다.
SRAM 또는 Static Random Access Memory는 기존 DRAM보다 빠르지만 더 많은 실리콘 영역이 필요합니다. SRAM에는 새로 고침이 필요하지 않습니다. 독자는 RAM을 SRAM으로 상상할 수 있습니다.
6.43 ARM 64용 어셈블리 언어 주소 지정 모드
ARM은 산술 논리 연산과 같은 처리가 수행되기 전에 메모리에서 프로세서 레지스터로 데이터를 로드해야 하는 로드/저장 아키텍처입니다. 후속 명령어는 결과를 다시 메모리에 저장합니다. 이는 단일 명령으로 메모리의 피연산자에서 직접 작동하는 x86 및 후속 x64 아키텍처에서 한 단계 뒤로 물러난 것처럼 보일 수 있지만 실제로 로드/저장 접근 방식을 사용하면 여러 순차적 작업을 고속으로 수행할 수 있습니다. 많은 프로세서 레지스터 중 하나에 로드되면 피연산자입니다.
ARM 어셈블리 언어의 형식은 x64(x86) 시리즈와 유사점과 차이점이 있습니다.
- 오프셋 : 부호 있는 상수를 기본 레지스터에 추가할 수 있습니다. 오프셋은 명령어의 일부로 입력됩니다. 예를 들어, ldr x0, [rx, #10]은 r1+10 주소에 있는 단어와 함께 r0을 로드합니다.
- 등록하다 : 레지스터에 저장된 부호 없는 증분은 기본 레지스터의 값에 더하거나 뺄 수 있습니다. 예를 들어, ldr r0, [x1, x2]는 x1+x2 주소에 있는 단어와 함께 r0을 로드합니다. 두 레지스터 중 하나를 기본 레지스터로 간주할 수 있습니다.
- 스케일링된 레지스터 : 레지스터의 증분은 기본 레지스터 값에 더해지거나 빼지기 전에 지정된 비트 위치 수만큼 왼쪽이나 오른쪽으로 이동합니다. 예를 들어, ldr x0, [x1, x2, lsl #3]은 r1+(r2×8) 주소에 있는 단어와 함께 r0을 로드합니다. 시프트는 비워진 비트 위치에 0 비트를 삽입하는 논리적 왼쪽 또는 오른쪽 시프트(lsl 또는 lsr)이거나 빈 위치에 부호 비트를 복제하는 산술 오른쪽 시프트(asr)일 수 있습니다.
두 개의 피연산자가 관련된 경우 대상은 소스(왼쪽) 앞에 옵니다(몇 가지 예외가 있음). ARM 어셈블리 언어의 opcode는 대소문자를 구분하지 않습니다.
즉시 ARM64 주소 지정 모드
예:
mov r0, #0xFF000000 ; 32비트 값 FF000000h를 r0에 로드합니다.
10진수 값은 0x가 없지만 앞에 #이 붙습니다.
직접 등록
예:
이동 x0, x1 ; x1을 x0으로 복사
간접 등록
예:
str x0, [x3] ; x0을 x3의 주소에 저장
오프셋으로 간접 등록
예:
ldr x0, [x1, #32] ; 주소 [r1+32]의 값으로 r0을 로드합니다. r1은 기본 레지스터입니다.
str x0, [x1, #4] ; r0을 주소 [r1+4]에 저장합니다. r1은 기본 레지스터입니다. 숫자는 10진법입니다
오프셋으로 간접 등록(사전 증가)
예:
ldr x0, [x1, #32]! ; [r1+32]로 r0을 로드하고 r1을 (r1+32)로 업데이트합니다.
str x0, [x1, #4]! ; r0을 [r1+4]에 저장하고 r1을 (r1+4)로 업데이트합니다.
'!'의 사용에 유의하십시오. 상징.
오프셋으로 간접 등록(사후 증분)
예:
ldr x0, [x1], #32 ; [x1]을 x0으로 로드한 다음 x1을 (x1+32)로 업데이트합니다.
str x0, [x1], #4 ; x0을 [x1]에 저장한 다음 x1을 (x1+4)로 업데이트합니다.
이중 레지스터 간접
피연산자의 주소는 기본 레지스터와 증분 레지스터의 합입니다. 레지스터 이름은 대괄호로 묶입니다.
예:
ldr x0, [x1, x2] ; [x1+x2]로 x0 로드
str x0, [rx, x2] ; x0을 [x1+x2]에 저장
상대 주소 지정 모드
상대 주소 지정 모드에서 유효한 명령어는 프로그램 카운터의 다음 명령어에 인덱스를 더한 것입니다. 지수는 양수일 수도 있고 음수일 수도 있습니다.
예:
ldr x0, [PC, #24]
이는 PC 콘텐츠가 가리키는 단어에 24를 더한 로드 레지스터 X0을 의미합니다.
