전제 조건
이 자습서의 예제를 연습하기 전에 클라이언트와 함께 데이터베이스 서버를 설치해야 합니다. MariaDB 데이터베이스 서버와 클라이언트는 이 튜토리얼에서 사용됩니다.
1. 다음 명령을 실행하여 시스템을 업데이트합니다.
$ sudo apt-get 업데이트
2. 다음 명령을 실행하여 MariaDB 서버 및 클라이언트를 설치합니다.
$ sudo apt-get 설치 mariadb-server mariadb-client
3. 다음 명령을 실행하여 MariaDB 데이터베이스용 보안 스크립트를 설치합니다.
$ sudo mysql_secure_installation
4. 다음 명령을 실행하여 MariaDB 서버를 다시 시작합니다.
$ sudo /etc/init.d/mariadb 재시작
6. 다음 명령을 실행하여 MariaDB 서버에 로그인합니다.
$ sudo mariadb -u 루트 -pSQL 쿼리 예제 목록
- 데이터베이스 만들기
- 테이블 만들기
- 테이블 이름 바꾸기
- 테이블에 새 열 추가
- 테이블에서 열 제거
- 테이블에 단일 행 삽입
- 테이블에 여러 행 삽입
- 테이블에서 모든 특정 필드 읽기
- 테이블에서 데이터를 필터링한 후 테이블 읽기
- 부울 논리를 기반으로 데이터를 필터링한 후 테이블 읽기
- 데이터 범위에 따라 행을 필터링한 후 테이블 읽기
- 특정 열을 기준으로 테이블을 정렬한 후 테이블을 읽습니다.
- 열의 대체 이름을 설정하여 테이블 읽기
- 테이블의 총 행 수 계산
- 여러 테이블에서 데이터 읽기
- 특정 필드를 그룹화하여 테이블 읽기
- 중복 값을 생략한 후 테이블 읽기
- 행 번호를 제한하여 테이블 읽기
- 부분 일치를 기반으로 테이블 읽기
- 테이블의 특정 필드 합계 계산
- 특정 필드의 최대값과 최소값 찾기
- 필드의 특정 부분에 대한 데이터 읽기
- 연결 후 테이블 데이터 읽기
- 수학 계산 후 테이블 데이터 읽기
- 테이블 보기 생성
- 특정 조건에 따라 테이블 업데이트
- 특정 조건에 따라 테이블 데이터 삭제
- 테이블에서 모든 레코드 삭제
- 테이블을 드롭
- 데이터베이스 삭제
데이터베이스 만들기
Library Management System을 위한 간단한 데이터베이스를 설계해야 한다고 가정합니다. 이 작업을 수행하려면 여러 관계형 테이블을 포함하는 데이터베이스가 서버에 생성되어야 합니다. 데이터베이스 서버에 로그인한 후 다음 명령을 실행하여 MariaDB 데이터베이스 서버에 'library'라는 데이터베이스를 생성합니다.
만들다 데이터 베이스 도서관;출력은 라이브러리 데이터베이스가 서버에 생성되었음을 보여줍니다.
 다음 명령을 실행하여 다양한 유형의 데이터베이스 작업을 수행할 서버에서 데이터베이스를 선택합니다.
다음 명령을 실행하여 다양한 유형의 데이터베이스 작업을 수행할 서버에서 데이터베이스를 선택합니다.
출력은 라이브러리 데이터베이스가 선택되었음을 보여줍니다.

테이블 만들기
다음 단계는 데이터베이스가 데이터를 저장하는 데 필요한 테이블을 만드는 것입니다. 자습서의 이 부분에서는 세 개의 테이블이 생성됩니다. 이들은 책, 구성원 및 Borrow_info 테이블입니다.
- books 테이블은 모든 책 관련 데이터를 저장합니다.
- 구성원 테이블은 도서관에서 책을 빌린 구성원에 대한 모든 정보를 저장합니다.
- Borrow_info 테이블은 어떤 회원이 어떤 책을 빌렸는지에 대한 정보를 저장합니다.
1. 책 테이블
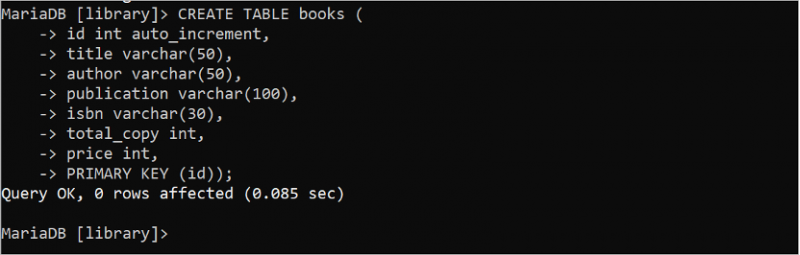
다음 SQL 문을 실행하여 'library' 데이터베이스에 7개의 필드와 1개의 기본 키가 포함된 'books'라는 테이블을 만듭니다. 여기서 'id' 필드는 기본 키이고 데이터 유형은 int입니다. auto_increment 속성은 'id' 필드에 사용됩니다. 따라서 이 필드의 값은 새 행이 삽입될 때 자동으로 증가합니다. varchar 데이터 유형은 가변 길이의 문자열 데이터를 저장하는 데 사용됩니다. 제목, 저자, 출판 및 isbn 필드는 문자열 데이터를 저장합니다. total_copy 및 price 필드의 데이터 유형은 int입니다. 따라서 이러한 필드는 숫자 데이터를 저장합니다.
만들다 테이블 서적 (ID 지능 자동 증가 ,
제목 VARCHAR ( 오십 ) ,
작가 VARCHAR ( 오십 ) ,
출판 VARCHAR ( 100 ) ,
isbn VARCHAR ( 30 ) ,
total_copy 지능 ,
가격 지능 ,
주요한 열쇠 ( ID ) ) ;
출력은 'books' 테이블이 성공적으로 생성되었음을 보여줍니다.
2. 회원 테이블
다음 SQL 문을 실행하여 5개의 필드와 1개의 기본 키를 포함하는 'library' 데이터베이스에 'members'라는 테이블을 만듭니다. 'id' 필드에는 'books' 테이블과 같은 auto_increment 속성이 있습니다. 다른 필드의 데이터 유형은 varchar입니다. 따라서 이러한 필드는 문자열 데이터를 저장합니다.
만들다 테이블 회원 (ID 지능 자동 증가 ,
이름 VARCHAR ( 오십 ) ,
주소 VARCHAR ( 200 ) ,
contact_no VARCHAR ( 열 다섯 ) ,
이메일 VARCHAR ( 오십 ) ,
주요한 열쇠 ( ID ) ) ;
출력은 'members' 테이블이 성공적으로 생성되었음을 보여줍니다.