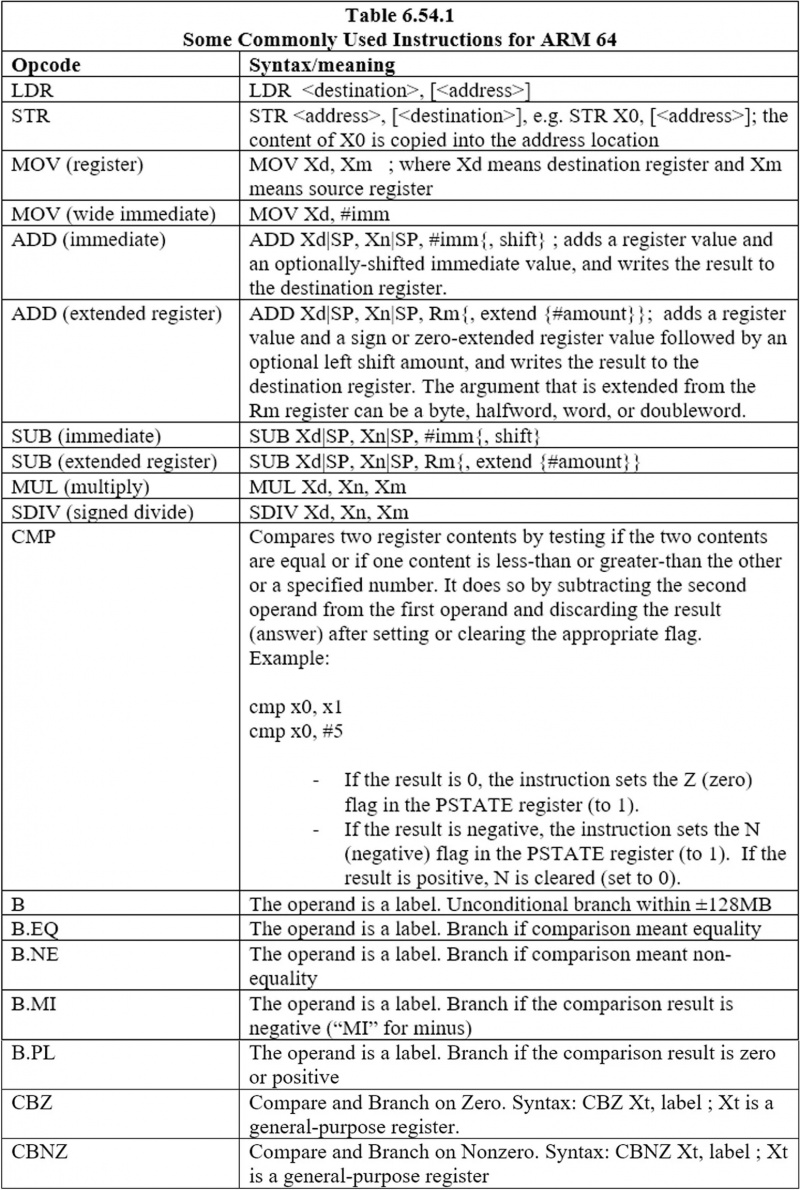
6.44 ARM 64에서 일반적으로 사용되는 명령어
일반적으로 사용되는 지침은 다음과 같습니다.
6.45 루핑
삽화
다음 코드는 X8의 값이 0이 될 때까지 X10 레지스터의 값을 X9의 값에 계속 추가합니다. 모든 값이 정수라고 가정합니다. X8의 값은 각 반복에서 1씩 뺍니다.
고리:
CBZ X8, 건너뛰기
X9, X9, X10을 추가합니다. 첫 번째 X9는 대상이고 두 번째 X9는 소스입니다.
하위 X8, X8, #1 ; 첫 번째 X8은 대상이고 두 번째 X8은 소스입니다.
B 루프
건너뛰다:
6502 µP 및 X64 µP와 마찬가지로 ARM 64 µP의 레이블은 줄의 시작 부분에서 시작됩니다. 나머지 지침은 줄 시작 부분 뒤의 일부 공백에서 시작됩니다. x64 및 ARM 64에서는 레이블 뒤에 콜론과 새 줄이 옵니다. 6502에서는 레이블 뒤에 공백 뒤에 명령이 옵니다. 이전 코드에서 'CBZ X8, Skip'인 첫 번째 명령어는 X8의 값이 0인 경우 'skip:' 라벨에서 계속하여 중간 명령어를 건너뛰고 아래의 나머지 명령어를 계속한다는 의미입니다. '건너뛰다:'. 'B 루프'는 '루프' 레이블로 무조건 점프하는 것입니다. 'loop' 대신 다른 레이블 이름을 사용할 수 있습니다.
따라서 6502 µP와 마찬가지로 분기 명령어를 사용하여 ARM 64와 루프를 만듭니다.
6.46 ARM 64 입력/출력
모든 ARM 주변 장치(내부 포트)는 메모리 매핑됩니다. 이는 프로그래밍 인터페이스가 메모리 주소가 지정된 레지스터(내부 포트) 세트라는 것을 의미합니다. 이러한 레지스터의 주소는 특정 메모리 기본 주소로부터의 오프셋입니다. 이는 6502가 입출력을 수행하는 방식과 유사합니다. ARM에는 별도의 I/O 주소 공간에 대한 옵션이 없습니다.
6.47 ARM 64의 스택
ARM 64에는 6502 및 x64와 유사한 방식으로 메모리 스택(RAM)이 있습니다. 그러나 ARM64에는 푸시 또는 팝 opcode가 없습니다. ARM 64의 스택도 아래쪽으로 증가합니다. 스택 포인터의 주소는 스택에 있는 마지막 값의 마지막 바이트 바로 뒤를 가리킵니다.
ARM64에 일반 팝 또는 푸시 연산코드가 없는 이유는 ARM 64가 연속적인 16바이트 그룹으로 스택을 관리하기 때문입니다. 그러나 값은 1바이트, 2바이트, 4바이트, 8바이트의 바이트 그룹으로 존재합니다. 따라서 하나의 값을 스택에 배치하고 16바이트를 구성하는 나머지 위치(바이트 위치)는 더미 바이트로 채워집니다. 이는 메모리를 낭비한다는 단점이 있습니다. 더 나은 해결책은 16바이트 위치를 더 작은 값으로 채우고 16바이트 위치의 값이 어디에서 왔는지(레지스터) 추적하는 코드를 프로그래머가 작성하도록 하는 것입니다. 이 추가 코드는 값을 되돌릴 때도 필요합니다. 이에 대한 대안은 두 개의 8바이트 범용 레지스터를 서로 다른 값으로 채운 다음 두 개의 8바이트 레지스터의 내용을 스택으로 보내는 것입니다. 스택에 들어가고 스택을 떠나는 특정 작은 값을 추적하려면 여기에 추가 코드가 여전히 필요합니다.
다음 코드는 4개의 4바이트 데이터를 스택에 저장합니다.
str w0, [sp, #-4]!
str w1, [sp, #-8]!
str w2, [sp, #-12]!
str w3, [sp, #-16]!
레지스터의 처음 4바이트(w)(x0, x1, x2 및 x3)는 스택의 연속 16바이트 위치로 전송됩니다. 'push'가 아닌 'str'을 사용한다는 점에 유의하세요. 각 명령 끝에 느낌표 기호가 표시됩니다. 메모리 스택은 아래쪽으로 커지기 때문에 첫 번째 4바이트 값은 이전 스택 포인터 위치보다 -4바이트 아래에 있는 위치에서 시작됩니다. 나머지 4바이트 값은 아래로 내려갑니다. 다음 코드 세그먼트는 4바이트를 팝하는 것과 동일한 올바른(그리고 순서대로) 작업을 수행합니다.
ldr w3, [sp], #0
ldr w2, [sp], #4
ldr w1, [sp], #8
ldr w0, [sp], #12
pop 대신 ldr opcode를 사용한다는 점에 유의하세요. 또한 여기서는 느낌표 기호가 사용되지 않습니다.
X0(8바이트) 및 X1(8바이트)의 모든 바이트는 다음과 같이 스택의 16바이트 위치로 전송될 수 있습니다.
stp x0, x1, [sp, #-16]! ; 8 + 8 = 16
이 경우 x2(w2) 및 x3(w3) 레지스터는 필요하지 않습니다. 원하는 모든 바이트는 X0 및 X2 레지스터에 있습니다. 레지스터 내용 쌍을 RAM에 저장하기 위한 stp opcode를 기록해 두십시오. 느낌표 기호도 참고하세요. 팝에 해당하는 내용은 다음과 같습니다.
ldp x0, x1, [sp], #0
이 명령에는 느낌표가 없습니다. 메모리에서 2개의 µP 레지스터로 2개의 연속 데이터 위치를 로드하기 위해 LDR 대신 opcode LDP를 사용합니다. 또한 메모리에서 µP 레지스터로 복사하는 것은 로딩 중이라는 점을 기억하십시오. 디스크에서 RAM으로 파일을 로딩하는 것과 혼동하지 마십시오. µP 레지스터에서 RAM으로 복사하는 것은 저장 중입니다.
6.48 서브루틴
서브루틴은 선택적으로 일부 인수를 기반으로 작업을 수행하고 선택적으로 결과를 반환하는 코드 블록입니다. 관례적으로 R0~R3 레지스터(레지스터 4개)는 인수(매개변수)를 서브루틴에 전달하는 데 사용되고 R0은 결과를 호출자에게 다시 전달하는 데 사용됩니다. 4개 이상의 입력이 필요한 서브루틴은 추가 입력을 위해 스택을 사용합니다. 서브루틴을 호출하려면 링크나 조건 분기 명령을 사용하십시오. 링크 명령어의 구문은 다음과 같습니다.
BL라벨
여기서 BL은 opcode이고 label은 서브루틴의 시작(주소)을 나타냅니다. 이 분기는 128MB 내에서 무조건 정방향 또는 역방향입니다. 조건부 분기 명령어의 구문은 다음과 같습니다.
B.cond 라벨
여기서 cond는 조건입니다(예: eq(같음) 또는 ne(같지 않음)). 다음 프로그램에는 두 인수의 값을 더하고 R0에 결과를 반환하는 doadd 서브루틴이 있습니다.
AREA 서브라우트, 코드, 읽기 전용 ; 이 코드 블록의 이름을 지정하세요.
입장 ; 실행할 첫 번째 명령어 표시
MOV r0, #10 시작 ; 매개변수 설정
MOV r1, #3
BL doadd ; 서브루틴 호출
MOV r0, #0x18 중지 ; angel_SWIreason_ReportException
LDR r1, =0x20026 ; ADP_Stopped_ApplicationExit
SVC #0x123456 ; ARM 세미호스팅(이전 SWI)
doadd ADD r0, r0, r1 ; 서브루틴 코드
BX lr ; 서브루틴에서 복귀
;
끝 ; 파일 끝 표시
추가할 숫자는 10진수 10과 3입니다. 이 코드 블록(프로그램)의 처음 두 줄은 나중에 설명합니다. 다음 세 줄은 10을 R0 레지스터로 보내고 3을 R1 레지스터로 보내고 doadd 서브루틴도 호출합니다. 'doadd'는 서브루틴 시작 주소를 보유하는 레이블입니다.