3. Borrow_info 테이블
다음 SQL 문을 실행하여 'library' 데이터베이스에 6개의 필드가 포함된 'borrow_info'라는 테이블을 만듭니다. 여기서 'id' 필드는 기본 키이지만 auto_increment 속성은 이 필드에 사용되지 않습니다. 따라서 새 레코드가 테이블에 삽입될 때 고유한 값이 이 필드에 수동으로 삽입됩니다. book_id 및 member_id 필드는 이 테이블의 외래 키입니다. 이들은 'books' 테이블과 'members' 테이블의 기본 키입니다. Borrow_date 및 return_date 필드의 데이터 유형은 날짜입니다. 따라서 이 두 필드는 'YYYY-MM-DD' 형식으로 날짜 값을 저장합니다.
만들다 테이블 빌린_정보 (ID 지능 ,
빌린 날짜 날짜 ,
book_id 지능 ,
회원 ID 지능 ,
반환 기일 날짜 ,
상태 VARCHAR ( 10 ) ,
주요한 열쇠 ( ID ) ,
외국의 열쇠 ( book_id ) 참조 서적 ( ID ) ,
외국의 열쇠 ( 회원 ID ) 참조 회원 ( ID ) ) ;
출력은 'borrow_info' 테이블이 성공적으로 생성되었음을 보여줍니다.

테이블 이름 바꾸기
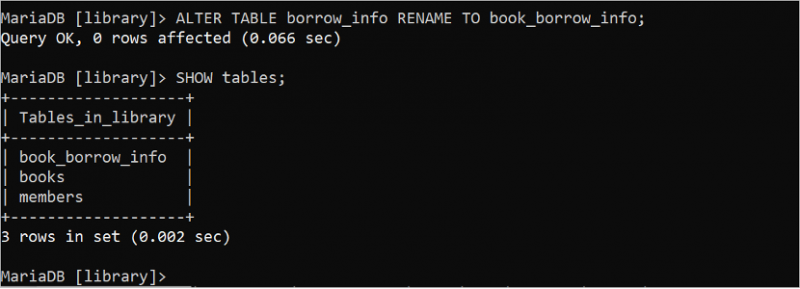
ALTER TABLE 문은 SQL 문에서 여러 목적으로 사용될 수 있습니다. 다음 ALTER TABLE 문을 실행하여 'borrow_info' 테이블의 이름을 'book_borrow_info'로 변경합니다. 다음으로 SHOW tables 문을 사용하여 테이블 이름이 변경되었는지 확인할 수 있습니다.
바꾸다 테이블 빌린_정보 이름 바꾸기 에게 book_borrow_info;보여주다 테이블 ;
출력은 테이블 이름이 성공적으로 변경되었고 borrow_info 테이블의 이름이 book_borrow_info로 변경되었음을 보여줍니다.
테이블에 새 열 추가
ALTER TABLE 문을 사용하여 테이블을 생성한 후 하나 이상의 열을 추가하거나 삭제할 수 있습니다. 다음 ALTER TABLE 문은 'status'라는 새 필드를 테이블 멤버에 추가합니다. DESCRIBE 문은 테이블 구조가 변경되었는지 여부를 표시하는 데 사용됩니다.
바꾸다 테이블 회원 추가하다 상태 VARCHAR ( 10 ) ;설명하다 회원;
출력은 'status'인 새 열이 'members' 테이블에 추가되고 테이블의 데이터 유형이 varchar임을 보여줍니다.

테이블에서 열 제거
다음 ALTER TABLE 문은 'members' 테이블에서 'status'라는 필드를 삭제합니다. DESCRIBE 문은 테이블 구조가 변경되었는지 여부를 표시하는 데 사용됩니다.
바꾸다 테이블 회원 떨어지다 열 상태 ;설명하다 회원;
출력은 '구성원' 테이블에서 '상태' 열이 제거되었음을 보여줍니다.

테이블에 단일 행 삽입
INSERT INTO 문은 하나 이상의 행을 테이블에 삽입하는 데 사용됩니다. 다음 SQL 문을 실행하여 'books' 테이블에 단일 행을 삽입합니다. 여기서 'id' 필드는 auto-increment 속성에 대해 새 레코드가 삽입될 때 레코드에 자동으로 삽입되기 때문에 이 쿼리에서 생략됩니다. 이 필드가 INSERT 문에서 사용되는 경우 값은 NULL이어야 합니다.
끼워 넣다 안으로 서적 ( 제목 , 작가 , 출판 , isbn , total_copy , 가격 )가치 ( '10분 만에 SQL' , '벤 포르타' , '샘스 퍼블리싱' , '784534235' , 5 , 39 ) ;
출력은 'books' 테이블에 레코드가 성공적으로 추가되었음을 보여줍니다.

각 필드 값이 별도로 할당되는 SET 절을 사용하여 데이터를 테이블에 삽입할 수 있습니다. 다음 SQL 문을 실행하여 INSERT INTO 및 SET 절을 사용하여 'members' 테이블에 단일 행을 삽입합니다. 이 쿼리에서도 같은 이유로 이전 예제와 같이 'id' 필드가 생략되었습니다.
끼워 넣다 안으로 회원세트 이름 = '존 시나' , 주소 = '34, 단몬디 9/A, 다카' , contact_no = '+14844731336' , 이메일 = 'john@gmail.com' ;
출력은 레코드가 구성원 테이블에 성공적으로 추가되었음을 보여줍니다.

다음 SQL 문을 실행하여 'book_borrow_info' 테이블에 단일 행을 삽입합니다.
끼워 넣다 안으로 book_borrow_info ( ID , 빌린 날짜 , book_id , 회원 ID , 반환 기일 , 상태 )가치 ( 1 , '2023-03-12' , 1 , 1 , '2023-03-19' , '빌린' ) ;
출력은 'book_borrow_info' 테이블에 레코드가 추가되었음을 보여줍니다.