서브루틴은 단 두 줄로 구성됩니다. 첫 번째 줄은 R의 내용 3을 R0의 내용 10에 추가하여 R0에서 13의 결과를 허용합니다. BX opcode와 LR 피연산자가 포함된 두 번째 줄은 서브루틴에서 호출자 코드로 반환됩니다.
오른쪽
ARM 64의 RET 연산 코드는 여전히 서브루틴을 처리하지만 6502의 RTS, x64의 RET 또는 ARM 64의 'BX LR' 조합과 다르게 작동합니다. ARM 64에서 RET 구문은 다음과 같습니다.
직선 {Xn}
이 명령어는 프로그램이 호출자 서브루틴이 아닌 서브루틴을 계속하거나 다른 명령어 및 그에 따른 코드 세그먼트를 계속할 수 있는 기회를 제공합니다. Xn은 프로그램이 계속되어야 하는 주소를 보유하는 범용 레지스터입니다. 이 명령어는 무조건 분기됩니다. Xn이 제공되지 않으면 기본적으로 X30의 내용이 사용됩니다.
절차 호출 표준
프로그래머가 자신의 코드가 다른 사람이 작성한 코드 또는 컴파일러에서 생성된 코드와 상호 작용하기를 원하는 경우 프로그래머는 레지스터 사용 규칙에 대해 해당 사람 또는 컴파일러 작성자와 동의해야 합니다. ARM 아키텍처의 경우 이러한 규칙을 프로시저 호출 표준 또는 PCS라고 합니다. 이는 두 당사자 또는 세 당사자 간의 계약입니다. PCS는 다음을 지정합니다.
- 함수에 인수를 전달하는 데 사용되는 µP 레지스터(서브루틴)
- 호출자로 알려진 호출을 수행하는 함수에 결과를 반환하는 데 사용되는 µP 레지스터
- 피호출자로 알려진 호출되는 함수를 등록하는 µP는 손상될 수 있습니다.
- 호출 수신자가 손상될 수 없는 µP 레지스터
6.49 인터럽트
ARM 프로세서에 사용할 수 있는 인터럽트 컨트롤러 회로에는 두 가지 유형이 있습니다.
- 표준 인터럽트 컨트롤러: 인터럽트 핸들러는 인터럽트 컨트롤러의 장치 비트맵 레지스터를 읽어 서비스가 필요한 장치를 결정합니다.
- VIC(벡터 인터럽트 컨트롤러): 인터럽트의 우선순위를 지정하고 어떤 장치가 인터럽트를 발생시켰는지 확인하는 과정을 단순화합니다. 각 인터럽트에 우선순위와 핸들러 주소를 연결한 후 VIC는 새 인터럽트의 우선순위가 현재 실행 중인 인터럽트 핸들러보다 높은 경우에만 프로세서에 인터럽트 신호를 보냅니다.
메모 : 예외는 오류를 나타냅니다. 32비트 ARM 컴퓨터용 벡터 인터럽트 컨트롤러에 대한 세부 사항은 다음과 같습니다(64비트도 유사).
| 표 6.49.1 32비트 컴퓨터용 ARM 벡터 예외/인터럽트 |
|||
|---|---|---|---|
| 예외/인터럽트 | 짧은 손 | 주소 | 높은 주소 |
| 초기화 | 초기화 | 0x00000000 | 0xffff0000 |
| 정의되지 않은 명령어 | UNDEF | 0x00000004 | 0xffff0004 |
| 소프트웨어 인터럽트 | SWI | 0x00000008 | 0xffff0008 |
| 프리페치 중단 | 팻 | 0x0000000C | 0xffff000C |
| 낙태 날짜 | DABT | 0x00000010 | 0xffff0010 |
| 예약된 | – | 0x00000014 | 0xffff0014 |
| 중단 요청 | IRQ | 0x00000018 | 0xffff0018 |
| 빠른 인터럽트 요청 | FIQ | 0x0000001C | 0xffff001C |
이는 6502 아키텍처의 배치와 유사합니다. NMI , BR , 그리고 IRQ 페이지 0에 포인터를 가질 수 있으며 해당 루틴은 메모리(ROM OS)에 있습니다. 이전 표의 행에 대한 간략한 설명은 다음과 같습니다.
초기화
이는 프로세서의 전원이 켜질 때 발생합니다. 시스템을 초기화하고 다양한 프로세서 모드에 대한 스택을 설정합니다. 이는 최우선순위 예외입니다. 재설정 핸들러에 들어가면 CPSR은 SVC 모드에 있고 IRQ 및 FIQ 비트가 모두 1로 설정되어 모든 인터럽트를 마스킹합니다.
낙태 날짜
두 번째로 높은 우선순위입니다. 이는 유효하지 않은 주소를 읽거나 쓰거나 잘못된 액세스 권한에 액세스하려고 할 때 발생합니다. 데이터 중단 핸들러에 들어가면 IRQ가 비활성화되고(I비트 세트 1) FIQ가 활성화됩니다. IRQ는 마스크되어 있지만 FIQ는 마스크되지 않은 상태로 유지됩니다.
FIQ
우선순위가 가장 높은 인터럽트인 IRQ 및 FIQ는 FIQ가 처리될 때까지 비활성화됩니다.
IRQ
우선순위가 높은 인터럽트인 IRQ 핸들러는 진행 중인 FIQ 및 데이터 중단이 없는 경우에만 입력됩니다.
프리패치 중단
이는 데이터 중단과 유사하지만 주소 가져오기 실패 시 발생합니다. 핸들러에 진입하면 IRQ는 비활성화되지만 FIQ는 활성화된 상태로 유지되며 프리페치 중단 중에 발생할 수 있습니다.