테이블에 여러 행 삽입
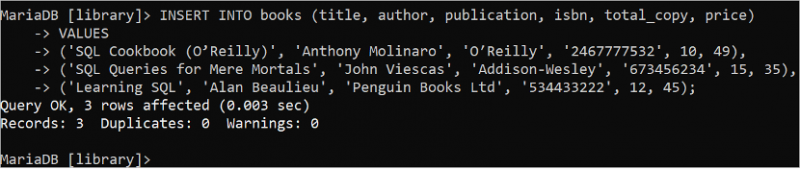
경우에 따라 단일 INSERT INTO 문을 사용하여 한 번에 많은 레코드를 추가해야 합니다. 다음 SQL 문을 실행하여 단일 INSERT INTO 문을 사용하여 'books' 테이블에 세 개의 레코드를 삽입합니다. 이 경우 VALUES 절은 1회만 사용되며 각 레코드의 데이터는 쉼표로 구분됩니다.
끼워 넣다 안으로 서적 ( 제목 , 작가 , 출판 , isbn , total_copy , 가격 )가치
( 'SQL 요리책(O'Reilly)' , '앤서니 몰리나로' , '오라일리' , '2467777532' , 10 , 49 ) ,
( '단순한 인간을 위한 SQL 쿼리' , '존 비에스카스' , '애디슨-웨슬리' , '673456234' , 열 다섯 , 35 ) ,
( '학습 SQL' , '앨런 보리외' , '펭귄북스 주식회사' , '534433222' , 12 , 넷 다섯 ) ;
출력은 'books' 테이블에 세 개의 레코드가 추가되었음을 보여줍니다.
테이블에서 모든 특정 필드 읽기
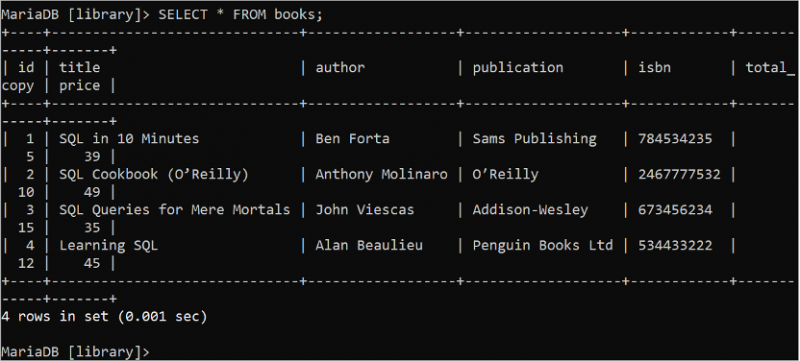
SELECT 문은 '데이터베이스' 테이블에서 데이터를 읽는 데 사용됩니다. '*' 기호는 SELECT 문에서 테이블의 모든 필드를 나타내는 데 사용됩니다. 다음 SQL 명령을 실행하여 books 테이블의 모든 레코드를 읽습니다.
선택하다 * 에서 서적;출력에는 4개의 레코드가 포함된 books 테이블의 모든 레코드가 표시됩니다.
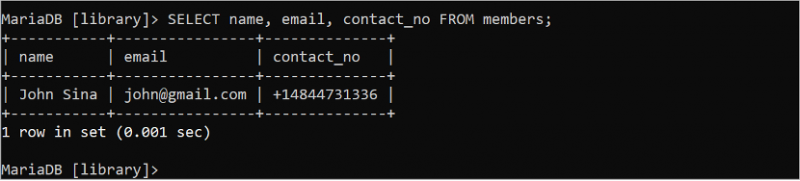
다음 SQL 명령을 실행하여 'members' 테이블의 세 필드에 대한 모든 레코드를 읽습니다.
선택하다 이름 , 이메일 , contact_no 에서 회원;출력에는 '구성원' 테이블의 세 필드에 대한 모든 레코드가 표시됩니다.
테이블에서 데이터를 필터링한 후 테이블 읽기
WHERE 절은 하나 이상의 조건에 따라 테이블에서 데이터를 읽는 데 사용됩니다. 다음 SELECT 문을 실행하여 저자 이름이 'John Viescas'인 'books' 테이블의 모든 필드에 대한 모든 레코드를 읽습니다.
선택하다 * 에서 서적 어디 작가 = '존 비에스카스' ;'books' 테이블에는 출력에 표시된 WHERE 절의 조건과 일치하는 하나의 레코드가 포함되어 있습니다.

부울 논리를 기반으로 데이터를 필터링한 후 테이블 읽기
부울 AND 논리는 모든 조건이 true를 반환하는 경우 true를 반환하는 WHERE 절에서 여러 조건을 정의하는 데 사용됩니다. 논리적 AND를 사용하여 total_copy 필드의 값이 10보다 크고 price 필드의 값이 45보다 작은 'books' 테이블의 모든 필드의 모든 레코드를 읽으려면 다음 SELECT 문을 실행하십시오.
선택하다 * 에서 서적 어디 total_copy > 10 그리고 가격 < 넷 다섯 ;books 테이블에는 출력에 표시되는 WHERE 절의 조건과 일치하는 하나의 레코드가 포함되어 있습니다.

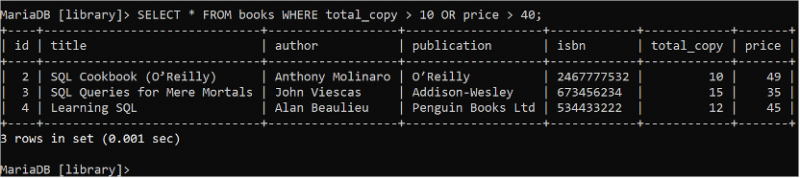
부울 OR 논리는 조건 중 하나라도 true를 반환하는 경우 true를 반환하는 WHERE 절에서 여러 조건을 정의하는 데 사용됩니다. 다음 SELECT 문을 실행하여 total_copy 필드 값이 10보다 크거나 price 필드 값이 40보다 큰 'books' 테이블의 모든 필드 레코드를 모두 읽습니다.
선택하다 * 에서 서적 어디 total_copy > 10 또는 가격 > 40 ;books 테이블에는 출력에 표시되는 WHERE 절의 조건과 일치하는 세 개의 레코드가 포함되어 있습니다.
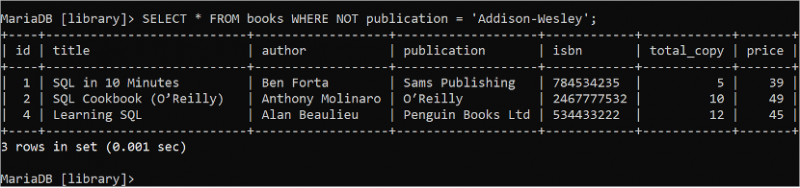
부울 NOT 논리는 조건이 참일 때 거짓을 반환하고 조건이 거짓일 때 참을 반환하는 데 사용됩니다. 저자 필드의 값이 'Addison-Wesley'가 아닌 'books' 테이블의 모든 필드의 모든 레코드를 읽으려면 다음 SELECT 문을 실행하십시오.
선택하다 * 에서 서적 어디 아니다 작가 = '애디슨-웨슬리' ;'books' 테이블에는 출력에 표시된 WHERE 절의 조건과 일치하는 세 개의 레코드가 포함되어 있습니다.
데이터 범위에 따라 행을 필터링한 후 테이블 읽기
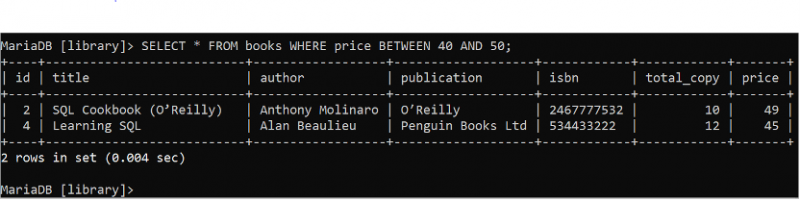
BETWEEN 절은 데이터베이스 테이블에서 데이터 범위를 읽는 데 사용됩니다. 다음 SELECT 문을 실행하여 price 필드 값이 40에서 50 사이인 'books' 테이블의 모든 필드 레코드를 모두 읽습니다.
선택하다 * 에서 서적 어디 가격 사이 40 그리고 오십 ;books 테이블에는 출력에 표시되는 WHERE 절의 조건과 일치하는 두 개의 레코드가 포함되어 있습니다. 가격 값의 장부 39와 35는 범위를 벗어났기 때문에 결과 세트에서 생략됩니다.
테이블 정렬 후 테이블 읽기
ORDER BY 절은 SELECT 문의 결과 집합을 오름차순 또는 내림차순으로 정렬하는 데 사용됩니다. ASC 또는 DESC 없이 ORDER BY 절을 사용하는 경우 결과 집합은 기본적으로 오름차순으로 정렬됩니다. 다음 SELECT 문은 제목 필드를 기반으로 books 테이블에서 정렬된 레코드를 읽습니다.
선택하다 * 에서 서적 주문하다 에 의해 제목;'books' 테이블의 제목 필드 데이터는 출력에서 오름차순으로 정렬됩니다. 'Learning SQL' 책은 'books' 테이블의 제목 필드가 오름차순으로 정렬된 경우 알파벳순으로 먼저 옵니다.
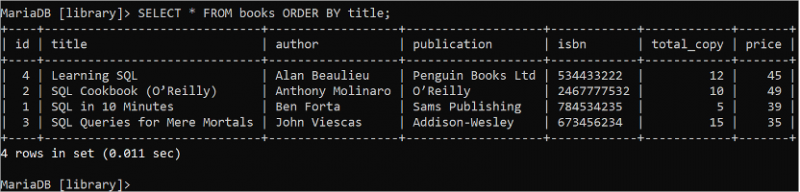
열의 대체 이름을 설정하여 테이블 읽기
열의 대체 이름은 쿼리에서 결과 집합을 더 읽기 쉽게 만드는 데 사용됩니다. 대체 이름은 'AS' 키워드를 사용하여 설정됩니다. 다음 SQL 문은 대체 이름을 설정하여 제목 및 작성자 필드의 값을 반환합니다.
선택하다 제목 처럼 `도서명` , 작가 처럼 '저자 이름'에서 서적;
제목 필드는 '책 이름'이라는 대체 이름으로 표시되고 저자 필드는 출력에서 '저자 이름'이라는 대체 이름으로 표시됩니다.
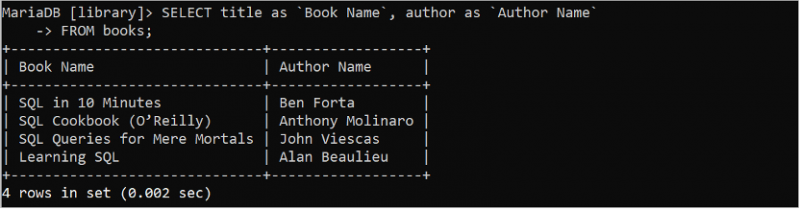
테이블의 총 행 수 계산
COUNT()는 특정 필드 또는 모든 필드를 기반으로 총 행 수를 계산하는 데 사용되는 SQL의 집계 함수입니다. '*' 기호는 모든 필드를 나타내는 데 사용되며 COUNT(*)는 테이블의 모든 레코드를 계산하는 데 사용됩니다.
다음 쿼리는 books 테이블의 총 레코드 수를 계산합니다.
선택하다 세다 ( * ) 처럼 `총 도서` 에서 서적;'books' 테이블의 4개 레코드가 출력에 표시됩니다.

다음 쿼리는 'id' 필드를 기반으로 'members' 테이블의 총 행 수를 계산합니다.
선택하다 세다 ( ID ) 처럼 `총 구성원` 에서 회원;'구성원' 테이블에는 출력에 인쇄되는 두 개의 id 값이 있습니다.
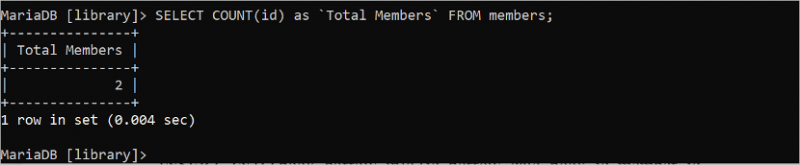
여러 테이블에서 데이터 읽기
이전 SELECT 문은 단일 테이블에서 데이터를 검색했습니다. 그러나 SELECT 문을 사용하여 둘 이상의 테이블에서 데이터를 검색할 수 있습니다. 다음 SELECT 쿼리는 'books' 테이블의 제목 및 저자 필드 값과 'book_borrow_info' 테이블의 Borrow_date 값을 읽습니다.
선택하다 제목 , 작가 , 빌린 날짜에서 서적 , book_borrow_info
어디 서적 . ID = book_borrow_info . book_id;
다음 출력은 'SQL in 10 Minutes' 책이 두 번 빌리고 'SQL Cookbook(O'Reilly)' 책이 한 번 빌린 것을 보여줍니다.
이 튜토리얼에서 설명하지 않는 INNER JOIN, OUTER JOIN 등과 같은 다양한 유형의 JOINS를 사용하여 여러 테이블에서 데이터를 검색할 수 있습니다.
특정 필드를 그룹화하여 테이블 읽기
GROUP BY 절은 하나 이상의 필드를 기반으로 행을 그룹화하여 테이블에서 레코드를 읽는 데 사용됩니다. 이러한 유형의 쿼리를 요약 쿼리라고 합니다. GROUP BY 절 사용 여부를 확인하려면 테이블에 여러 행을 삽입해야 합니다. 다음 INSERT 문을 실행하여 'members' 테이블에 하나의 레코드를 삽입하고 'book_borrow_info' 테이블에 두 개의 레코드를 삽입합니다.
끼워 넣다 안으로 회원세트 이름 = '쉬 하산' , 주소 = '11/A, 지가톨라, 다카' , contact_no = '+8801734563423' , 이메일 = 'she@gmail.com' ;
끼워 넣다 안으로 book_borrow_info ( ID , 빌린 날짜 , book_id , 회원 ID , 반환 기일 , 상태 )
가치 ( 2 , '2023-04-10' , 1 , 1 , '2023-04-15' , '반환' ) ;
끼워 넣다 안으로 book_borrow_info ( ID , 빌린 날짜 , book_id , 회원 ID , 반환 기일 , 상태 )
가치 ( 삼 , '2023-05-20' , 2 , 1 , '2023-05-30' , '빌린' ) ;
앞의 질의를 수행하여 데이터를 삽입한 후 GROUP BY 절을 이용하여 회원별 총 대출 도서 수와 회원 이름을 세는 다음 SELECT 문을 실행한다. 여기서 COUNT() 함수는 GROUP BY 절을 사용하여 레코드를 다시 그룹화하는 데 사용되는 필드에서 작동합니다. '구성원' 테이블의 book_id 필드는 여기에서 그룹화하는 데 사용됩니다.
선택하다 세다 ( book_id ) 처럼 `총 대출 도서` , 이름 처럼 `멤버 이름` 에서 서적 , 회원 , book_borrow_info 어디 서적 . ID = book_borrow_info . book_id 그리고 회원 . ID = book_borrow_info . 회원 ID 그룹 에 의해 book_borrow_info . 회원 ID;books, 'members' 및 'book_borrow_info' 테이블의 데이터에 따르면 'John Sina'는 2권, 'Ella Hasan'은 1권을 빌렸습니다.