SWI
SWI(소프트웨어 인터럽트) 예외는 SWI 명령어가 실행되고 우선순위가 더 높은 다른 예외가 플래그 지정되지 않은 경우 발생합니다.
정의되지 않은 명령어
정의되지 않은 명령어 예외는 ARM 또는 Thumb 명령어 세트에 없는 명령어가 파이프라인의 실행 단계에 도달하고 다른 예외에 플래그가 지정되지 않은 경우 발생합니다. 이는 한 번에 하나씩 발생할 수 있다는 점에서 SWI와 동일한 우선순위입니다. 이는 실행 중인 명령어가 SWI 명령어인 동시에 정의되지 않은 명령어일 수 없음을 의미합니다.
ARM 예외 처리
예외가 발생하면 다음 이벤트가 발생합니다.
- 예외 모드의 SPSR에 CPSR을 저장합니다.
- PC는 예외 모드의 LR에 저장됩니다.
- 링크 레지스터는 현재 명령어에 따라 특정 주소로 설정됩니다. 예: ISR의 경우 LR = 마지막으로 실행된 명령어 + 8.
- 예외에 대해 CPSR을 업데이트합니다.
- PC를 예외 처리기의 주소로 설정합니다.
6.5 지침 및 데이터
데이터는 변수(값이 표시된 레이블), 배열 및 배열과 유사한 기타 구조를 나타냅니다. 문자열은 문자 배열과 같습니다. 정수 배열은 이전 장 중 하나에서 볼 수 있습니다. 명령어는 opcode와 해당 피연산자를 참조합니다. 프로그램은 메모리의 한 연속 섹션에 opcode와 데이터가 혼합되어 작성될 수 있습니다. 이 접근 방식에는 단점이 있지만 권장되지는 않습니다.
프로그램은 명령을 먼저 작성하고 그 뒤에 데이터(데이텀의 복수형은 데이터)를 작성해야 합니다. 명령어와 데이터 사이의 간격은 몇 바이트에 불과할 수 있습니다. 프로그램의 경우 명령어와 데이터가 모두 메모리의 하나 또는 두 개의 별도 섹션에 있을 수 있습니다.
6.6 하버드 아키텍처
초기 컴퓨터 중 하나는 Harvard Mark I(1944)입니다. 엄격한 Harvard 아키텍처는 프로그램 명령에 하나의 주소 공간을 사용하고 데이터에 대해 서로 다른 별도의 주소 공간을 사용합니다. 이는 두 개의 서로 다른 기억이 있다는 것을 의미합니다. 다음은 아키텍처를 보여줍니다.
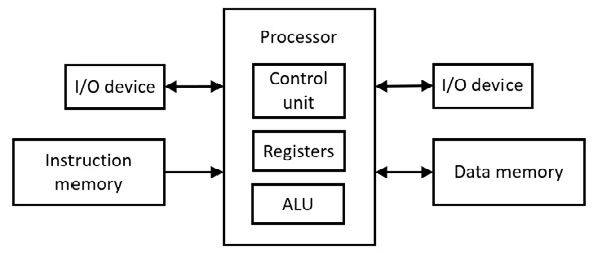
그림 6.71 하버드 아키텍처
제어 장치는 명령어 디코딩을 수행합니다. ALU(산술 논리 장치)는 조합 논리(게이트)를 사용하여 산술 연산을 수행합니다. ALU는 논리 연산(예: 이동)도 수행합니다.
6502 마이크로프로세서를 사용하면 데이터(데이터의 단수)가 µP 레지스터로 이동하기 전에 명령이 먼저 마이크로프로세서(제어 장치)로 이동한 후 상호 작용합니다. 이를 위해서는 최소한 두 개의 클록 펄스가 필요하며 명령과 데이터에 대한 동시 액세스가 아닙니다. 반면에 Harvard 아키텍처는 명령과 데이터가 동시에 µP에 입력되어(제어 장치에 대한 opcode 및 µP 레지스터에 대한 데이터) 명령과 데이터에 대한 동시 액세스를 제공하여 적어도 하나의 클록 펄스를 저장합니다. 이는 병렬성의 한 형태입니다. 이러한 형태의 병렬 처리는 최신 마더보드의 하드웨어 캐시에 사용됩니다(다음 설명 참조).
6.7 캐시 메모리
캐시 메모리(RAM)는 향후 사용을 위해 프로그램 명령이나 데이터를 임시로 저장하는 고속 메모리 영역(메인 메모리 속도 대비)입니다. 캐시 메모리는 메인 메모리보다 빠르게 작동합니다. 일반적으로 이러한 명령어나 데이터 항목은 최근 주 메모리에서 검색되며 곧 다시 필요할 수 있습니다. 캐시 메모리의 주요 목적은 동일한 주 메모리 위치에 반복적으로 액세스하는 속도를 높이는 것입니다. 효과적이려면 캐시된 항목에 액세스하는 것이 백업 저장소라고 하는 명령이나 데이터의 원본 소스에 액세스하는 것보다 훨씬 빨라야 합니다.
캐싱이 사용 중일 때 주 메모리 위치에 액세스하려는 각 시도는 캐시 검색으로 시작됩니다. 요청한 항목이 있으면 프로세서는 즉시 해당 항목을 검색하여 사용합니다. 이를 캐시 히트라고 합니다. 캐시 검색이 실패하면(캐시 누락) 명령어나 데이터 항목을 백업 저장소(주 메모리)에서 검색해야 합니다. 요청한 항목을 검색하는 과정에서 가까운 장래에 사용할 수 있도록 복사본이 캐시에 추가됩니다.
메모리 관리 장치
MMU(Memory Management Unit)는 마더보드의 주 메모리 및 관련 메모리 레지스터를 관리하는 회로입니다. 과거에는 마더보드에 별도의 통합 회로가 있었습니다. 하지만 오늘날에는 일반적으로 마이크로프로세서의 일부입니다. MMU는 오늘날 마이크로프로세서의 일부인 캐시(회로)도 관리해야 합니다. 캐시 회로는 과거에는 별도의 집적 회로였습니다.
정적 RAM
SRAM(Static RAM)은 훨씬 더 복잡한 회로를 희생하더라도 DRAM보다 액세스 시간이 상당히 빠릅니다. SRAM 비트 셀은 동일한 양의 데이터를 저장할 수 있는 DRAM 장치의 셀보다 집적 회로 다이에서 훨씬 더 많은 공간을 차지합니다. 주 메모리(RAM)는 일반적으로 DRAM(Dynamic RAM)으로 구성됩니다.
캐시 메모리는 운영 체제 및 응용 프로그램에서 실행되는 많은 알고리즘이 참조 지역성을 나타내기 때문에 컴퓨터 성능을 향상시킵니다. 참조 지역성은 최근에 접근한 데이터를 재사용하는 것을 의미합니다. 이것을 시간적 지역성(Temporal Locality)이라고 합니다. 최신 마더보드에서 캐시 메모리는 마이크로프로세서와 동일한 집적 회로에 있습니다. 주 메모리(DRAM)는 멀리 떨어져 있으며 버스를 통해 액세스할 수 있습니다. 참조 지역성은 공간적 지역성을 의미하기도 합니다. 공간적 지역성은 물리적 근접성으로 인해 데이터 액세스 속도가 더 빨라지는 것과 관련이 있습니다.
일반적으로 캐시 메모리 영역은 백업 저장소(주 메모리)에 비해 작습니다(바이트 위치 수). 캐시 메모리 장치는 최대 속도를 위해 설계되었으며 이는 일반적으로 백업 저장소에 사용되는 데이터 저장 기술보다 비트당 더 복잡하고 비용이 많이 든다는 것을 의미합니다. 제한된 크기로 인해 캐시 메모리 장치는 빠르게 채워지는 경향이 있습니다. 캐시에 새 항목을 저장할 수 있는 위치가 없으면 이전 항목을 삭제해야 합니다. 캐시 컨트롤러는 캐시 교체 정책을 사용하여 새 항목으로 덮어쓸 캐시 항목을 선택합니다.
마이크로프로세서 캐시 메모리의 목표는 시간이 지남에 따라 캐시 적중률을 최대화하여 가장 높은 지속 명령 실행 속도를 제공하는 것입니다. 이 목표를 달성하려면 캐싱 논리는 어떤 명령과 데이터를 캐시에 배치하고 가까운 미래에 사용할 수 있도록 유지할지 결정해야 합니다.
프로세서의 캐싱 논리에는 캐시된 데이터 항목이 캐시에 삽입된 후에 다시 사용된다는 보장이 없습니다.
캐싱 논리는 시간적(시간에 따라 반복) 및 공간적(공간) 지역성으로 인해 가까운 미래에 캐시된 데이터에 액세스할 가능성이 매우 높다는 가능성에 의존합니다. 최신 프로세서의 실제 구현에서 캐시 적중은 일반적으로 메모리 액세스의 95~97%에서 발생합니다. 캐시 메모리의 대기 시간은 DRAM 대기 시간의 작은 부분이므로 높은 캐시 적중률은 캐시 없는 설계에 비해 상당한 성능 향상을 가져옵니다.
캐시와의 일부 병렬성
앞서 언급했듯이 메모리에 있는 좋은 프로그램은 데이터와 명령어가 분리되어 있습니다. 일부 캐시 시스템에는 프로세서의 '왼쪽'에 캐시 회로가 있고 프로세서의 '오른쪽'에 또 다른 캐시 회로가 있습니다. 왼쪽 캐시는 프로그램(또는 애플리케이션)의 명령을 처리하고 오른쪽 캐시는 동일한 프로그램(또는 동일한 애플리케이션)의 데이터를 처리합니다. 이로 인해 속도가 더 향상됩니다.
6.8 프로세스와 스레드
CISC와 RISC 컴퓨터 모두 프로세스가 있습니다. 소프트웨어에 프로세스가 있습니다. 실행 중인(실행 중인) 프로그램은 프로세스입니다. 운영 체제에는 자체 프로그램이 함께 제공됩니다. 컴퓨터가 작동하는 동안 컴퓨터가 작동할 수 있도록 해주는 운영 체제의 프로그램도 실행됩니다. 이는 운영 체제 프로세스입니다. 사용자나 프로그래머는 자신의 프로그램을 작성할 수 있습니다. 사용자의 프로그램이 실행 중일 때는 프로세스입니다. 프로그램이 어셈블리 언어로 작성되었는지, C나 C++ 같은 고급 언어로 작성되었는지는 중요하지 않습니다. 모든 프로세스(사용자 또는 OS)는 '스케줄러'라는 또 다른 프로세스에 의해 관리됩니다.