중복 값을 생략한 후 테이블 읽기
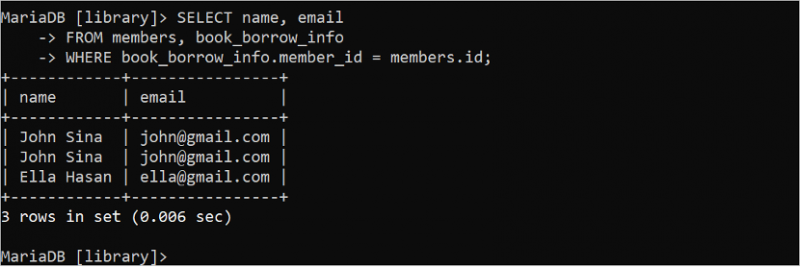
간혹 불필요한 테이블 데이터를 기반으로 SELECT 문의 결과 집합에 중복 데이터가 생성되는 경우가 있다. 예를 들어, 다음 SELECT 문은 'book_borrow_info' 테이블의 데이터에 대한 중복 레코드를 반환합니다.
선택하다 이름 , 이메일에서 회원 , book_borrow_info
어디 book_borrow_info . 회원 ID = 회원 . ID;
출력에서 'John Sina' 회원이 두 권의 책을 빌렸기 때문에 동일한 레코드가 두 번 나타납니다. 이 문제는 DISTINCT 키워드를 사용하여 해결할 수 있습니다. 쿼리 결과에서 중복 레코드를 제거합니다.
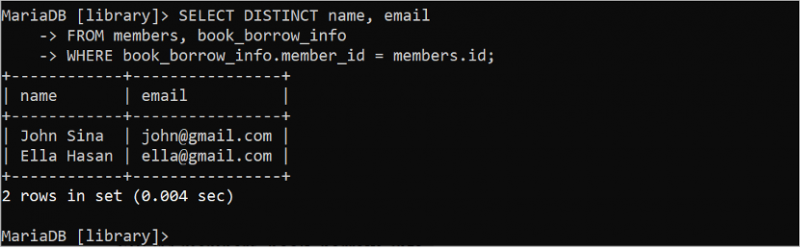
다음 SELECT 문은 쿼리에서 DISTINCT 키워드를 사용하여 중복 값을 생략한 후 'members' 및 'book_borrow_info' 테이블에서 결과 집합의 고유한 레코드를 생성합니다.
선택하다 별개의 이름 , 이메일에서 회원 , book_borrow_info
어디 book_borrow_info . 회원 ID = 회원 . ID;
출력은 결과 세트에서 중복 값이 제거되었음을 보여줍니다.
행 번호를 제한하여 테이블 읽기
경우에 따라 행 번호를 제한하여 데이터베이스 테이블에서 결과 집합의 시작, 결과 집합의 끝 또는 결과 집합의 중간에서 특정 수의 레코드를 읽어야 합니다. 여러 가지 방법으로 할 수 있습니다. 행을 제한하기 전에 다음 SQL 문을 실행하여 books 테이블에 존재하는 레코드 수를 확인하십시오.
선택하다 * 에서 서적;출력은 books 테이블에 4개의 레코드가 있음을 보여줍니다.

다음 SELECT 문은 값이 2인 LIMIT 절을 사용하여 'books' 테이블에서 처음 두 레코드를 읽습니다.
선택하다 * 에서 서적 한계 2 ;'books' 테이블의 처음 두 레코드가 검색되어 출력에 표시됩니다.

FETCH 절은 LIMIT 절 대신 사용할 수 있으며 다음 SELECT 문에 그 사용법이 나와 있습니다. 'books' 테이블의 처음 3개 레코드는 SELECT 문의 FETCH FIRST 3 ROWS ONLY 절을 사용하여 검색됩니다.
선택하다 * 에서 책 가져오기 첫 번째 삼 행 오직 ;출력에는 'books' 테이블의 처음 3개 레코드가 표시됩니다.

3에서 두 레코드 일 books 테이블의 행은 다음 SELECT 문을 실행하여 검색됩니다. 여기서 LIMIT 절은 2, 2 값과 함께 사용됩니다. 여기서 첫 번째 2는 0부터 계산을 시작하는 테이블 행의 시작 위치를 정의하고 두 번째 2는 시작 위치에서 계산을 시작하는 행의 수를 정의합니다.
선택하다 * 에서 서적 한계 2 , 2 ;이전 쿼리를 실행한 후 다음 출력이 나타납니다.