스레드는 프로세스에 속하는 하위 프로세스와 같습니다. 프로세스는 시작되어 스레드로 분할된 다음 여전히 하나의 프로세스로 계속될 수 있습니다. 스레드가 없는 프로세스는 기본 스레드로 간주될 수 있습니다. 프로세스와 해당 스레드는 동일한 스케줄러에 의해 관리됩니다. 스케줄러 자체는 OS 디스크에 상주하는 경우 프로그램입니다. 메모리에서 실행될 때 스케줄러는 프로세스입니다.
6.9 다중 처리
스레드는 거의 프로세스처럼 관리됩니다. 다중 처리란 동시에 두 개 이상의 프로세스를 실행하는 것을 의미합니다. 마이크로프로세서가 하나만 있는 컴퓨터도 있습니다. 두 개 이상의 마이크로프로세서를 갖춘 컴퓨터가 있습니다. 단일 마이크로프로세서의 경우 프로세스 및/또는 스레드는 인터리빙(또는 시간 분할) 방식으로 동일한 마이크로프로세서를 사용합니다. 이는 프로세스가 프로세서를 사용하고 완료되지 않고 중지됨을 의미합니다. 다른 프로세스나 스레드가 프로세서를 사용하고 완료되지 않고 중지됩니다. 그런 다음 다른 프로세스나 스레드가 마이크로프로세서를 사용하고 완료되지 않고 중지됩니다. 이는 스케줄러에 의해 대기열에 추가된 모든 프로세스와 스레드가 프로세서를 공유하게 될 때까지 계속됩니다. 이를 동시 다중 처리라고 합니다.
두 개 이상의 마이크로프로세서가 있는 경우 동시성이 아닌 병렬 다중 처리가 발생합니다. 이 경우 각 프로세서는 다른 프로세서가 실행하는 것과는 다른 특정 프로세스나 스레드를 실행합니다. 동일한 마더보드의 모든 프로세서는 병렬 다중 처리를 통해 서로 다른 프로세스 및/또는 서로 다른 스레드를 동시에 실행합니다. 병렬 다중 처리의 프로세스와 스레드는 여전히 스케줄러에 의해 관리됩니다. 병렬 다중 처리는 동시 다중 처리보다 빠릅니다.
이 시점에서 독자는 병렬 처리가 동시 처리보다 얼마나 빠른지 궁금해할 수 있습니다. 이는 프로세서가 동일한 메모리와 입력/출력 포트를 공유(다른 시간에 사용해야 함)하기 때문입니다. 글쎄, 캐시를 사용하면 마더보드의 전반적인 작동이 더 빨라집니다.
6.10 페이징
MMU(Memory Management Unit)는 마이크로프로세서 또는 마이크로프로세서 칩에 가까운 회로입니다. 메모리 맵이나 페이징 및 기타 메모리 문제를 처리합니다. 6502 µP나 Commodore-64 컴퓨터에는 MMU 자체가 없습니다(Commodore-64에는 여전히 일부 메모리 관리 기능이 있지만). Commodore-64는 각 페이지가 256인 페이징을 통해 메모리를 처리합니다. 10 바이트 길이(100 16 바이트 길이). 페이징을 통해 메모리를 처리하는 것은 의무사항이 아니었습니다. 여전히 메모리 맵만 있고 다른 지정된 영역에 딱 맞는 프로그램만 있을 수 있습니다. 음, 페이징은 데이터나 프로그램을 가질 수 없는 많은 메모리 섹션을 갖지 않고도 메모리를 효율적으로 사용하는 한 가지 방법입니다.
x86 386 컴퓨터 아키텍처는 1985년에 출시되었습니다. 주소 버스의 폭은 32비트입니다. 그래서 총 2개 32 = 4,294,967,296 주소 공간이 가능합니다. 이 주소 공간은 1,048,576페이지 = 1,024KB 페이지로 나뉩니다. 이 페이지 수를 사용하면 한 페이지는 4,096바이트 = 4KB로 구성됩니다. 다음 표는 x86 32비트 아키텍처의 물리적 주소 페이지를 보여줍니다.
| 표 6.10.1 x86 아키텍처의 물리적 주소 지정 가능 페이지 |
||
|---|---|---|
| 기본 16 주소 | 페이지 | 기본 10 주소 |
| FFFFF000 – FFFFFFFF | 페이지 1,048,575 | 4,294,963,200 – 4,294,967,295 |
| FFFFE000 – FFFFEFFF | 페이지 1,044,479 | 4,294,959,104 – 4,294,963,199 |
| FFFFD000 – FFFFDFFF | 페이지 1,040,383 | 4,294,955,008 – 4,294,959,103 |
| | | | |
| | | |
| | | |
| 00002000 – 00002FFF | 2 쪽 | 8,192 – 12,288 |
| 00001000 – 00001FFF | 페이지 1 | 4,096 – 8,191 |
| 00000000 – 00000FFF | 페이지 0 | 0 – 4,095 |
오늘날 응용 프로그램은 두 개 이상의 프로그램으로 구성됩니다. 하나의 프로그램은 한 페이지 미만(4096 미만)을 차지하거나 두 페이지 이상을 차지할 수 있습니다. 따라서 애플리케이션은 각 페이지 길이가 4096바이트인 하나 이상의 페이지를 사용할 수 있습니다. 여러 사람이 신청서를 작성할 수 있으며 각 사람은 하나 이상의 페이지에 할당됩니다.
페이지 0은 00000000H에서 00000FFF까지입니다.