자동 증가된 기본 키 값을 기준으로 테이블을 내림차순으로 정렬하고 LIMIT 절을 사용하여 테이블 끝에서 레코드를 읽을 수 있습니다. 'books' 테이블에서 마지막 2개의 레코드를 읽는 다음 SELECT 문을 실행합니다. 여기에서 결과 집합은 'id' 필드를 기준으로 내림차순으로 정렬됩니다.
선택하다 * 에서 서적 주문하다 에 의해 ID 설명 한계 2 ;books 테이블의 마지막 두 레코드는 다음 출력에 표시됩니다.

부분 일치를 기반으로 테이블 읽기
LIKE 절은 '%' 기호와 함께 사용되어 부분 일치를 통해 테이블에서 레코드를 검색합니다. 다음 SELECT 문은 LIKE 절을 사용하여 값 시작 부분에 'John'이 포함된 작성자 필드가 있는 'books' 테이블에서 레코드를 검색합니다. 여기서 '%' 기호는 검색 문자열 끝에 사용됩니다.
선택하다 * 에서 서적 어디 작가 좋다 '남자%' ;저자 필드 값의 시작 부분에 'John' 문자열이 포함된 'books' 테이블에는 하나의 레코드만 존재합니다.

다음 SELECT 문은 LIKE 절을 사용하여 게시 필드 값 끝에 'Ltd'가 포함된 'books' 테이블에서 레코드를 검색합니다. 여기에서 '%' 기호는 검색 문자열의 시작 부분에 사용됩니다.
선택하다 * 에서 서적 어디 출판 좋다 '%주' ;출판 필드 끝에 'Ltd' 문자열이 포함된 'books' 테이블에는 하나의 레코드만 존재합니다.

다음 SELECT 문은 LIKE 절을 사용하여 제목 필드에 'Queries'가 포함된 'books' 테이블에서 레코드를 검색합니다. 여기에서 '%' 기호는 검색 문자열의 양쪽에 사용됩니다.
선택하다 * 에서 서적 어디 제목 좋다 '%쿼리%' ;제목 필드에 'Queries' 문자열을 포함하는 'books' 테이블에는 하나의 레코드만 존재합니다.

테이블의 특정 필드 합계 계산
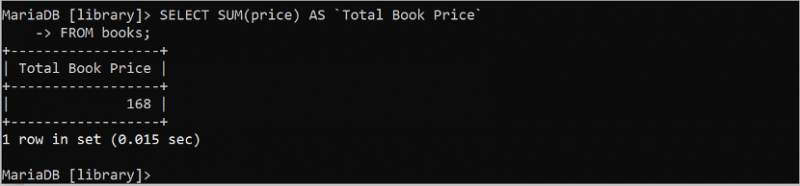
SUM()은 테이블의 숫자 필드 값의 합계를 계산하는 SQL의 또 다른 유용한 집계 함수입니다. 이 함수는 숫자여야 하는 하나의 인수를 사용합니다. 다음 SQL 문은 정수 값을 포함하는 'books' 테이블의 price 필드 값의 모든 값 합계를 계산합니다.
선택하다 합집합 ( 가격 ) 처럼 `총 도서 가격`에서 서적;
출력에는 'books' 테이블의 price 필드에 있는 모든 값의 합계 값이 표시됩니다. 가격 필드의 네 가지 값은 39, 49, 35, 45입니다. 이 값의 합계는 168입니다.
특정 필드의 최대값과 최소값 찾기
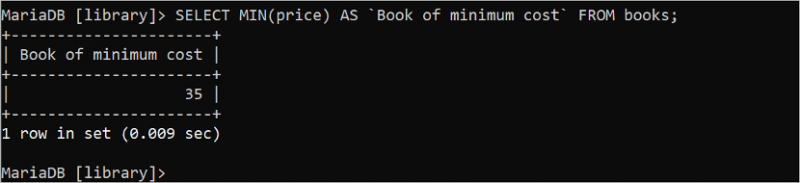
MIN() 및 MAX() 집계 함수는 테이블의 특정 필드의 최소값과 최대값을 찾는 데 사용됩니다. 두 함수 모두 숫자여야 하는 하나의 인수를 사용합니다. 다음 SQL 문은 정수인 'books' 테이블에서 최소 가격 값을 찾습니다.
선택하다 분 ( 가격 ) 처럼 '최소 비용의 책' 에서 서적;삼십오(35)는 출력에 인쇄되는 가격 필드의 최소값입니다.
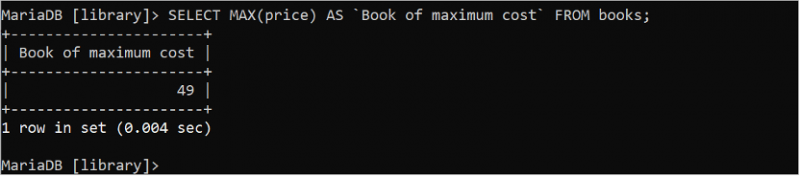
다음 SQL 문은 'books' 테이블에서 최대 가격 값을 찾습니다.
선택하다 MAX ( 가격 ) 처럼 '최대 비용의 책' 에서 서적;사십구(49)는 출력에 인쇄되는 가격 필드의 최대값입니다.
데이터 또는 필드의 특정 부분 읽기
SUBSTR() 함수는 SQL 문에서 문자열 데이터의 특정 부분 또는 테이블의 특정 필드 값을 검색하는 데 사용됩니다. 이 함수는 세 개의 인수를 포함합니다. 첫 번째 인수에는 문자열 값 또는 문자열인 테이블의 필드 값이 포함됩니다. 두 번째 인수는 첫 번째 인수에서 검색된 하위 문자열의 시작 위치를 포함하고 이 값의 계산은 1부터 시작합니다. 세 번째 인수는 시작 위치에서 계산을 시작하는 하위 문자열의 길이를 포함합니다.
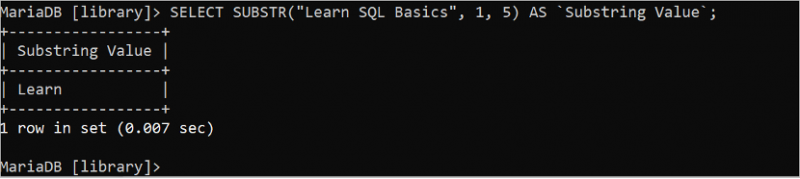
다음 SELECT 문은 'Learn SQL Basics' 문자열에서 시작 위치가 1이고 길이가 5인 처음 5자를 잘라서 인쇄합니다.
선택하다 SUBSTR ( 'SQL 기초 배우기' , 1 , 5 ) 처럼 `하위 문자열 값` ;'Learn SQL Basics' 문자열의 처음 5개 문자는 출력에 인쇄되는 'Learn'입니다.
다음 SELECT 문은 시작 위치가 7이고 길이가 3인 'Learn SQL Basics' 문자열에서 SQL을 잘라서 인쇄합니다.
선택하다 SUBSTR ( 'SQL 기초 배우기' , 7 , 삼 ) 처럼 `하위 문자열 값` ;이전 쿼리를 실행한 후 다음 출력이 나타납니다.

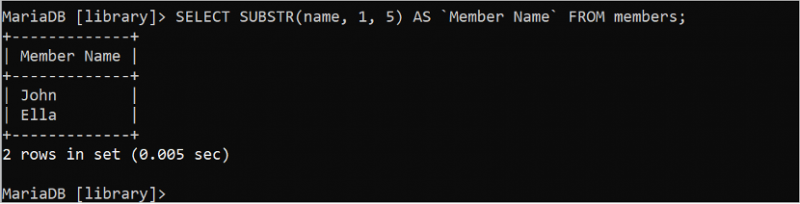
다음 SELECT 문은 '구성원' 테이블의 이름 필드에서 처음 5자를 잘라서 인쇄합니다.
선택하다 SUBSTR ( 이름 , 1 , 5 ) 처럼 `멤버 이름` 에서 회원;출력에는 '구성원' 테이블의 이름 필드에 있는 각 값의 처음 5자가 표시됩니다.
연결 후 테이블 데이터 읽기
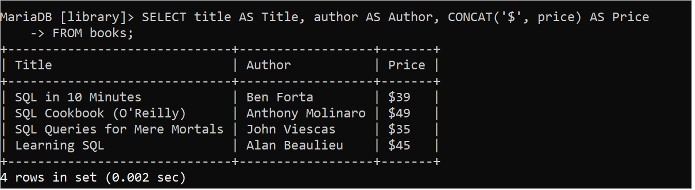
CONCAT() 함수는 테이블의 하나 이상의 필드를 결합하거나 문자열 데이터 또는 테이블의 특정 필드 값을 추가하여 출력을 생성하는 데 사용됩니다. 다음 SQL 문은 'books' 테이블의 제목, 저자 및 가격 필드 값을 읽고 CONCAT() 함수를 사용하여 가격 필드의 각 값에 '$' 문자열 값을 추가합니다.
선택하다 제목 처럼 제목 , 작가 처럼 작가 , 연결 ( '$' , 가격 ) 처럼 가격에서 서적;
가격 필드의 값은 '$' 문자열과 연결하여 출력에 인쇄됩니다.
다음 SQL 문을 실행하여 CONCAT() 함수를 사용하여 'books' 테이블의 제목 및 저자 필드 값을 'by' 문자열 값과 결합합니다.
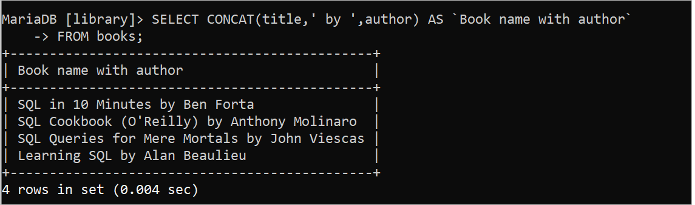
선택하다 연결 ( 제목 , ' 에 의해 ' , 작가 ) 처럼 `저자가 있는 책 이름`에서 서적;
이전 SELECT 쿼리를 실행한 후 다음 출력이 나타납니다.
수학 계산 후 테이블 데이터 읽기
SELECT 문을 사용하여 테이블의 값을 검색할 때 모든 수학적 계산을 수행할 수 있습니다. 5% 할인율을 계산한 후 다음 SQL 문을 실행하여 id, title, price, 할인가 값을 읽어옵니다.
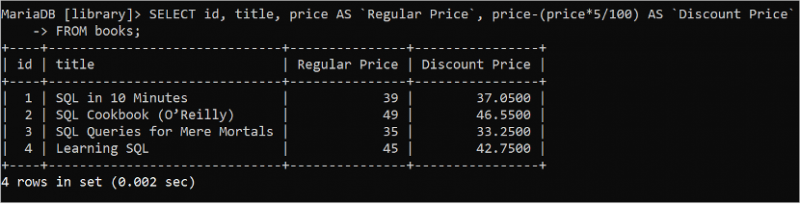
선택하다 ID , 제목 , 가격 처럼 '정상가' , 가격 - ( 가격 * 5 / 100 ) 처럼 '할인가격'에서 서적;
다음 출력은 각 책의 정상 가격과 할인 가격을 보여줍니다.
테이블 보기 생성
VIEW는 쿼리를 단순하게 만들고 데이터베이스에 추가 보안을 제공하는 데 사용됩니다. 하나 이상의 테이블에서 생성된 가상 테이블처럼 작동합니다. 'members' 테이블을 기반으로 간단한 VIEW를 생성하고 실행하는 방법은 다음 예제와 같습니다. VIEW는 SELECT 문을 사용하여 실행됩니다. 다음 SQL 문은 id, name, address 및 contact_no 필드가 있는 'members' 테이블의 VIEW를 생성합니다. SELECT 문은 member_view를 실행합니다.
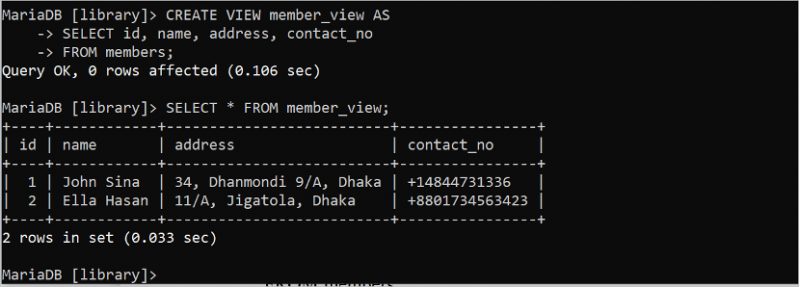
만들다 보다 member_view 처럼선택하다 ID , 이름 , 주소 , contact_no
에서 회원;
선택하다 * 에서 member_view;
보기를 만들고 실행하면 다음 출력이 나타납니다.
특정 조건에 따라 테이블 업데이트
UPDATE 문은 테이블의 내용을 업데이트하는 데 사용됩니다. WHERE 절 없이 UPDATE 쿼리를 실행하면 UPDATE 쿼리에 사용된 모든 필드가 업데이트됩니다. 따라서 적절한 WHERE 절과 함께 UPDATE 문을 사용해야 합니다. 다음 UPDATE 문을 실행하여 id 필드의 값이 1인 name 및 contact_no 필드를 업데이트합니다. 다음으로 SELECT 문을 실행하여 데이터가 제대로 업데이트되었는지 확인합니다.
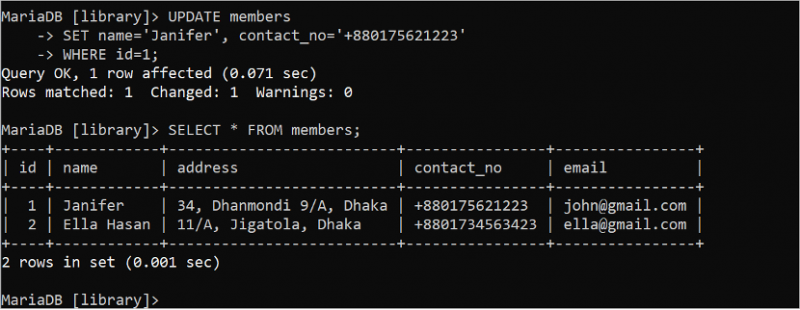
업데이트 회원세트 이름 = '제니퍼' , contact_no = '+880175621223'
어디 ID = 1 ;
선택하다 * 에서 회원;
다음 출력은 UPDATE 문이 성공적으로 실행되었음을 보여줍니다. UPDATE 쿼리를 사용하여 id 값이 1인 레코드의 name 필드 값이 'Janifer'로 변경되고 contact_no 필드가 '+880175621223'으로 변경됩니다.
특정 조건에 따라 테이블 데이터 삭제
DELETE 문은 테이블의 특정 내용 또는 모든 내용을 삭제하는 데 사용됩니다. WHERE 절 없이 DELETE 쿼리를 실행하면 모든 필드가 삭제됩니다. 따라서 적절한 WHERE 절과 함께 UPDATE 문을 사용해야 합니다. 다음 DELETE 문을 실행하여 id 값이 4인 books 테이블에서 모든 데이터를 삭제한다. 다음으로 SELECT 문을 실행하여 데이터가 제대로 삭제되었는지 확인한다.
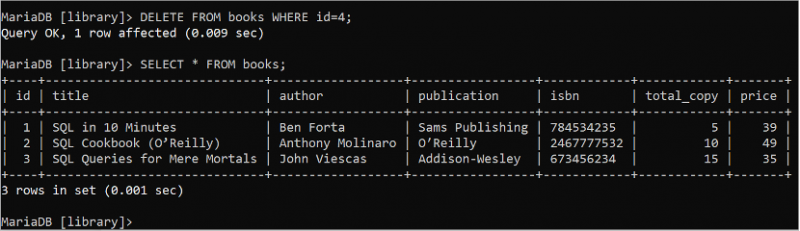
삭제 에서 서적 어디 ID = 4 ;선택하다 * 에서 서적;
다음 출력은 DELETE 문이 성공적으로 실행되었음을 보여줍니다. 4 일 books 테이블의 레코드는 DELETE 쿼리를 사용하여 제거됩니다.
테이블에서 모든 레코드 삭제
다음 DELETE 문을 실행하여 'books' 테이블에서 WHERE 절이 생략된 모든 레코드를 삭제합니다. 다음으로 SELECT 쿼리를 실행하여 테이블 내용을 확인합니다.
삭제 에서 book_borrow_info;선택하다 * 에서 book_borrow_info;
다음 출력은 DELETE 쿼리를 실행한 후 'books' 테이블이 비어 있음을 보여줍니다.