페이지 1은 00001000H부터 00001FFFH까지이고, 페이지 2는 00002000까지입니다. 시간 – 00002FFF 시간 , 등등. 32비트 컴퓨터의 경우 물리적 페이지 주소 지정을 위해 프로세서에 두 개의 32비트 레지스터가 있습니다. 하나는 기본 주소용이고 다른 하나는 인덱스 주소용입니다. 예를 들어 페이지 2의 바이트 위치에 액세스하려면 기본 주소 레지스터가 00002여야 합니다. 시간 이는 페이지 2 시작 주소의 처음 20비트(왼쪽부터)입니다. 000 범위의 나머지 비트 시간 FFF로 시간 '인덱스 레지스터'라는 레지스터에 있습니다. 따라서 페이지의 모든 바이트는 인덱스 레지스터의 내용을 000에서 증가시키는 것만으로 액세스할 수 있습니다. 시간 FFF로 시간 . 인덱스 레지스터의 내용은 기본 레지스터의 변경되지 않는 내용에 추가되어 유효 주소를 얻습니다. 이 인덱스 주소 지정 체계는 다른 페이지에도 적용됩니다.
그러나 이는 실제로 어셈블리 언어 프로그램이 각 페이지에 대해 작성되는 방식이 아닙니다. 각 페이지마다 프로그래머는 000페이지부터 시작하는 코드를 작성합니다. 시간 FFF 페이지로 시간 . 서로 다른 페이지의 코드가 연결되어 있으므로 컴파일러는 인덱스 주소 지정을 사용하여 서로 다른 페이지의 모든 관련 주소를 연결합니다. 예를 들어 페이지 0, 페이지 1, 페이지 2가 하나의 애플리케이션에 대한 것이고 각각 555개의 페이지를 가지고 있다고 가정합니다. 시간 주소가 서로 연결되어 있으면 컴파일러는 555가 발생하는 방식으로 컴파일합니다. 시간 페이지 0에 액세스할 예정입니다. 00000 시간 기본 레지스터에 있고 555 시간 인덱스 레지스터에 있을 것이다. 555일 때 시간 페이지 1의 00001에 액세스할 예정입니다. 시간 기본 레지스터에 있고 555 시간 인덱스 레지스터에 있을 것이다. 555일 때 시간 페이지 2에 액세스할 예정입니다. 00002 시간 기본 레지스터에 있고 555H는 인덱스 레지스터에 있습니다. 이는 라벨(변수)을 이용하여 주소를 식별할 수 있기 때문에 가능합니다. 서로 다른 프로그래머는 서로 다른 연결 주소에 사용할 라벨 이름에 동의해야 합니다.
페이지 가상 메모리
앞서 설명한 것처럼 페이징은 '페이지 가상 메모리'라고 하는 기술을 통해 메모리 크기를 늘리도록 수정될 수 있습니다. 앞서 설명한 대로 모든 물리적 메모리 페이지에 무언가(명령어 및 데이터)가 있다고 가정하면 모든 페이지가 현재 활성화되어 있는 것은 아닙니다. 현재 활성화되지 않은 페이지는 하드 디스크로 전송되고 실행해야 하는 하드 디스크의 페이지로 대체됩니다. 그런 식으로 메모리의 크기가 늘어납니다. 컴퓨터가 계속 작동하면 비활성화된 페이지는 메모리에서 디스크로 전송된 페이지일 수 있는 하드 디스크의 페이지와 교체됩니다. 이 모든 작업은 메모리 관리 장치(MMU)에 의해 수행됩니다.
6.11 문제점
독자는 다음 장으로 넘어가기 전에 한 장의 모든 문제를 해결하는 것이 좋습니다.
1) CISC와 RISC 컴퓨터 아키텍처의 유사점과 차이점을 설명하세요. SISC 및 RISC 컴퓨터의 예를 하나씩 말해보세요.
2) a) 비트 단위로 CISC 컴퓨터의 이름은 무엇입니까: 바이트, 워드, 더블워드, 쿼드워드, 더블 쿼드워드.
b) 비트 단위로 RISC 컴퓨터의 이름은 바이트, 하프워드, 워드, 더블워드로 무엇입니까?
c) 예 또는 아니요. 더블워드와 쿼드워드는 CISC와 RISC 아키텍처 모두에서 동일한 의미입니까?
3 a) x64의 경우 어셈블리 언어 명령어의 바이트 수는 무엇부터 무엇까지입니까?
b) ARM 64에 대한 모든 어셈블리 언어 명령어의 바이트 수가 고정되어 있습니까? 그렇다면 모든 명령어의 바이트 수는 얼마입니까?
4) x64에 가장 일반적으로 사용되는 어셈블리 언어 명령어와 그 의미를 나열하십시오.
5) ARM 64에 가장 일반적으로 사용되는 어셈블리 언어 명령어와 그 의미를 나열합니다.
6) 오래된 컴퓨터인 Harvard Architecture의 블록 다이어그램을 그려보세요. 최신 컴퓨터의 캐시에서 명령어와 데이터 기능이 어떻게 사용되는지 설명하세요.
7) 프로세스와 스레드를 구별하고 대부분의 컴퓨터 시스템에서 프로세스와 스레드를 처리하는 프로세스의 이름을 알려줍니다.
8) 멀티프로세싱이 무엇인지 간략하게 설명해주세요.
9) a) x86 386 µP 컴퓨터 아키텍처에 적용 가능한 페이징을 설명하십시오.
b) 이 페이징을 어떻게 수정하여 전체 메모리 크기를 늘릴 수 있습니까?