테이블에 자동 증가 속성이 포함되어 있고 테이블에서 모든 레코드가 삭제된 경우 테이블을 비운 후 새 레코드가 삽입되면 자동 증가 필드는 마지막 증가부터 계산을 시작합니다. 이 문제는 TRUNCATE 문을 사용하여 해결할 수 있습니다. 또한 테이블에서 모든 레코드를 삭제하는 데 사용되지만 자동 증가 필드는 테이블에서 모든 레코드를 삭제한 후 1부터 계산하기 시작합니다. TRUNCATE 문의 SQL은 다음과 같습니다.
자르기 book_borrow_info;테이블을 드롭
테이블의 존재 여부를 확인하거나 확인하지 않고 하나 이상의 테이블을 삭제할 수 있습니다. 다음 DROP 문은 “book_borrow_info” 테이블을 삭제하고 “SHOW tables” 문은 테이블이 서버에 존재하는지 여부를 확인합니다.
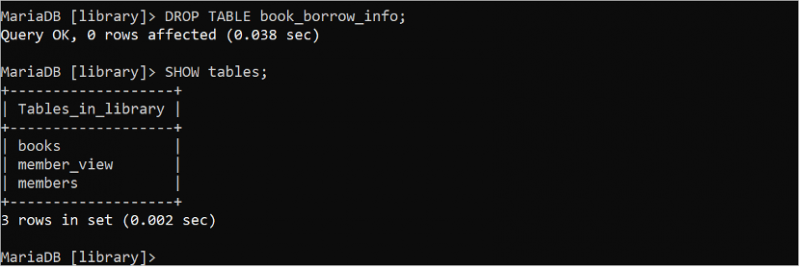
떨어지다 테이블 book_borrow_info;보여주다 테이블 ;
출력에는 'book_borrow_info' 테이블이 삭제된 것으로 표시됩니다.
서버에 존재 여부를 확인한 후 테이블을 삭제할 수 있습니다. 서버에 이러한 테이블이 있는 경우 다음 DROP 문을 실행하여 books 및 구성원 테이블을 삭제합니다. 다음으로 'SHOW tables' 문은 테이블이 서버에 존재하는지 여부를 확인합니다.
떨어지다 테이블 만약에 존재한다 서적 , 회원;보여주다 테이블 ;
다음 출력은 테이블이 서버에서 삭제되었음을 보여줍니다.

데이터베이스 삭제
다음 SQL 문을 실행하여 서버에서 '라이브러리' 데이터베이스를 삭제합니다.
떨어지다 데이터 베이스 도서관;출력은 데이터베이스가 삭제되었음을 보여줍니다.

결론
MariaDB 서버의 데이터베이스를 생성, 액세스, 수정 및 삭제하기 위해 주로 사용되는 SQL 쿼리 예제는 이 자습서에서 데이터베이스와 세 개의 테이블을 생성하여 표시됩니다. 새로운 데이터베이스 사용자가 SQL 기본 사항을 제대로 배울 수 있도록 다양한 SQL 문의 사용을 매우 간단한 예를 통해 설명합니다. 복잡한 쿼리의 사용은 여기에서 생략됩니다. 새 데이터베이스 사용자는 이 자습서를 제대로 읽은 후 모든 데이터베이스 작업을 시작할 수 있습니다.